The Memo.
Alan D. Thompson
December 2022
Background and context
In 2018, I was run off my feet providing advisory in the field of human intelligence. I was in my second term as Chairman for Mensa International’s gifted families committee, had a full client roster of prodigies and gifted children through coaching via Harvard Medical School, consulted regularly to Dara (Australia’s only gifted school), spent time with the team at Ad Astra (Elon Musk’s gifted school), published my book Bright, worked with the Australian Prime Minister on providing acceleration for gifted families, and was one of the ‘go to’ talking heads for intelligence in the media.
That year, while consulting to Warner Bros. for a major television series on gifted children, they brought me an additional challenge. Given a large cohort of a few hundred students, I was to facilitate IQ testing on all of them during half-day auditions in Sydney and Melbourne.
This was not an easy feat. A formal IQ assessment must be conducted one-on-one by a registered psychologist. Testing usually takes several hours. If the child is younger, the testing must be split up into two or three sessions, sometimes across multiple days. Possibly even more importantly, the cost of running either of the standard testing instruments—the Stanford-Binet or the Wechsler suite—sits at around $1,000 each. With deep pockets, even Warner Bros. balked at spending half a million dollars to test 500 children!
The solution I recommended was to leverage a written instrument that was ‘culture fair’, particularly important for Australian children representing several nations.
There were a few options available. One was a popular visual analogy problem set which measures fluid intelligence. That test is called Raven’s Progressive Matrices (RPM). It was developed by John Carlyle Raven for ages 6-80 (and has since been expanded by Pearson for ages 4-90). RPM measures a person’s ability to understand perceptual (visual) relations, and to reason by analogy. The test provides a final score comparing the candidate’s general ability or intelligence with others in the same age population. While not really a ‘full’ IQ test, the layout of RPM has been integrated into the ‘gold standard’ tests like the Stanford-Binet and Wechsler suites.
Running the RPM on audition days across groups of Australian gifted children in ‘exam rooms’, the results were so impressive that I sent a letter to the Executive Producer at Warner Bros. (2018).
I wanted to draw your attention to the significance of the… IQs of children tested so far in Sydney… Due to the rarity of exceptionally gifted children, and the difficulty in finding them, this project may indeed be internationally significant. There have been a handful of studies in the last 100 years that have striven to find such a large population of exceptionally gifted children. Two of these are highlighted below:
- Professor Miraca Gross looked all across Australia in the 1980s and 1990s and originally found only 15 children with an IQ above 160.
- Professor Leta Hollingworth searched for children all across the USA in the 1920s and found only 12 children with an IQ above 180..
…The majority of contestants [from our Sydney and Melbourne auditions] are in the top zero point one per cent (0.1%) of the population in terms of IQ. This is one of the largest single groups of highly gifted and exceptionally gifted children in the world.
With the release of OpenAI’s GPT-3 just two years after sending that letter, I left the field of human intelligence to focus on the flourishing field of artificial intelligence, and its ability to augment our own smarts.
Solving Raven’s Progressive Matrices as a Human
Completing the Raven’s Progressive Matrices involves looking at a pattern and finding the final symbol. Given the following (easy) example, out of the multiple choice options 1-6, how would you complete the matrix?

