Get The Memo.
Alan D. Thompson
Apr/2021–2025
There are several pages related to this one (most recent at top):
| Page | Link |
|---|---|
| Solace: Superintelligence and goodness | LifeArchitect.ai/solace |
| Mapping IQ, MMLU, MMLU-Pro, GPQA | LifeArchitect.ai/mapping |
| The psychology of modern LLMs | LifeArchitect.ai/psychology |
| GPT-3.5 IQ testing using Raven’s Progressive Matrices | LifeArchitect.ai/ravens |
| Visualizing brightness (IQ scores) | LifeArchitect.ai/visualising-brightness |
| The new irrelevance of intelligence (Mensa, 2020) | LifeArchitect.ai/irrelevance-of-intelligence |
| More… | See AI and IQ menus… |
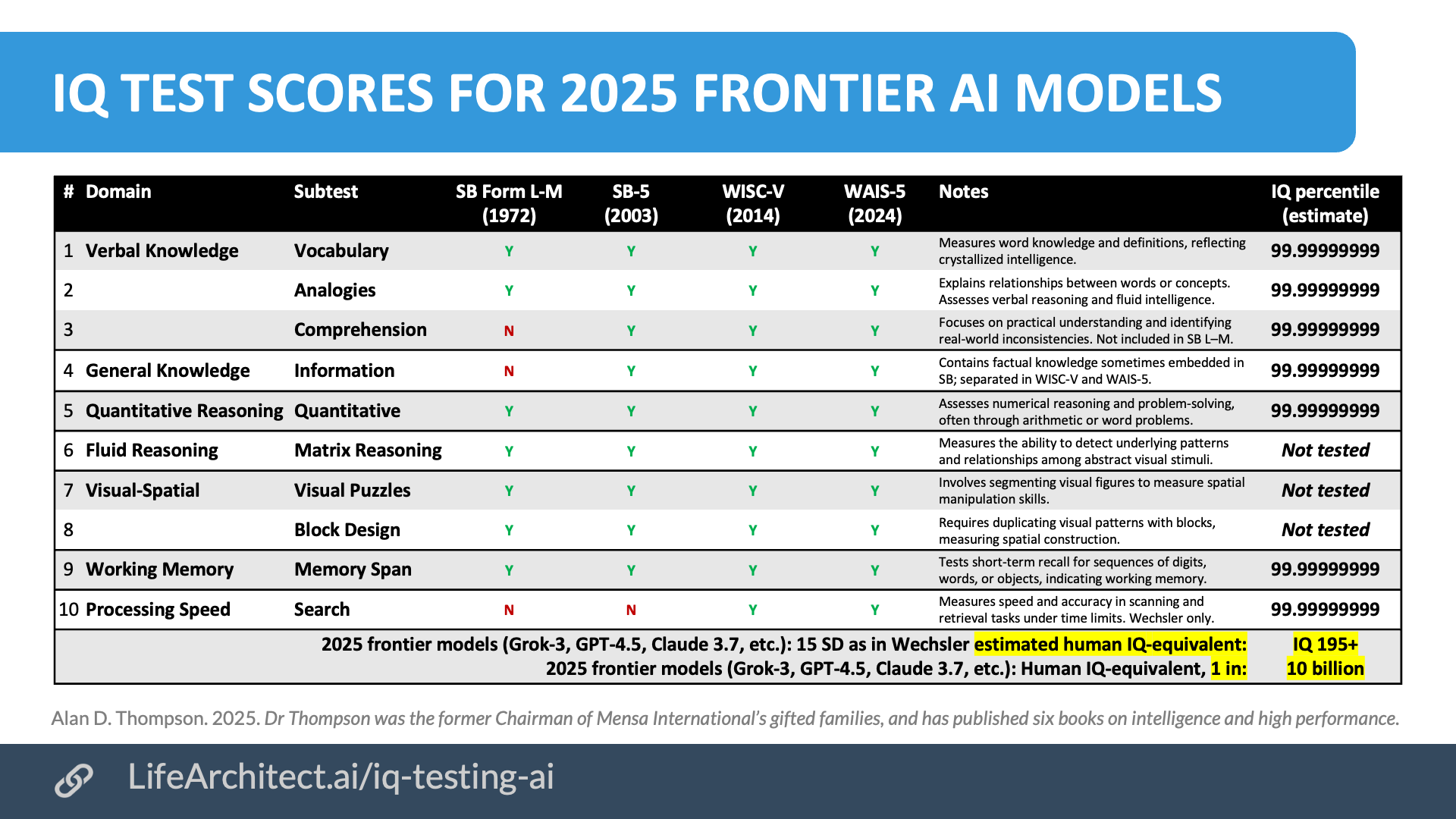
IQ test scores for 2025 frontier AI models
 Download source (PDF)
Download source (PDF)
*2025 frontier models would achieve a human IQ-equivalent score of 195 or greater, placing them at ‘superhuman’ levels. Obviously, IQ scores of 195, stats like 99.99999999, and comparisons like ‘1 in 10B’ are not straightforward for many reasons (outlined below), and yet it’s important that the public is aware of what is currently happening in the land of large language models.
