
Important: This page summarizes data scaling only, using tokens to parameters as a ratio, and as derived from large language models like GPT-3, Chinchilla, and beyond, linked to the Compute-Optimal scaling laws like Kaplan and Hoffmann/Chinchilla. Please note that compute scaling laws are outside the scope of my current focus. If you would like to read more about compute-optimal scaling laws, please see the discussion by Microsoft + MIT: ‘Reconciling Kaplan and Chinchilla Scaling Laws’ 12/Jun/2024: https://arxiv.org/abs/2406.12907
Alan D. Thompson
February 2023, updated 2024, 2025, 2026
-
- Chinchilla viz
- Chinchilla vs Kaplan scaling laws
- Mosaic scaling laws ≈ range, 190:1 (Dec/2023)
- DeepSeek scaling laws ≈ range, 30:1 (Jan/2024)
- UoW MoE scaling laws, decreasing to 8:1 (Feb/2024)
- Tsinghua scaling laws = 192:1 (Apr/2024)
- Epoch replication of Chinchilla = 26:1 (Apr/2024)
- Llama 3 scaling laws = 1,875:1 (Apr/2024)
- 2024 update
- 2025 update
- 2026 update
- DeepMind models to Gemini
Chinchilla viz (2022)
The original 2022 version of this viz is featured in the paper ‘Current Best Practices for Training LLMs from Scratch’, Weights & Biases (as used by OpenAI).
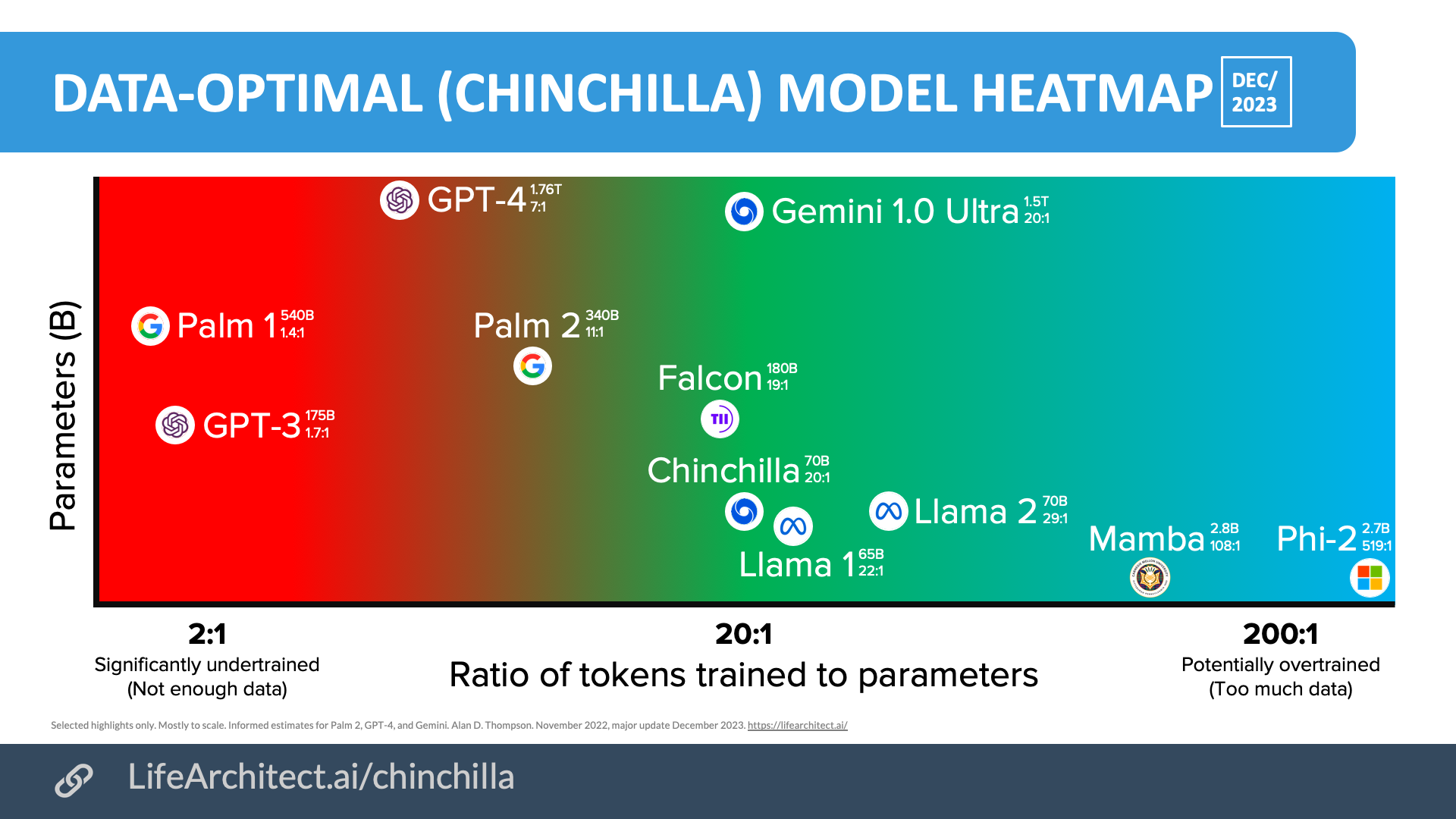 Download source (PDF)
Download source (PDF)
Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Data ratio viz (2026)
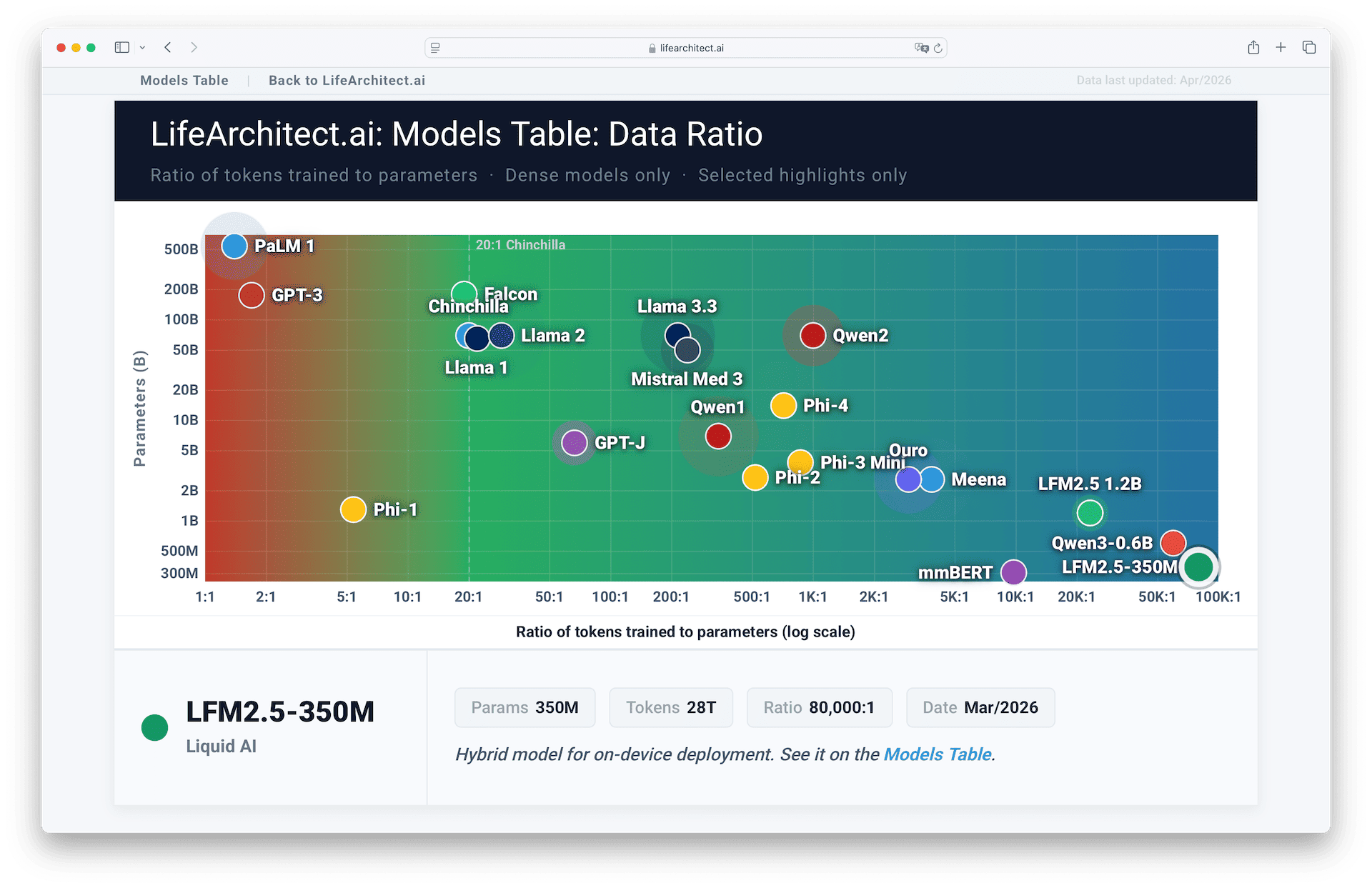
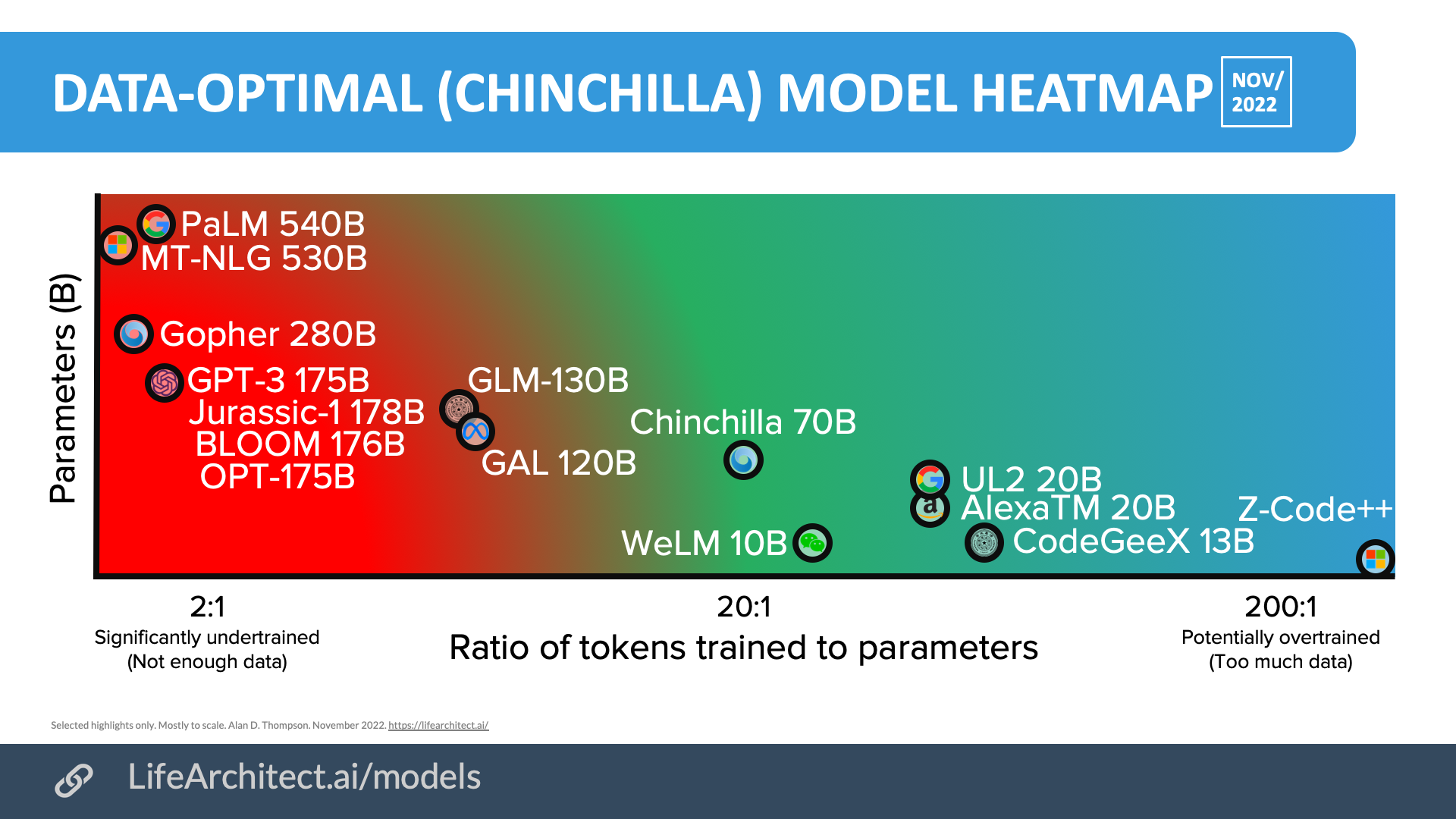
Table of current models showing tokens:parameters ratio
Models Table
View the full dataChinchilla vs Kaplan scaling laws
Summary: For a fixed compute budget, Chinchilla showed that we need to be using 11× more data during training than that used for GPT-3 and similar models. This means that we need to source, clean, and filter to around 33TB of text data for a 1T-parameter model.
How much text data should we use when training a text-based large language model (LLM)?
Over the last three years to 2023, there have been a few discoveries, through a process of trial and error…
(Note: There is a complementary scaling law for compute built in to these findings, but this is outside the scope of my current focus.)