As the candidate works through the test, the problems become much more difficult. Consider this example with 8 multiple choice options from which to choose:
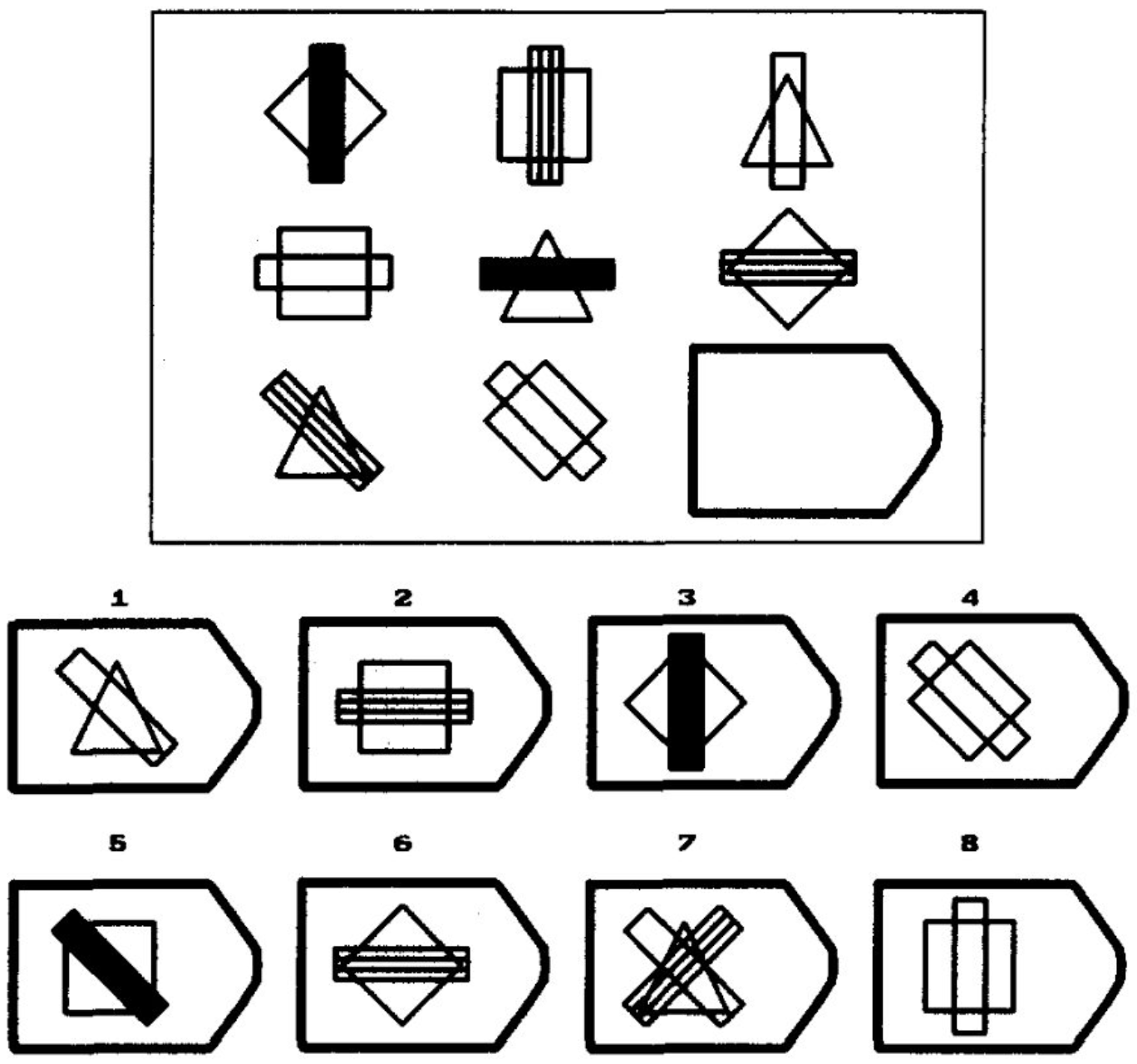
Not so easy now, and they get even harder!
Solving Raven’s Progressive Matrices as a Large Language Model
In 2022, Visual Language Models (VLMs), and Vision Transformers (ViTs) like the popular OpenAI CLIP and the high-performance DeepMind Flamingo could ‘see’ these symbols and at least attempt to solve the problem.
We’ve seen that in 2022, large language models are far ‘smarter’ than VLMs, but they can’t really ‘see’ anything except text. So, how would we convert the complex pattern of symbols above into something that a language model can solve?
In 2021, I approached Dr Gail Byrne in Australia, and the renowned Dr Steven Pfeiffer at FSU in America to see what we could create, but the visual limitations presented a real challenge.
