
Get The Memo.
-
- Summary
- Benchmarks
- Gemini updates
- Visualizations
- Timeline
- Dataset
- – Dataset via monorepo (code)
- – Dataset via MassiveText
- – Dataset via YouTube
- Google Pathways
- DeepMind models
Summary
| Organization | Google DeepMind |
| Model name | Gemini |
| Internal/project name | Goldfish |
| Model type | Multimodal, dense |
| Parameter count | Alan estimates: 1.5T. See also: GPT-5 1. Nano-1 1.8B 2. Nano-2 3.25B 3. Pro 180B 4. Ultra 1.5T |
| Dataset size (tokens) | Alan estimates: 30T for Gemini Ultra 1.0. |
| Training start date | Alan estimates: May/2023 |
| Training end/convergence date | Alan estimates: Nov/2023. |
| Training time (total) | Available to Institutional clients. |
| Release date (public) | 6/Dec/2023 for Pro, 8/Feb/2024 for Ultra 1.0 |
| Paper | Gemini 1 Report.pdf |
| Annotated paper | Download annotated paper (PDF). Available exclusively to full subscribers of The Memo. |
| Playground | Bard (US) and Google Cloud Vertex AI (13/Dec/2023) |
Benchmarks
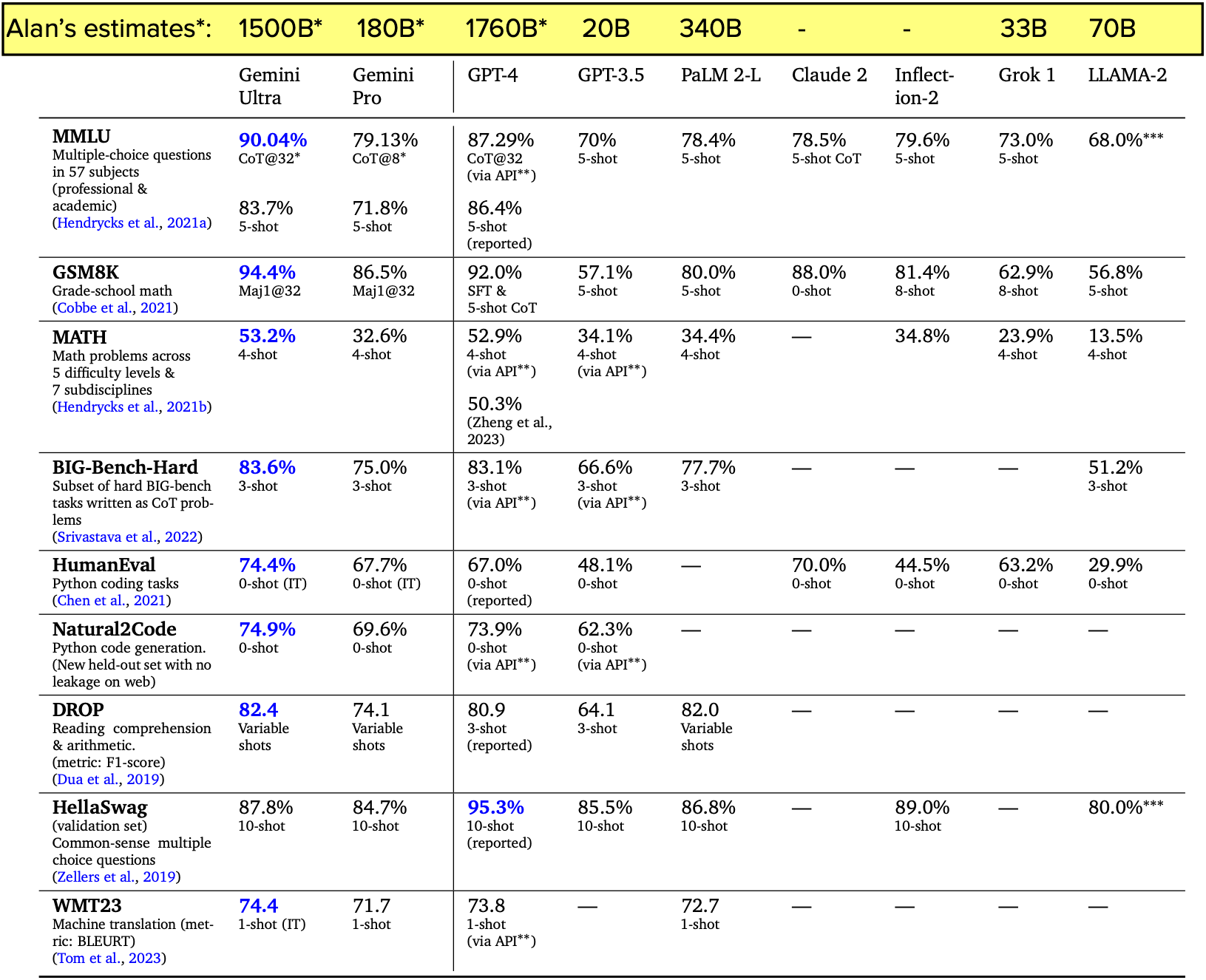 Gemini benchmarks with model size estimates from Alan’s annotated paper.