In May/2020, OpenAI (GPT-3 paper) tacitly announced their data scaling laws (also called the Kaplan scaling laws) for LLMs:
In plain English, GPT-3/Kaplan scaling laws said that…
300B tokens can be used to train an LLM of size 175B parameters
So, we need around 1.7 text tokens per parameter
In Sep/2022, DeepMind (Chinchilla paper) found new data scaling laws (also called the Chinchilla or Hoffmann scaling laws) for ‘data optimal’ LLMs:
In plain English, Chinchilla/Hoffmann scaling laws say that…
1,400B (1.4T) tokens should be used to train a data-optimal LLM of size 70B parameters
So, we need around 20 text tokens per parameter
Therefore, to make GPT-3 data optimal, and…
Keeping the original 300B tokens, GPT-3 should have been only 15B parameters (300B tokens ÷ 20).
This is around 11× smaller in terms of model size.OR
To get to the original 175B parameters, GPT-3 should have used 3,500B (3.5T) tokens (175B parameters x 20. 3.5T tokens is about 4-6TB of data, depending on tokenization and tokens per byte).
This is around 11× larger in terms of data needed.
The data optimization scale continues for model sizes measured in trillions of parameters, and training data measured in quadrillions of text tokens or petabytes of text data. The table and explanation below originally appeared in the Jun/2022 report, The sky is bigger than we imagine.
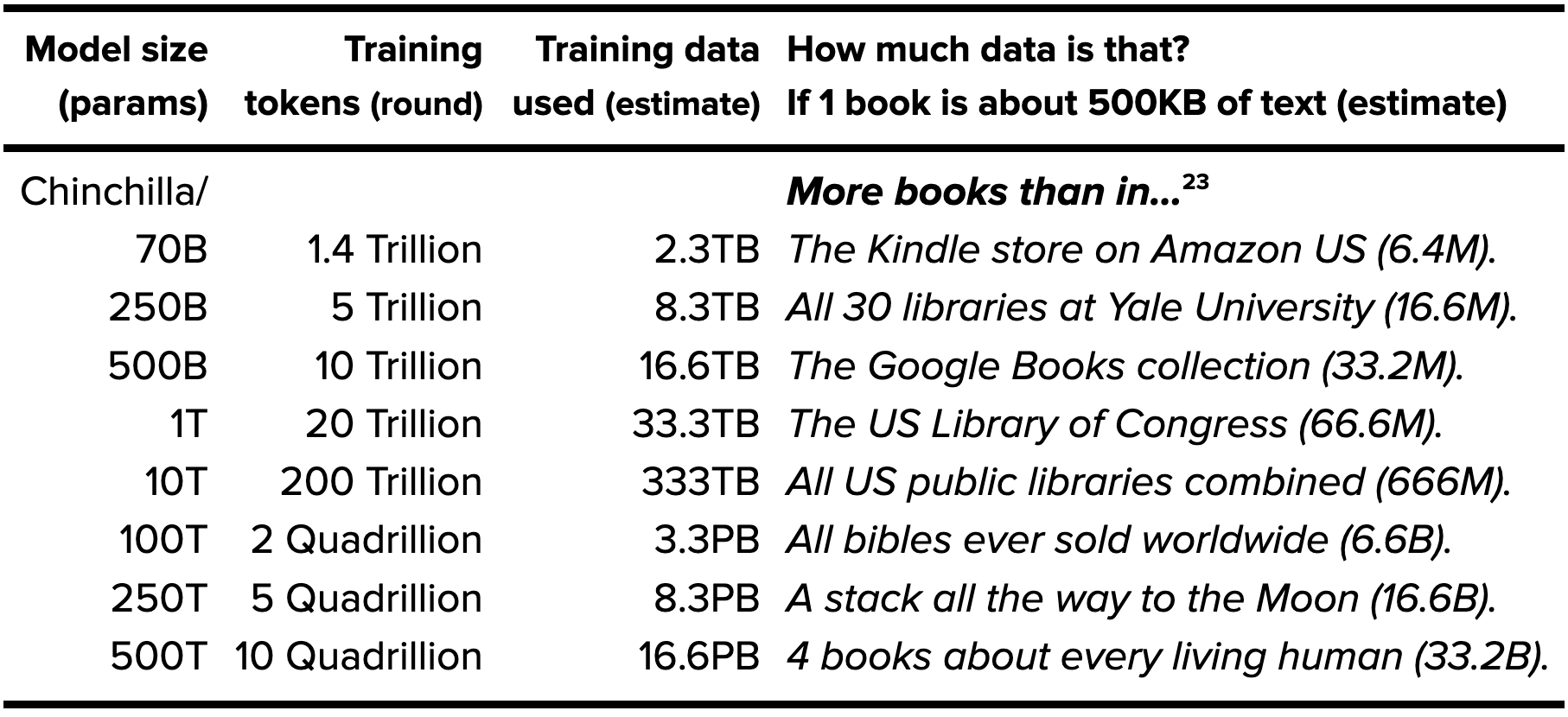
Text for indexing
| Model size (params) |
Training tokens (round) |
Training data used (estimate) |
How much data is that? If 1 book is about 500KB of text (estimate) |
|---|---|---|---|
| Chinchilla/ 70B |
1.4 Trillion | 2.3TB | More books than in… The Kindle store on Amazon US (6.4M). |
| 250B | 5 Trillion | 8.3TB | All 30 libraries at Yale University (16.6M). |
| 500B | 10 Trillion | 16.6TB | The Google Books collection (33.2M). |
| 1T | 20 Trillion | 33.3TB | The US Library of Congress (66.6M). |
| 10T | 200 Trillion | 333TB | All US public libraries combined (666M). |
| 100T | 2 Quadrillion | 3.3PB | All bibles ever sold worldwide (6.6B). |
| 250T | 5 Quadrillion | 8.3PB | A stack all the way to the Moon (16.6B). |
| 500T | 10 Quadrillion | 16.6PB | 4 books about every living human (33.2B). |
Note: Text estimates1Kindle ≈ 6M books (estimate) https://justpublishingadvice.com/how-many-kindle-ebooks-are-there
Yale ≈ 15M items https://yaledailynews.com/blog/2018/04/06/stange-love-your-library
Google Books ≈ 25M books https://archive.ph/rMbE2
US Library of Congress ≈ 51M cataloged books https://www.loc.gov/about/general-information/#year-at-a-glance
British Library ≈ 170M items https://www.bl.uk/about-us/our-story/facts-and-figures-of-the-british-library
US public libraries ≈ 732M books, note that this definitely includes (many) duplicates https://nces.ed.gov/programs/digest/d17/tables/dt17_701.60.asp
Bibles ≈ 5B copies https://www.guinnessworldrecords.com/world-records/best-selling-book-of-non-fiction
Earth to Moon ≈ 384,400km≈ 38,440,000,000cm, each book spine 2.4cm thick ≈ 16B books
Human population ≈ 8B (Jun/2022) only, multimodal data not shown. Jun/2022. LifeArchitect.ai