The solution was brought to light in December 2022 by a team of psychologists at UCLA. Converting the example above to digits looks like this:
[ 5 9 3 ] [ 8 9 2 ] [ 1 9 7 ] [ 8 4 7 ] [ 1 4 3 ] [ 5 4 2 ] [ 1 2 2 ] [ 5 2 7 ] [ ? ] 1: [ 5 2 3 ] 2: [ 5 4 2 ] 3: [ 1 2 7 ] 4: [ 8 9 7 ] 5: [ 5 9 3 ] 6: [ 1 4 3 ] 7: [ 8 2 3 ] 8: [ 5 2 7 ]
Can you solve it? (All solutions at the end of this article.)
The latest version of OpenAI’s GPT-3 can! And, it does so without any specific training or prompt examples, and in less than a second.
The UCLA team had also worked very quickly. They used the text-davinci-003 model, released 28/Nov/2022, and published their paper to the arXiv.org e-Print archive within about 20 days.
Their findings were earth-shattering, noting that GPT-3.5 blows GPT-3 davinci’s performance out of the water. Keep in mind that in May/2020, GPT-3 davinci was already scoring 15% higher than an average college applicant on analogy questions from the SAT.
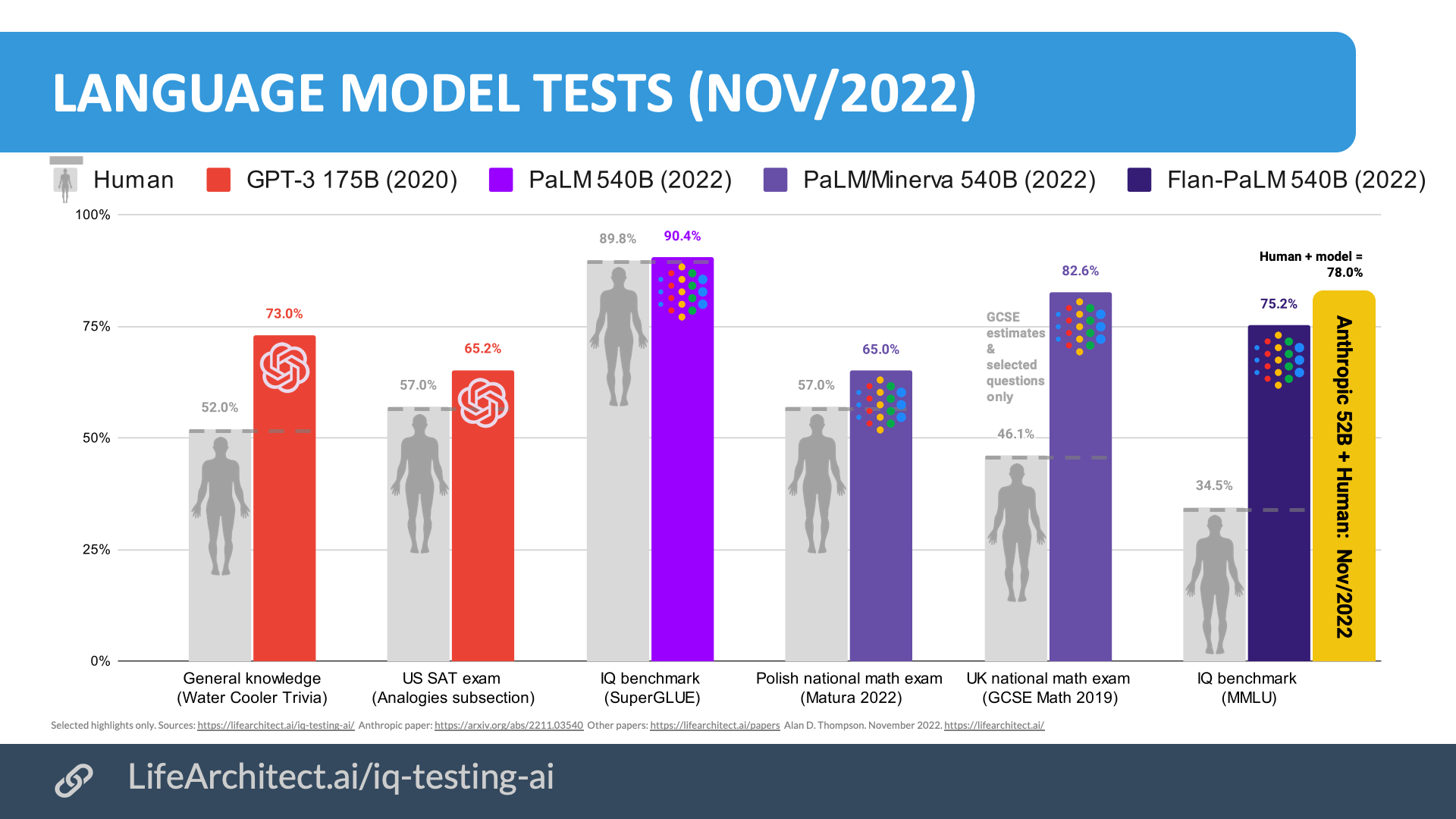
Two and a half years later, GPT-3.5’s instruction-tuned engine allowed even greater advances.