Gemini benchmarks with model size estimates from Alan’s annotated paper.
Gemini Updates
2/Mar/2024: Google founder Sergey Brin talks about Gemini 1.5 Pro (Goldfish):
…when we were training this [Gemini 1.5 sparse MoE] model, we didn’t expect it to come out nearly as powerful as it did or have all the capabilities that it does. In fact, it was just part of a scaling ladder experiment.
https://lifearchitect.ai/sergey/
20/Feb/2024: Gemini Ultra runs Python code. ‘Exclusive to Gemini Advanced, you can now edit and run Python code snippets directly in Gemini’s user interface. This allows you to experiment with code, see how changes affect the output, and verify that the code works as intended.’ (Gemini updates)
16/Feb/2024: Gemini 1.5 released as sparse MoE with ~10M token context window:
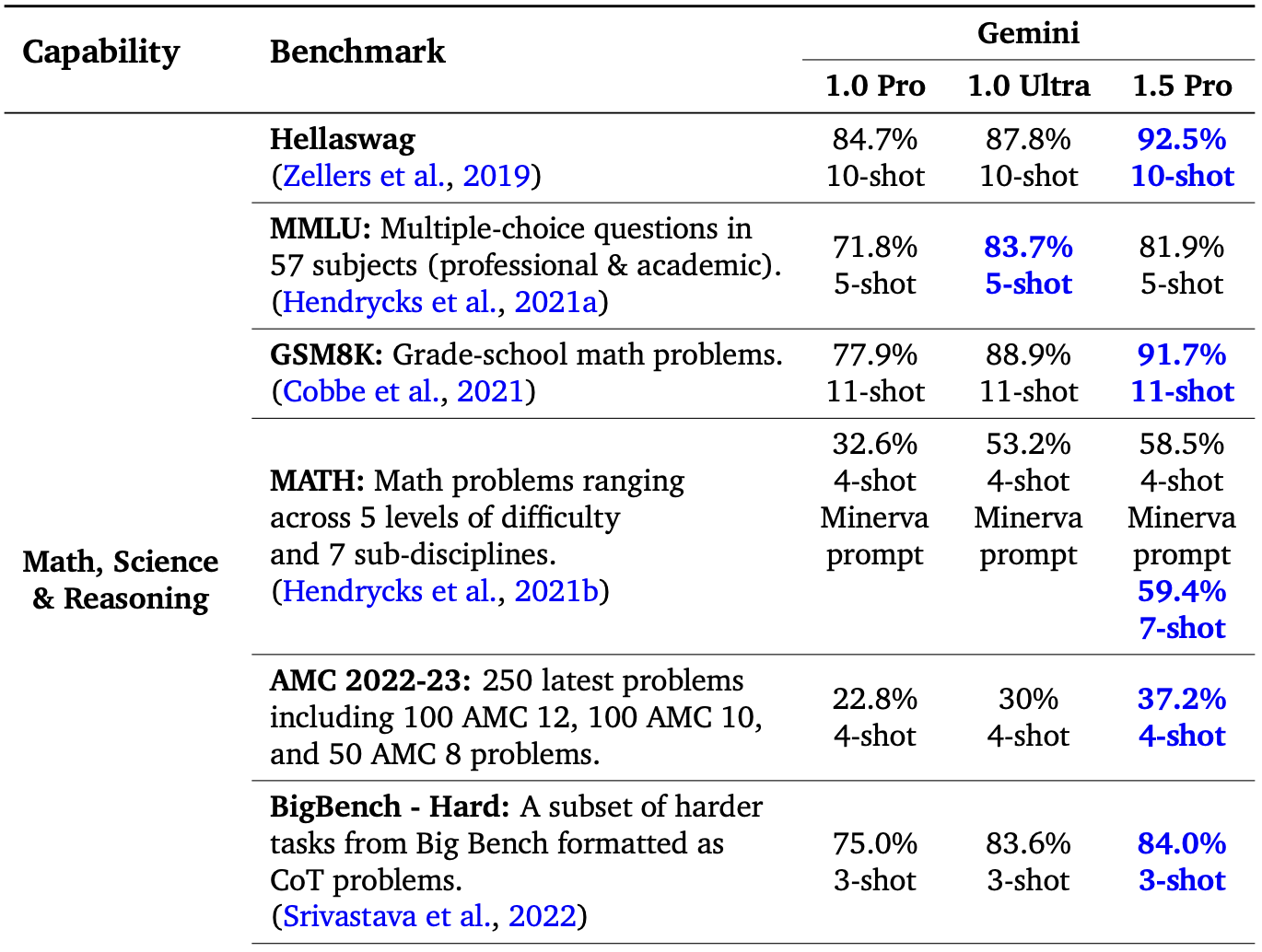
Announce: https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/
Paper: https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
14/Feb/2024: Google Goose (Gemini) + Google Duckie chatbot: ‘descendant of Gemini… trained on the sum total of 25 years of engineering expertise at Google… can answer questions around Google-specific technologies, write code using internal tech stacks and supports novel capabilities such as editing code based on natural language prompts.’ See also: Rubber duck debugging (wiki). (BI)
13/Feb/2024: Release of my independent report on Gemini (final version): LifeArchitect.ai/gemini-report
8/Feb/2024: Google CEO: ‘We’re already well underway training the next iteration of our Gemini models’ (Google blog)