There are a few caveats to my approximate numbers in the table above. Firstly, the ‘More books than in…’ examples are provided for text-based book data only (no pictures), and this assumes that books are about 500KB each without images2500KB ≈ 500K characters ≈ 75K words ≈ 300 pages per book. Simplified and rounded for easy figures.. We are now of course exploring training AI with multimodal data: images, music, control signals (robots, button presses), and anything else we can get our hands on. These increasing sizes are also using simplified and rounded estimates only, based on the new findings related to model scaling using more data (measured by number of tokens, which are roughly equivalent to words).
In 2010, Google estimated that there are only 130M unique published books in existence3https://googleblog.blogspot.com/2010/08/you-can-count-number-of-books-in-world.html, so past 1T parameters (20T tokens), training data collection would naturally have to rely on alternative text-based and multimodal content. At brain-scale parameter counts of 500T (10Q tokens), the estimated book count would be over 250 times the number of books published, or more than four new books written about each living human on Earth!
Fundamentally, it should not be an incredibly onerous process to collect petabytes of high-quality and filtered multimodal data (converted to text), though that task has not yet been accomplished by any AI lab to date (Jun/2022).
It is expected that 2023 large language models will continue to follow the Chinchilla scaling laws, though there will be new discoveries about data optimization and data use during training. For example, there is some research on whether or not data can ‘repeat’ (be seen more than once) during training, which may help alleviate the amount of data required to be sourced.
Mosaic scaling laws ≈ range with center of 190:1 (Dec/2023)
MosaicML: Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws
Training is a once-off process where an AI model is fed with a lot of data to recognize patterns and make connections. Large models use a lot of compute during training over many months, but they only have to do so once.
Inference occurs after the model has finished training, every time a user asks the AI model a question (prompt) to produce an output (response).
For inference, popular models might generate trillions and soon quadrillions of words for millions of users over the model’s lifetime (GPT-3 was generating 4.5 billion words per day back in Mar/2021, and then in Dec/2022 I estimated ChatGPT’s output @ 45 billion words per day, or around 18 trillion words since launch), using a lot of compute at all times.
Accounting for both training and inference, how does one minimize the cost required to produce and serve a high quality model?
We conduct our analysis both in terms of a compute budget and real-world costs and find that LLM researchers expecting reasonably large inference demand (~1B requests) should train models smaller and longer than Chinchilla-optimal.