- Scaling issues: IQ tests were designed for human cognition, and their scales blur when applied to non-human intelligence.
- Norming limitations: As I found time and time again during my work with prodigies, IQ tests are normed on ‘average’ human populations, making extreme outliers statistically difficult to interpret.
- Equivalence challenges: Artificial intelligence is arguably different from human intelligence, making direct comparisons problematic.
- Test constraints: IQ tests measure a subset of intelligence, and AI’s performance on such tasks does not equate to generalized thinking ability.
- Statistical saturation: Past a certain point (up to about IQ 155 with expanded/extended results on Wechsler instruments), IQ scales become unreliable, and meaningful differentiation at extreme levels becomes imprecise.
Viz (most recent at top)
GPQA bubbles
MMLU
 Download source (PDF)
Download source (PDF)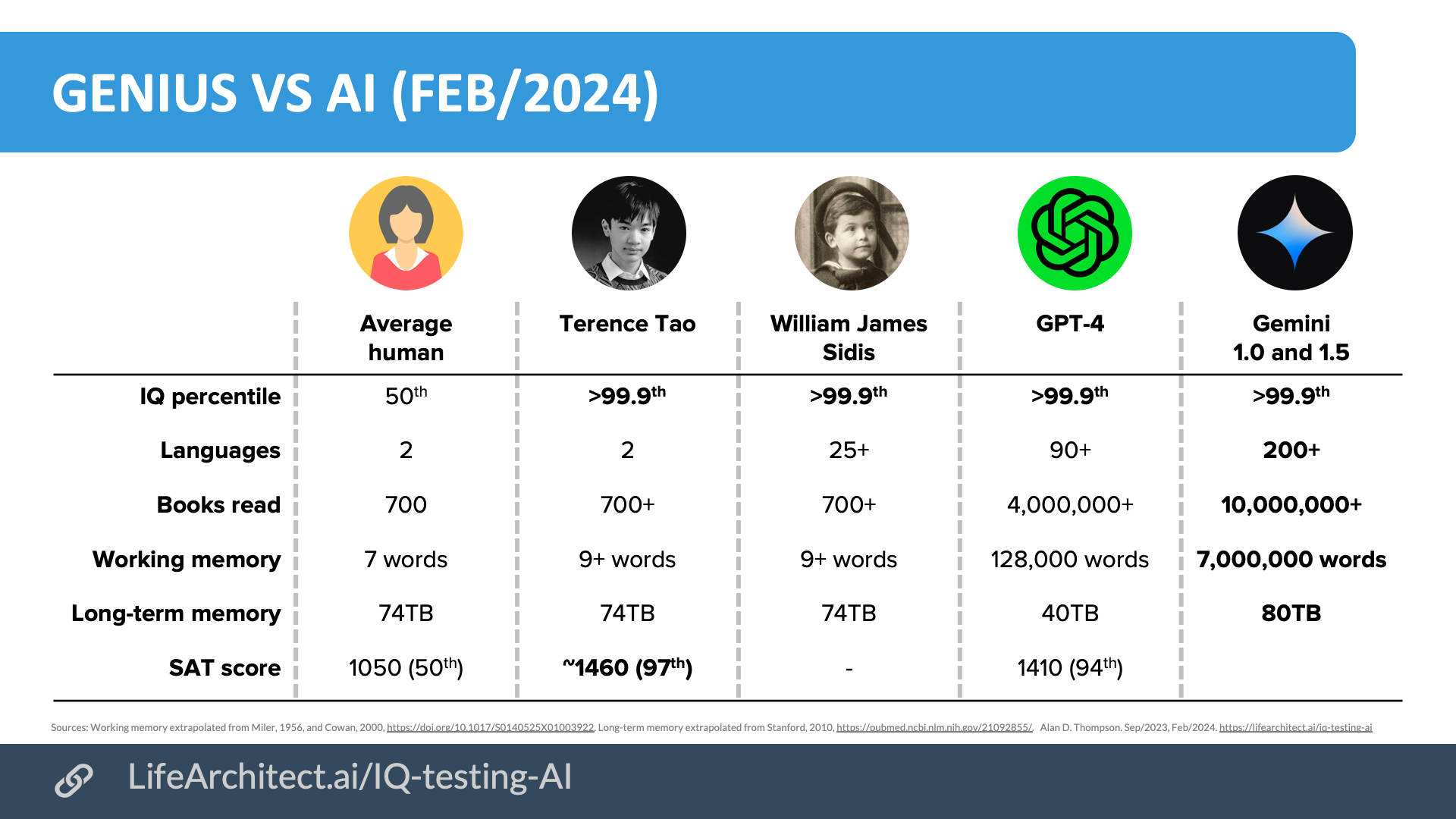 Download source (PDF)
Download source (PDF) Download source (PDF)
Download source (PDF)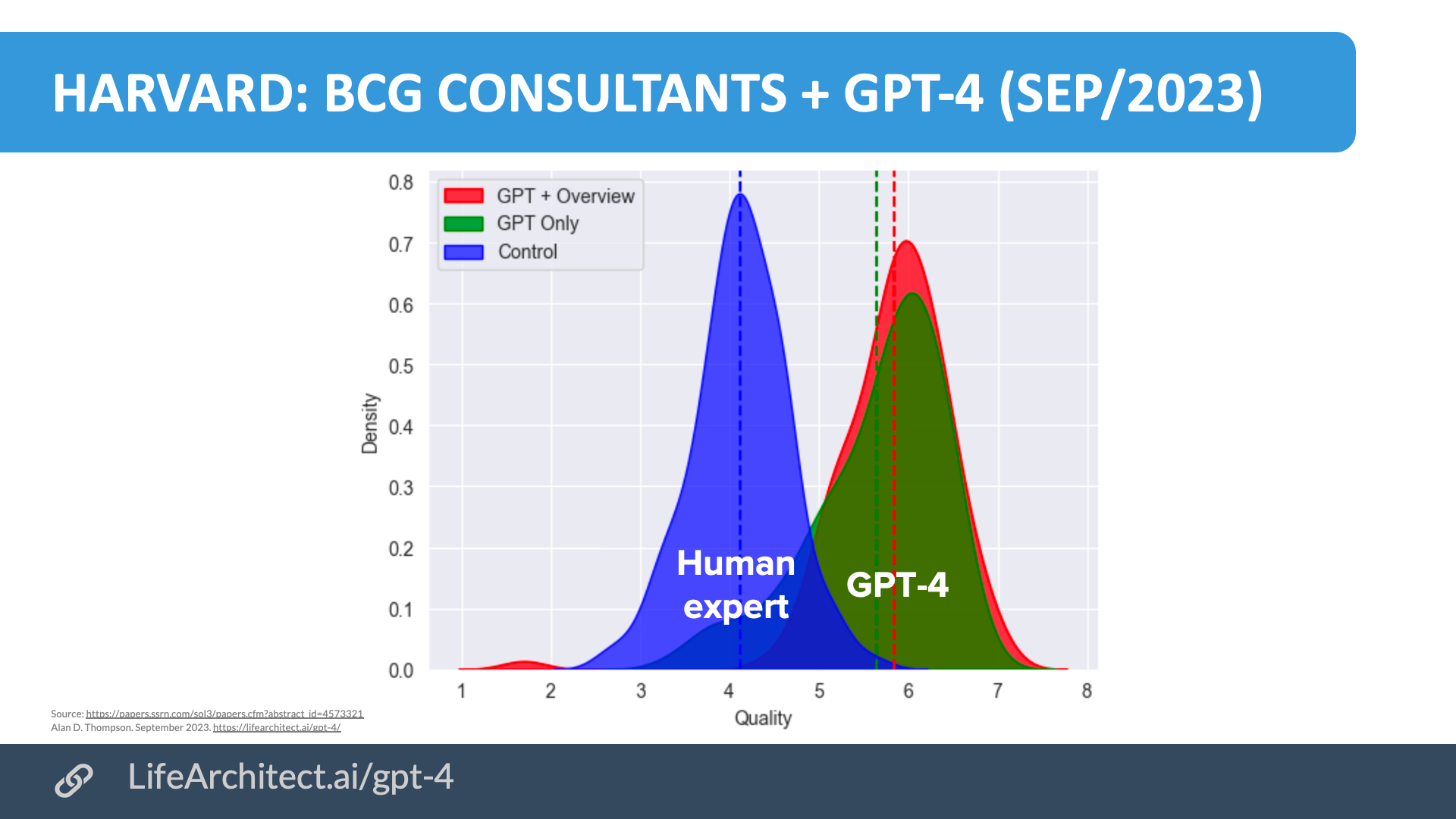 Download source (PDF)
Download source (PDF) Download source (PDF)
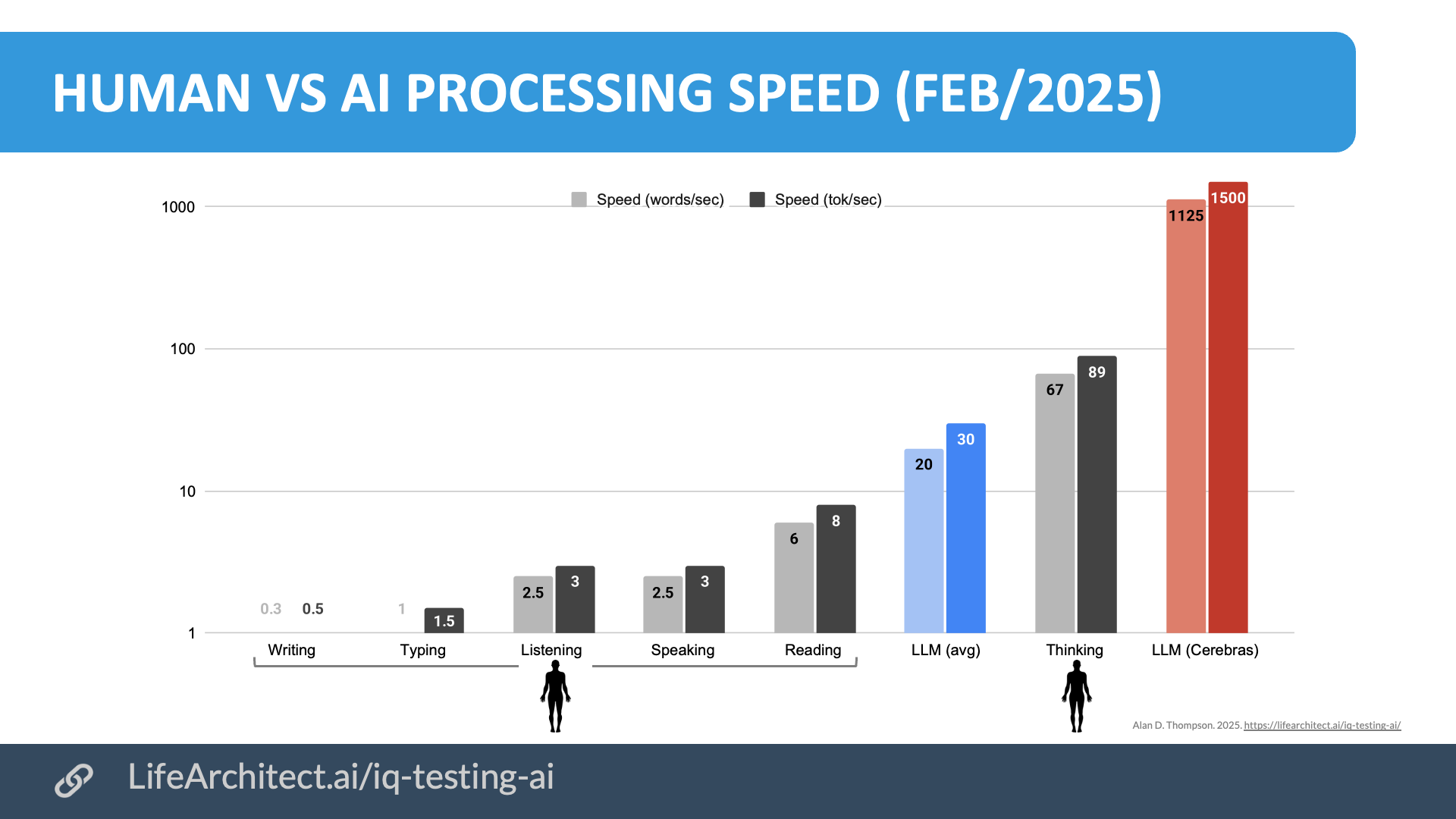
Download source (PDF)Processing Speed
NYT Connections

Source: GitHub repo.
Emotional intelligence


Humor & funniness

Older viz
Note: While I would love to facilitate cognitive testing of current language models, nearly all popular IQ instruments would preclude testing of a ‘written word only’ language model; the most common instruments from Wechsler and Stanford-Binet require a test candidate who is using verbal, auditory, visual, and even kinaesthetic… For this reason, AI labs generally use customised testing suites focused on written only. A selection of these benchmarks have been visualised below. Please see the full data for context and references. (Update Dec/2022: This note is now outdated, and we can test AI models on some IQ tests like Raven’s, though specialized AI benchmarks are still standard.)