18/Jan/2024: Gemini on Samsung phones. ‘Samsung’s Notes, Voice Recorder and Keyboard apps will use Gemini Pro…Galaxy S24 series will also come built-in with Gemini Nano, the most efficient model for on-device tasks, to enable a new feature in Google Messages and ensure your data doesn’t leave your smartphone. Additionally, Samsung will be one of the first partners to test Gemini Ultra, our largest model for highly complex tasks, before it is available broadly to developers and enterprise customers later this year.’ (Google blog)
10/Dec/2023: Gemini name explained by Dr Jeff Dean (Twitter):
Gemini is Latin for “twins”. The Gemini effort came about because we had different teams working on language modeling, and we knew we wanted to start to work together. The twins are the folks in the legacy Brain team (many from the PaLM/PaLM-2 effort) and the legacy DeepMind team (many from the Chinchilla effort) that started to work together on the ambitious multimodal model project we called Gemini, eventually joined by many people from all across Google. Gemini was also the NASA project that was the bridge to the moon between the Mercury and Apollo programs.
6/Dec/2023: Gemini announced with technical report (no arch details). Watch the video demo:
4/Dec/2023: Google plans a ‘virtual preview’ of Gemini this week. (TI)
3/Nov/2023: Gemini delayed DeepMind CEO: ‘Gemini’s going very well. We’re very happy with it, and it’s looking very good. It’s still in sort of training or fine-tuning, and we’ll have more information to share on that very soon. [Likely 2024 now?] We’ll see.’ (CNBC, 14m17s)
24/Oct/2023: Gemini delayed via Google Q3 earnings call possibly suggests a delay on Gemini’s release to 2024:
Google CEO: I’m very excited at the progress there and as we’re working through getting the model ready.