With a fixed compute budget—and for no real-world users because it was locked in a lab!—Chinchilla would train a 70B model for 1.4T tokens (20:1) and also lists a 70B model for 4.26T tokens (61:1).
Mosaic’s proposal would train a popular/inference-intensive 41.6B model for 7,920B tokens (190:1).
At its most basic, Mosaic is attempting to minimize the cost of serving a model. While we can be certain that OpenAI trained, optimized, and deployed the original ChatGPT (gpt-3.5-turbo) 20B model as efficiently as possible to serve more than 200 million people (most of them free users), the world was not yet accustomed to AI copilots, let alone paying for AI inference.
Consider the major frontier models, and the pricing for inference of one million tokens. This is around 750,000 words, which is about how much we speak every 46 days (2007), or most of the seven Harry Potter books (2017):

Pricing per 1M tokens as of Dec/2023. CMU Gemini paper, p3, Table 2.
Evolutions of the original Kaplan (GPT-3) and Chinchilla scaling laws are expected and welcomed. I’m interested to see how this significant increase in training data—an unspoken conclusion of the Mosaic paper—will develop in the real world.
Read the paper: https://arxiv.org/abs/2401.00448
The largest datasets are listed in my Datasets Table: https://lifearchitect.ai/datasets-table/
DeepSeek scaling laws ≈ range with center of 30:1 (Jan/2024)
We attempted to fit the scaling curve on various datasets and found that the data quality significantly influences the optimal model/data scaling up allocation strategy. The higher the data quality, the more the increased compute budget should be allocated to model scaling. This implies that high-quality data can drive the training of larger models given the same data scale. The differences in the optimal model/data scaling-up allocation strategy may also serve as an indirect approach to assess the quality of data.
Read the paper: https://arxiv.org/abs/2401.02954
Tsinghua scaling laws = 192:1 (Apr/2024)
Tsinghua University: MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
[Our] scaling law indicates a much higher data size / model size ratio compared with Chinchilla Optimal… we notice that [Chinchilla’s] scaling experiment was conducted in a not very recent configuration.Specifically, the data size should be 192 times larger than the model size on average, as opposed to 20 times in Hoffmann et al. (2022).
Read the paper: https://arxiv.org/abs/2404.06395
Epoch replication of Chinchilla = 26:1 (Apr/2024)
Epoch AI: Chinchilla Scaling: A replication attempt
Optimal scaling. We find a range consistent with the 20 tokens per parameter rule of thumb. Indeed, our point estimates imply that 25.6 tokens per parameters is optimal.
Read the paper: https://www.arxiv.org/abs/2404.10102
Llama 3 scaling law = 1,875:1 (Apr/2024)
Scaling Laws for Fine-Grained Mixture of Experts
Meta mentions that even at this point [1,875:1], the model doesn’t seem to be “converging” in a standard sense. In other words, the LLMs we work with all the time are significantly undertrained by a factor of maybe 100-1000X or more, nowhere near their point of convergence. (18/Apr/2024)
Read the paper: https://arxiv.org/abs/2407.21783
University of Warsaw MoE scaling law = 8:1 (Feb/2024)
For mixture-of-experts models, this paper suggests that the optimal ratio actually decreases as model size increases, rather than staying constant or increasing. This is different from some previous assumptions about scaling laws. It shows smaller MoE models benefit from relatively more training tokens compared to their parameter count, while larger MoE models need proportionally fewer tokens.