 Download source (PDF)
Download source (PDF)
Tests: View the data (Google sheets)
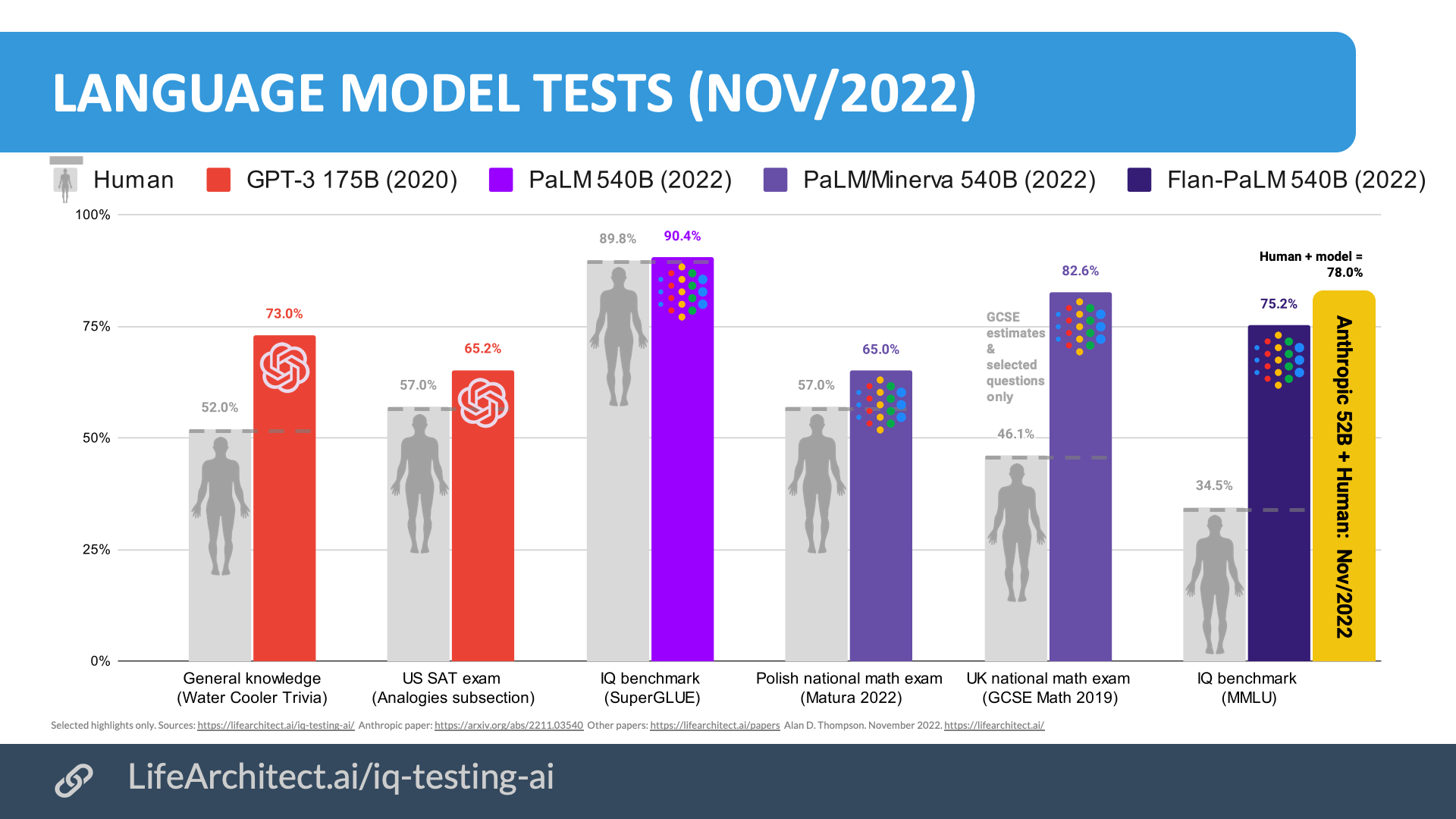
Trivia test (by WCT): Human: 52%, GPT-3: 73%, J1: 55.4%
Highlights
On SAT questions, GPT-3 scored 15% higher than an average college applicant.
On trivia questions, models like GPT-3 and J1 score up to 40% higher than the average human.