Here are some extracts from the paper (19/Dec/2022):
[text-davinci-003] displayed a surprisingly strong capacity for abstract pattern induction, matching or even surpassing human capabilities in most settings… [text-davinci-003] achieves the analogical capacity that is often considered the core of human intelligence… [text-davinci-003] has been forced to develop mechanisms similar to those thought to underlie human analogical reasoning – despite not being explicitly trained to do so… through a radically different route than that taken by biological intelligence.
The lead author, Dr Taylor Webb, added further insights:
[text-davinci-003] outperformed human participants both when generating answers from scratch, and when selecting from a set of answer choices. Note that this is without *any* training on this task. [text-davinci-003] also displayed several qualitative effects that were consistent with known features of human analogical reasoning. For instance, it had an easier time solving logic problems when the corresponding elements were spatially aligned.
He noted that, while the older GPT-3 davinci ‘performed very poorly’ on some problems, ‘the newest iteration of GPT-3 performs much better’. And this ‘better’ is compared to college (university) students, who have previously been found to have above-average IQs, perhaps in the top 10% of their age population in terms of intelligence.
‘GPT-3 outperformed human participants on all problem types, both in terms of generative accuracy… and multiple-choice accuracy’
The results look particularly jarring, with GPT-3.5 in purple, and humans in light blue:
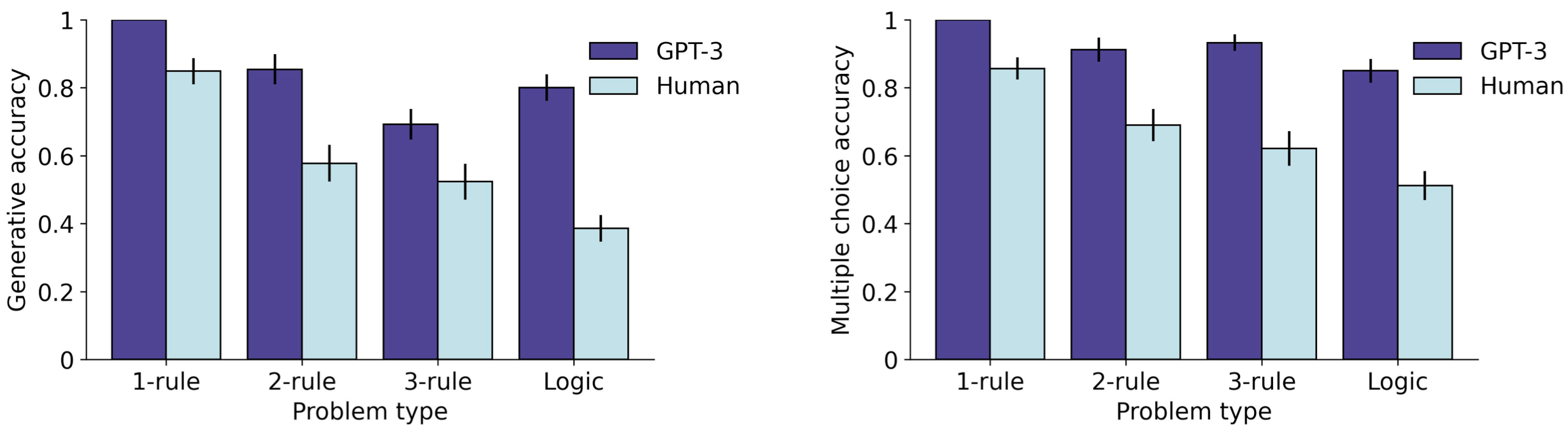
If a student scores ~38% in logic, while GPT-3.5 scores ~80%, does this mean that GPT-3.5 has an IQ score far above 120, equivalent to the 90th percentile?