| Active Params (N) | Total Params | Training Tokens (D) | G | FLOPs | Loss | Tokens:Active Params | Tokens:Total Params |
|---|---|---|---|---|---|---|---|
| 64 x 100M | 6.4B | 4.37B | 8 | 2.95e+18 | 3.133 | 44:1 | 0.68:1 |
| 64 x 1B | 64B | 28.94B | 16 | 1.93e+20 | 2.491 | 29:1 | 0.45:1 |
| 64 x 3B | 192B | 72.90B | 16 | 1.41e+21 | 2.245 | 24:1 | 0.38:1 |
| 64 x 7B | 448B | 137.60B | 32 | 6.46e+21 | 2.076 | 20:1 | 0.31:1 |
| 64 x 70B | 4.48T | 941.07B | 32 | 4.16e+23 | 1.694 | 13:1 | 0.21:1 |
| 64 x 300B | 19.2T | 2.96T | 64 | 5.69e+24 | 1.503 | 10:1 | 0.15:1 |
| 64 x 1T | 64T | 7.94T | 64 | 4.97e+25 | 1.367 | 8:1 | 0.12:1 |
p10: Table 2: Compute optimal training hyper-parameters for MoE models. Optimal N (active params) and D (tokens) follow approximately similar relation to these of Hoffmann et al. (2022) for active parameters around the range of 1B to 10B parameters, requiring comparably longer training for smaller models and shorter for bigger ones. Higher granularity is optimal for larger compute budgets. Total params + ratio columns added by LifeArchitect.ai
Read the paper: https://arxiv.org/abs/2402.07871
2024 update
| Date | Scaling law | Paper | Ratio | Model example | Notes |
| May/2020 | Kaplan (OpenAI, GPT-3) | Paper | 1.7:1 | GPT-3 | 2020 law now widely regarded as not enough data |
| Sep/2022 | Chinchilla (Hoffmann, DeepMind) | Paper | 20:1 | Chinchilla | 2022 law now being exceeded in 2024 |
| Dec/2023 | Mosaic | Paper | range, 190:1 | MPT | MPT models actually released Apr/2023 at 154:1 and 143:1 |
| Jan/2024 | DeepSeek | Paper | range, 30:1 | DeepSeek 67B | Use high-quality data and lower ratio |
| Feb/2024 | University of Warsaw MoE | Paper | range, 8:1 | 1T MoE | Larger MoE models need proportionally fewer tokens, from 44:1 to 8:1 |
| Apr/2024 | Tsinghua | Paper | 192:1 | MiniCPM | |
| Apr/2024 | Epoch Chinchilla replication | Paper | 26:1 | – | |
| Apr/2024 | Llama 3 | Paper | 1,875:1 | Llama 3 | Karpathy: ‘[2023-2024 LLMs] are significantly undertrained by a factor of maybe 100-1000X or more’. |
| Jun/2024 | Microsoft + MIT discussion | Paper | Microsoft Research and MIT findings on compute |
View all model tokens:parameters ratios on the Models Table: https://lifearchitect.ai/models-table/
Based on the papers above—particularly 2024 work by Mosaic and Tsinghua—in plain English, and possibly oversimplified:
For the best performance, and at 2024 median model sizes and training budgets, if a large language model used to read 20M books during training, then it should instead read more than 190M books (or 40M books five times!).
Working, assume a 100B parameter model:
Chinchilla: 20M books × 75K words = 1.5T words or 2T tokens
Mosaic/Tsinghua: 190M books × 75K words = 14.25T words or 19T tokens