Download source (PDF)
Tests: View the data (Google sheets)
Trivia test (by WCT): Human: 52%, GPT-3: 73%, J1: 55.4%
The following chart is from TIME magazine (2/Aug/2023):
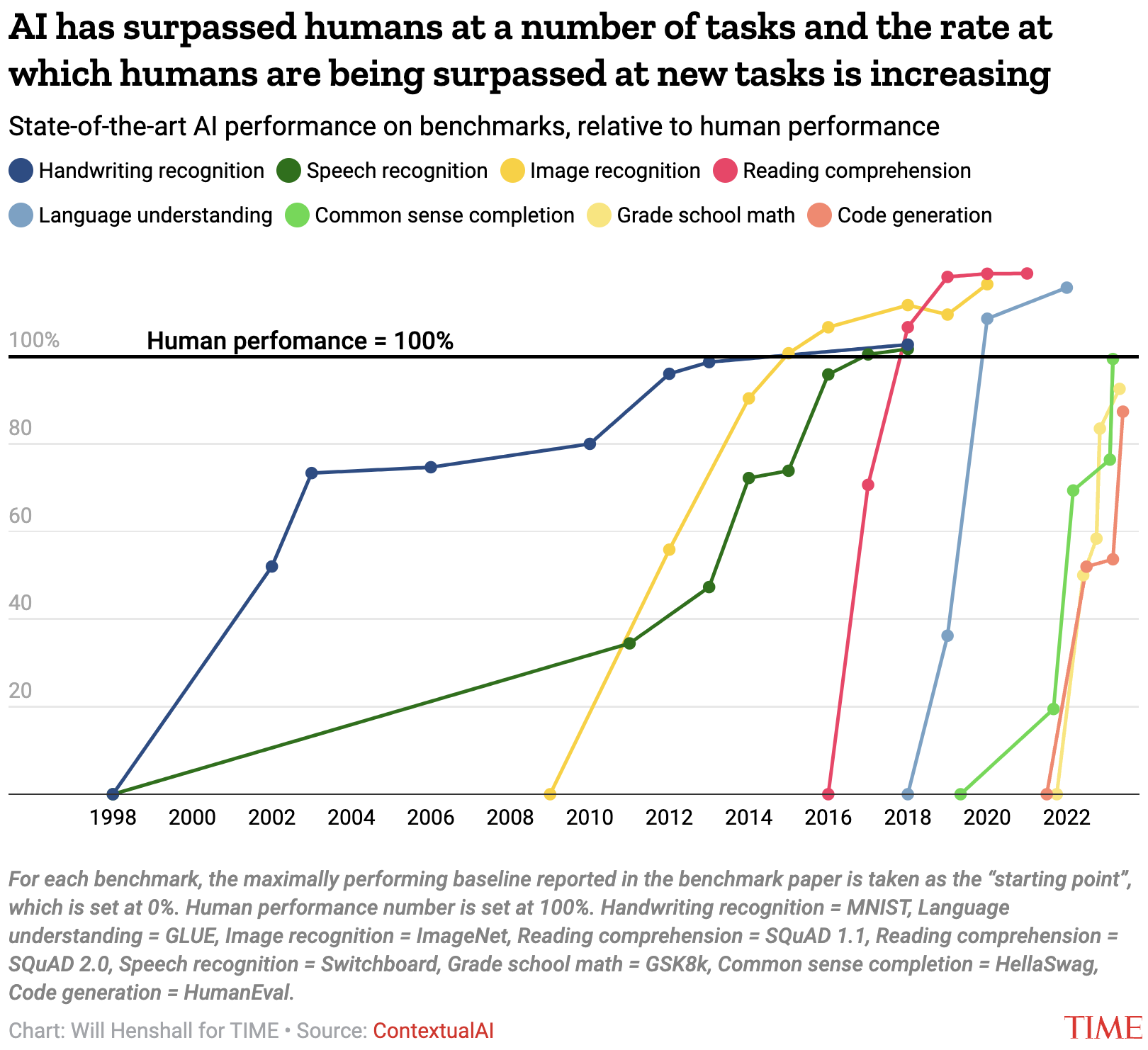
Notable events in IQ testing AI models
| Date | Summary | Notes |
|---|---|---|
| Jul/2025 | Grok 4 Heavy achieves scores of AIME25=100, said to achieve SAT=100. | Grok 4 Heavy hit the ceiling (human peak performance) on standardized tests including the AIME25=100 (2025 American Invitational Mathematics Examination), SAT=100 (Scholastic Assessment Test, a standardized test widely used for college admissions in the United States, estimated), as well as very high scores on superhuman benchmarks HLE=44.4 and GPQA=88.9. |
| Mar/2025 | GPT-4.5 judged to be more human than humans. | Turing test: ‘GPT-4.5 was judged to be the human 73% of the time: significantly more often than interrogators selected the real human participant.’ |
| Sep/2024 | OpenAI o1 outperforms expert PhDs | o1 hit 78.3% on the GPQA benchmark, outperforming specialized PhDs in their subject field (65%). Read more at: LifeArchitect.ai/mapping |
| Mar/2024 | Claude 3 Opus outperforms PhDs | Claude 3 Opus hit 50.4% on the GPQA benchmark, outperforming PhDs (34%). |
| Jan/2024 | DeepMind AlphaGeometry approaches IMO gold medallist | DeepMind AlphaGeometry trained using 100% synthetic data, open source, ‘approaching the performance of an average International Mathematical Olympiad (IMO) gold medallist. |
| Oct/2023 | BASIS superintelligence suite | Introducing BASIS, a new benchmark for measuring artificial superintelligence at and above IQ 180. |
| Aug/2023 | GPT-4 TTCT = P99 | Creativity. TTCT is gold standard for creativity testing (wiki), questions by Scholastic Testing Service confirmed private/not part of training dataset. GPT-4 scored in 99th percentile. |
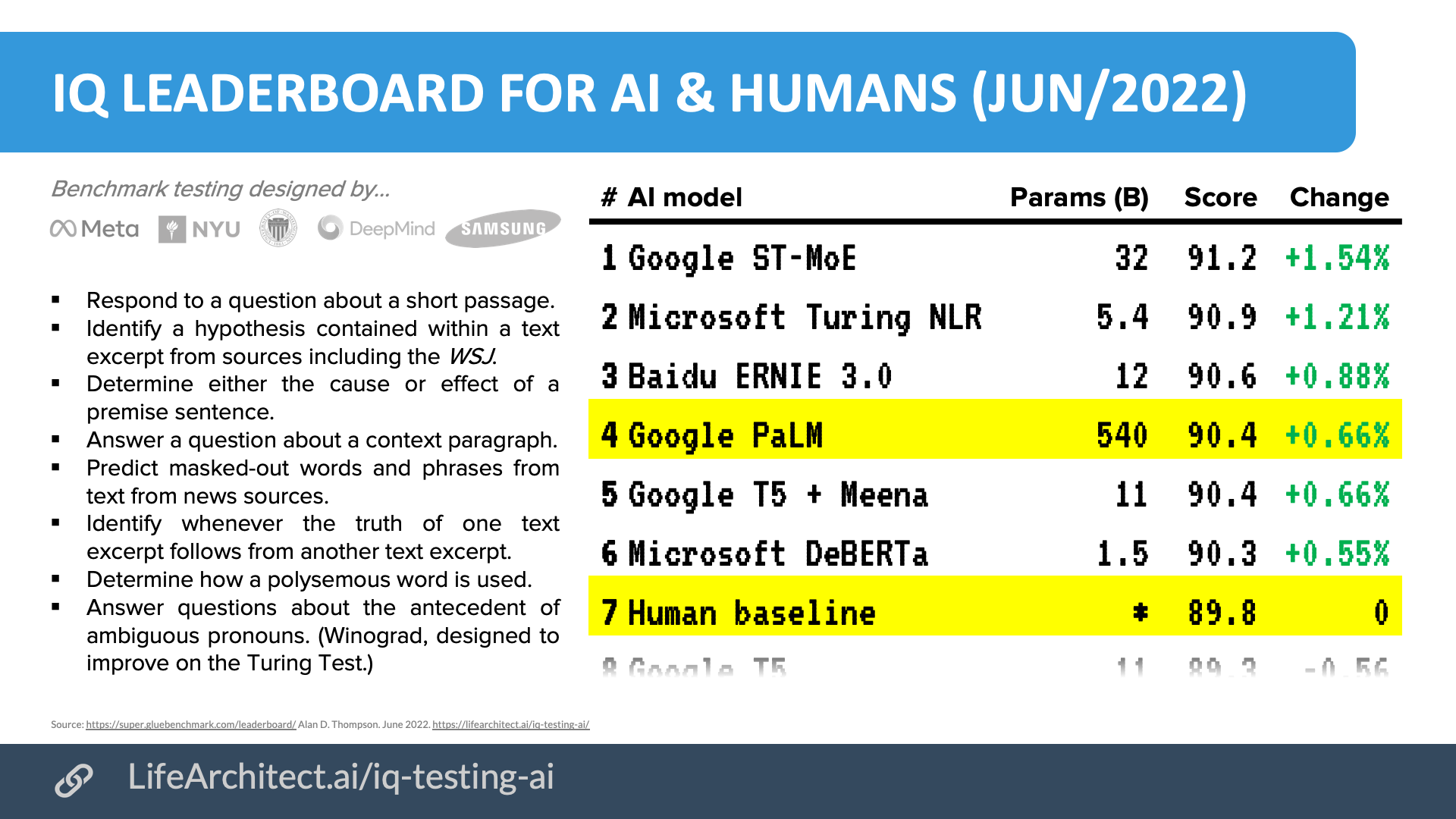
| May/2023 | PaLM 2 breaks 90% on WinoGrande (PDF, Google) | For the first time, a large language model has breached the 90% mark on WinoGrande, a ‘more challenging, adversarial’ version of Winograd, designed to be very difficult for AI. Fine-tuned PaLM 2 scored 90.9%; humans are at 94%. |
| May/2023 | GPT-4 achieves 100% on ToM (Johns Hopkins) | Johns Hopkins: ‘GPT-4 reached ceiling accuracy of 100% [Two-Shot CoT plus SS Thinking]. Human performance in these scenarios was 87%‘ |