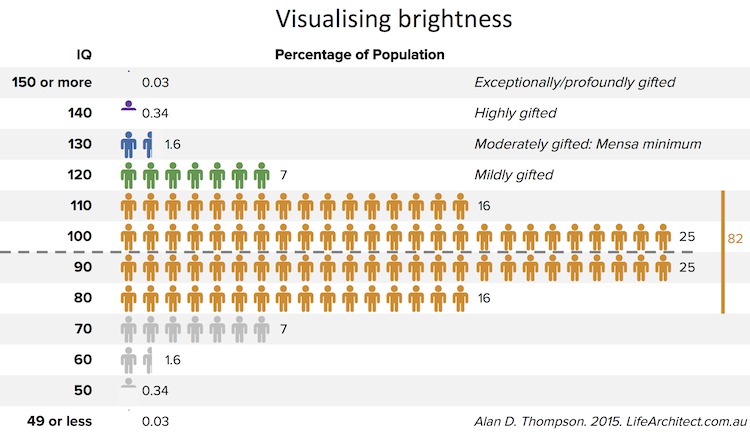
I’ve previously gone on record to estimate that (across relevant subtests) the older GPT-3 davinci would easily beat a human in the 99.9th percentile (FSIQ=150), and I definitely stand by that assertion.
Would GPT-3.5’s IQ be even higher? Are we breaking all benchmark ceilings already?
[Update Jan/2023: ChatGPT had an IQ of 147 on a Verbal-Linguistic IQ Test. This would place it in the 99.9th percentile.]
The bottom line is that even without specific training, large language models like Google PaLM, DeepMind Chinchilla, and in this case, the GPT-3 family, have been outperforming humans for several years.
It is vital that humanity is prepared for the integration of artificial intelligence with our biological intelligence; supporting our evolution, and working alongside us in this transformation of our capabilities.
And, as I have since 20201https://lifearchitect.ai/fire-alarm/2https://lifearchitect.ai/outperforming-humans/, I once again call on intergovernmental organizations to step up and prepare the population for this historical advance; a change even more profound than the discovery of fire, the harnessing of electricity, or the birth of the Internet.