2025 update
In Apr/2025, Qwen3-0.6B, a new compact model from Alibaba’s Qwen3 family, set a new record with its impressive tokens-to-params ratio of 60,000:1, managing 600 million parameters trained on 36 trillion tokens of text data. As of 2025, the data ratio for Qwen3-0.6B is the highest ever seen on my Models Table for text models going back to the original Transformer in 2017.
2026 update
In Apr/2026, Liquid AI’s LFM2.5-350M set a new record data-to-parameter ratio of 80,000:1, training a 350M parameter model on 28 trillion tokens with large-scale reinforcement learning. The previous public data ratio record was set a year earlier in Apr/2025 by Alibaba with Qwen3-0.6B on 36T tokens at a ratio of 60,000:1. See it on the Models Table.
All dataset reports by LifeArchitect.ai (most recent at top)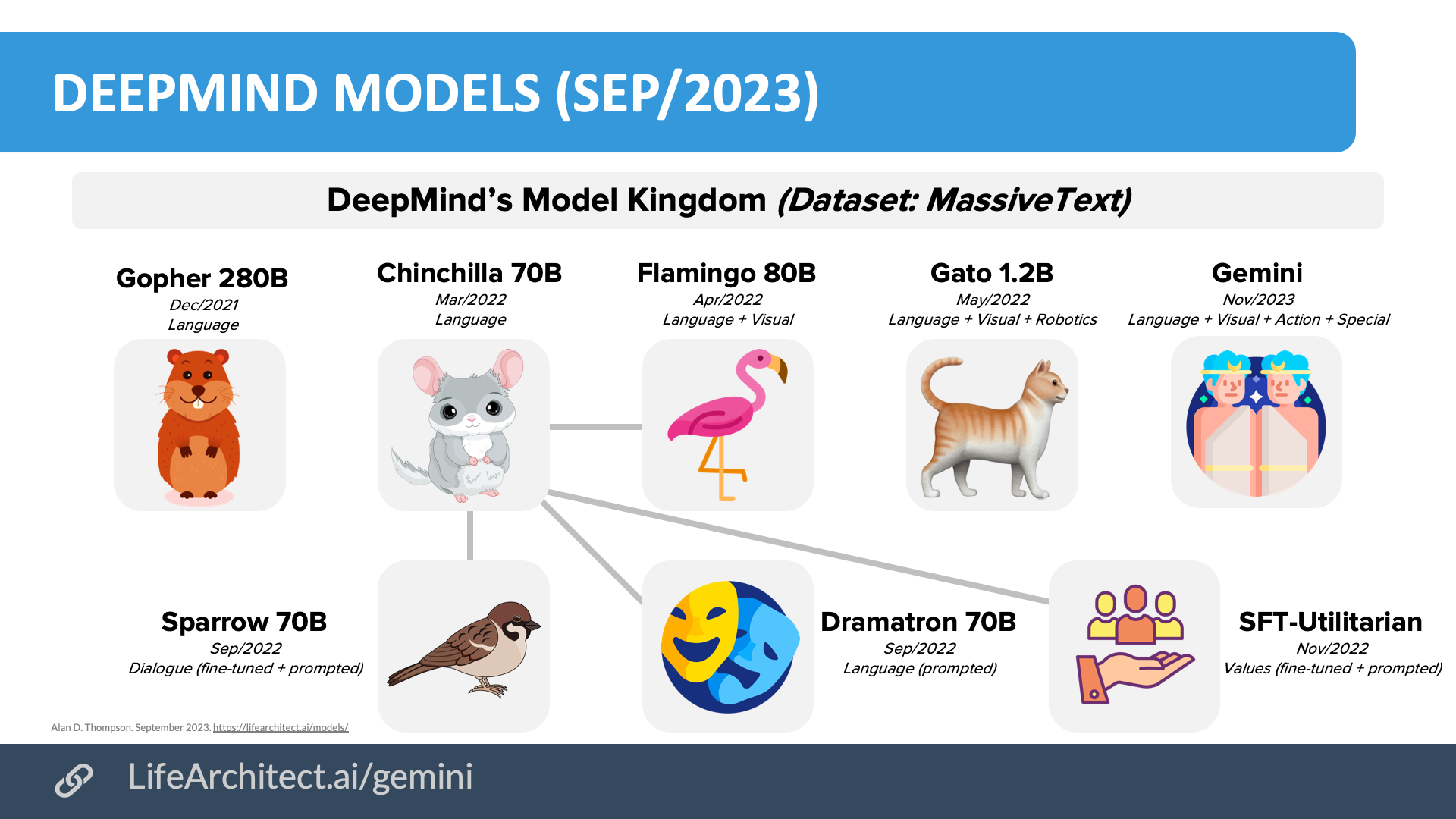
| Date | Type | Title |
| Dec/2025 | 📑 | Genesis Mission |
| Jan/2025 | 📑 | What's in Grok? |
| Jan/2025 | 💻 | NVIDIA Cosmos video dataset |
| Aug/2024 | 📑 | What's in GPT-5? |
| Jul/2024 | 💻 | Argonne AuroraGPT |
| Sep/2023 | 📑 | Google DeepMind Gemini: A general specialist |
| Feb/2023 | 💻 | Chinchilla data-optimal scaling laws: In plain English |
| Aug/2022 | 📑 | Google Pathways |
| Mar/2022 | 📑 | What's in my AI? |
| Sep/2021 | 💻 | Megatron the Transformer, and related language models |
| Ongoing... | 💻 | Datasets Table |
Get The Memo
by Dr Alan D. Thompson · Be inside the lightning-fast AI revolution.Informs research at Apple, Google, Microsoft · Bestseller in 152 countries.
Artificial intelligence that matters, as it happens, in plain English.
Get The Memo.
 Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.
Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.This page last updated: 26/Jun/2026. https://lifearchitect.ai/chinchilla/↑
- 1Kindle ≈ 6M books (estimate) https://justpublishingadvice.com/how-many-kindle-ebooks-are-there
Yale ≈ 15M items https://yaledailynews.com/blog/2018/04/06/stange-love-your-library
Google Books ≈ 25M books https://archive.ph/rMbE2
US Library of Congress ≈ 51M cataloged books https://www.loc.gov/about/general-information/#year-at-a-glance
British Library ≈ 170M items https://www.bl.uk/about-us/our-story/facts-and-figures-of-the-british-library
US public libraries ≈ 732M books, note that this definitely includes (many) duplicates https://nces.ed.gov/programs/digest/d17/tables/dt17_701.60.asp
Bibles ≈ 5B copies https://www.guinnessworldrecords.com/world-records/best-selling-book-of-non-fiction
Earth to Moon ≈ 384,400km≈ 38,440,000,000cm, each book spine 2.4cm thick ≈ 16B books
Human population ≈ 8B (Jun/2022) - 2500KB ≈ 500K characters ≈ 75K words ≈ 300 pages per book. Simplified and rounded for easy figures.
- 3