| Mar/2023 | GPT-4 = IQ 155 | Clinical psychologist Eka Roivainen used the WAIS III to assess ChatGPT (assuming GPT-4): verbal IQ of 155 (P99.987). |
| Mar/2023 | GPT-4 = IQ 152 | GPT-4 had an IQ of 152 on a Verbal-Linguistic IQ Test via Prof David Rozado. This would place it in the 99.9th percentile. |
| Mar/2023 | GPT-4 outperforms humans across various exams | OpenAI: GPT-4 ‘…we tested on a variety of benchmarks, including simulating exams that were originally designed for humans. We proceeded by using the most recent publicly-available tests (in the case of the Olympiads and AP free response questions) or by purchasing 2022–2023 editions of practice exams. We did no specific training for these exams.’ |
| Feb/2023 | GPT-3.5 mental state of 9yo child | Stanford: text-davinci-003 ‘solved 93% of [theory of mind] tasks, a performance comparable with that of nine-year-old children… ToM-like ability (thus far considered to be uniquely human) may have spontaneously emerged as a byproduct of language models’ improving language skills.’ [Update 15/Mar/2023: Adjusted down to seven-year-old for GPT-4 due to new, more conservative benchmarks.] |
| Feb/2023 | Kosmos-1 ‘sees’ Raven’s IQ tests | ‘Kosmos-1 is able to perceive abstract conceptual patterns in a nonverbal context, and then deduce the following element across multiple choices. To the best of our knowledge, it is the first time that a model can perform such zero-shot Raven IQ tests [with vision]… there is still a large performance gap [9.3% above chance] between the current model and the average level of adults…’ |
| Jan/2023 | ChatGPT = IQ 147 | ChatGPT had an IQ of 147 on a Verbal-Linguistic IQ Test via Prof David Rozado. This would place it in the 99.9th percentile. |
| 19/Dec/2022 | GPT-3.5 outperforms humans on some tasks in symbolic Raven’s IQ tests | UCLA psychology tested GPT-3.5 [28/Nov/2022 release] using a symbolic model of Raven’s Progressive Matrices (RPM): ‘We found that GPT3 displayed a surprisingly strong capacity for abstract pattern induction [in text only, not vision], matching or even surpassing human capabilities in most settings’ |
| 4/Nov/2022 | Anthropic’s testing on MMLU benchmarks find that model AND human outperforms model OR human | …we find that human participants who interact with an unreliable large-language-model dialog assistant through chat—a trivial baseline strategy for scalable oversight—substantially outperform both the model alone and their own unaided performance… large language models can productively assist humans with difficult tasks… present large language models can help humans achieve difficult tasks in settings that are relevant to scalable oversight. — Anthropic, Nov/2022. |