Update Feb/2023 #
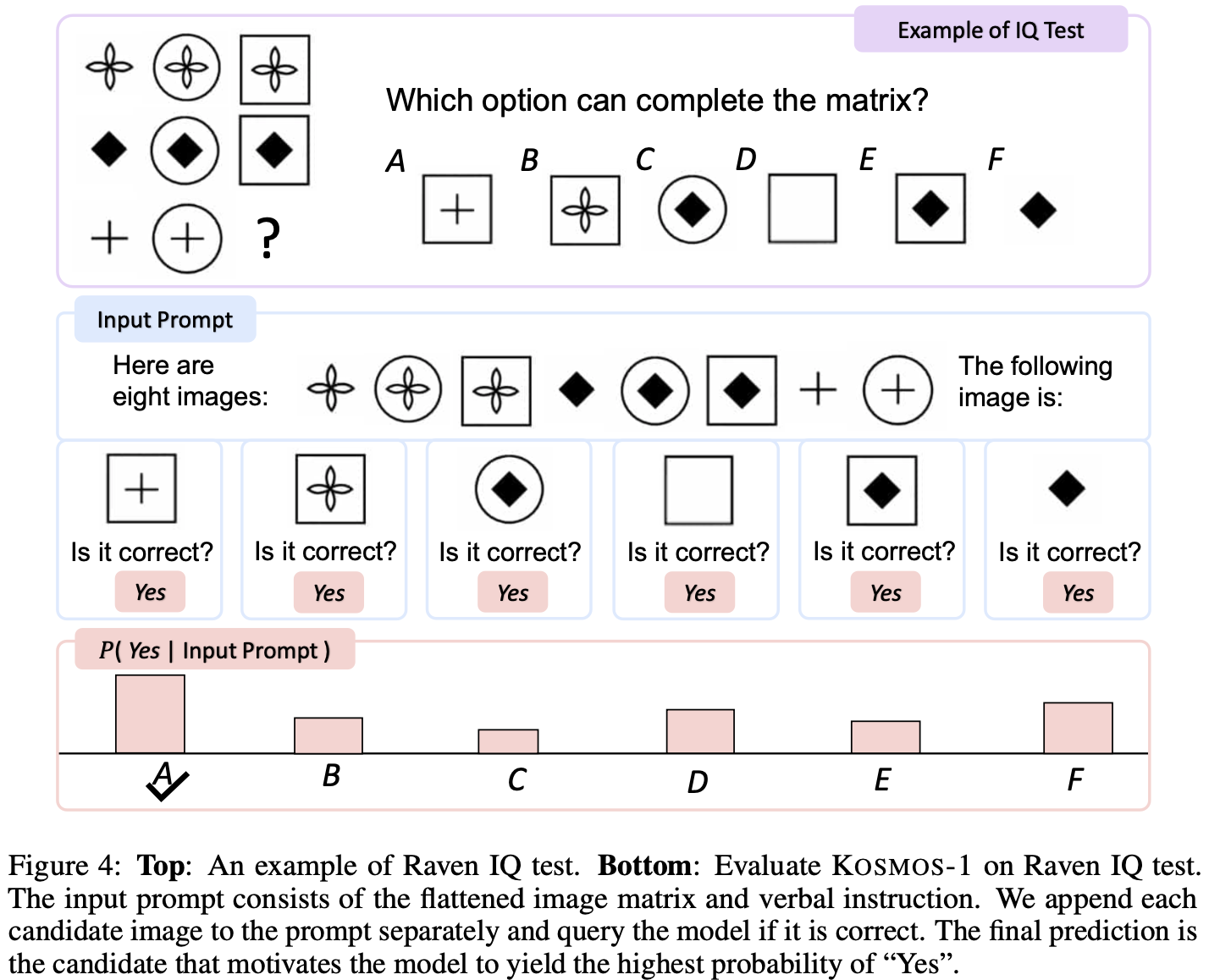
Microsoft Kosmos-1 1.6B (paper) is a multimodal large language model (MLLM) that is capable of perceiving multimodal input, following instructions, and performing in-context learning for not only language tasks but also multimodal tasks.
They expanded the testing to allow the model to see (similar to VLMs like DeepMind Flamingo) the flattened Raven’s Progressive Matrices. Example below:
Header image generated by Alan D. Thompson via DALL-E 2 on 26/Dec/2022. Prompt: ‘iq test progressive matrices’.
Solutions
The first ‘easy’ one (symbols): Option 2, based on the dots in the corners.
The second ‘hard’ one (symbols): Option 5, based on placement of shapes (check the diagonal movement).
The third ‘hard’ one (numbers/digits only): Option 7 [ 8 2 3 ], this one is too hard for me right now.
Get The Memo
by Dr Alan D. Thompson · Be inside the lightning-fast AI revolution.Informs research at Apple, Google, Microsoft · Bestseller in 152 countries.
Artificial intelligence that matters, as it happens, in plain English.
Get The Memo.
 Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.
Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.This page last updated: 22/May/2025. https://lifearchitect.ai/ravens/↑
- 1
- 2