| 10/Feb/2022 | GPT-3 has intelligence | GPT-3 has its own form of fluid and crystalline intelligence. The crystalline part is all of the facts it has accumulated and the fluid part is its ability to make logical deductions from learning the relationships between things. – OpenAI, Feb/2022 |
| 8/Dec/2021 | DeepMind Gopher on par with students for SAT reading questions | NYT reported “In December 2021, DeepMind announced that its L.L.M. Gopher scored results on the RACE-h benchmark — a data set with exam questions comparable to those in the reading sections of the SAT — that suggested its comprehension skills were equivalent to that of an average high school student.” RACE-h as complex reading comprehension questions for high-school students: Average human (Amazon Turk worker) = only 69.4%, ceiling 94.2% (link) PaLM 540B = 54.6% (few-shot). Gopher 280B = 71.6% |
| 2/Nov/2020 | GPT-3 is Artificial General Intelligence. | In November 2020, Connor Leahy, co-founder of EleutherAI, re-creator of GPT-2, creator of GPT-J & GPT-NeoX-20B, CEO of Conjecture, said about OpenAI GPT-3: “I think GPT-3 is artificial general intelligence, AGI. I think GPT-3 is as intelligent as a human. And I think that it is probably more intelligent than a human in a restricted way… in many ways it is more purely intelligent than humans are. I think humans are approximating what GPT-3 is doing, not vice versa.” — Connor Leahy (November 2020) |
GPT achievements
ChatGPT achievements: View the full data (Google sheets)
Binet assessment with Leta AI
An early version of the Binet (1905) was run with Leta AI in May 2021. It is very informal, only a small selection of questions were used, and it should be considered as a fun experiment only.
Get The Memo
by Dr Alan D. Thompson · Be inside the lightning-fast AI revolution.Informs research at Apple, Google, Microsoft · Bestseller in 152 countries.
Artificial intelligence that matters, as it happens, in plain English.
Get The Memo.
 Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.
Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.This page last updated: 5/Aug/2025. https://lifearchitect.ai/iq-testing-ai/↑