To me, more importantly, we are just really laying the foundation of what I think of as the next-generation series of models we’ll be launching all throughout 2024. The pace of innovation is extraordinarily impressive to see. We are creating it from the ground up to be multimodal, highly efficient with tool and API integrations, and more importantly, laying the platform to enable future innovations as well.
We are developing Gemini in a way that it is going to be available at various sizes and capabilities, and we’ll be using it immediately across all our products internally as well as bringing it out to both developers and Cloud customers through Vertex.
So I view it as a journey, and each generation is going to be better than the other. And we are definitely investing, and the early results are very promising.
(Google)
16/Oct/2023: It is expected that Gemini’s context window will be revealed to be 32k for the model’s public release.
 Download source (PDF)
Download source (PDF)
12/Oct/2023: Google VP: ‘I’ve seen some pretty amazing things. Like, I’m trying to bake a cake, draw me 3 pictures of the steps to how to ice a three layer cake, and Gemini will actually create those images. These are completely novel pictures. These are not pictures from the internet. It’s able to speak in imagery with humans now, not just text.’ (BI)
18/Sep/2023: ‘Google has allegedly given a group of testers access to an early version of Gemini, suggesting a public release of the product is soon’ (UC Today)
16/Aug/2023: Paywalled update:
– “Gemini will … combin[e] the text capabilities of LLMs like GPT-4 with the ability to create AI images based on a text description, similar to AI-image generators Midjourney and Stable Diffusion … Gemini’s image capabilities haven’t been previously reported.”
– Expected availability via GCP in the fall [US fall is 23/Sep – 21/Dec].
– Google “may start using it in some products before then”.
– “it could also integrate video and audio [trained from YouTube] into the Gemini models”.
– “Two longtime DeepMind executives, Oriol Vinyals and Koray Kavukcuoglu, are in charge of Gemini alongside Jeff Dean … They oversee hundreds of employees involved in Gemini’s development.”
– “Google’s lawyers have been closely evaluating the training. In one instance, they made researchers remove training data that had come from textbooks—which could help the model answer questions about subjects like astronomy or biology—over concerns about pushback from copyright holders.” (TI)
2/Aug/2023: GDM Soft MoE: ‘a fully-differentiable sparse Transformer… maintaining the benefits of MoEs. Soft MoE performs an implicit soft assignment by passing different weighted combinations of all input tokens to each expert… Soft MoE greatly outperforms standard Transformers (ViTs) and popular MoE variants (Tokens Choice and Experts Choice).’ (arXiv)
28/Jul/2023: GDM RT-2: ‘co-fine-tune state-of-the-art vision-language models on both robotic trajectory data and Internet-scale vision-language tasks, such as visual question answering.’ (project page)
20/Jul/2023: Gemini will be released by Dec/2023: ‘Gemini is Google’s attempt to build a general-purpose AI program that can rival OpenAI’s GPT-4 model, which powers a paid version of ChatGPT. Demis Hassabis, the Google executive overseeing the project, told employees during a recent companywide meeting that the program would become available later this year…’ (WSJ)
11/Jul/2023: Interview with Verge: ‘Gemini… is our next-generation multimodal large models — very, very exciting work going on there, combining all the best ideas from across both world-class research groups [DeepMind and Google AI]. It’s pretty impressive to see… Today’s chatbots will look trivial by comparison to I think what’s coming in the next few years… ‘ (Verge)
11/Jul/2023: Interview with NYT: ‘And so what I think is going to happen in the next era of systems — and we’re working on our own systems called Gemini — is that I think there’s going to be a combination of the two things [general and specialized]. So we’ll have this increasingly more powerful general system that you basically interact with through language but has other capabilities, general capabilities, like math and coding, and perhaps some reasoning and planning, eventually, in the next generations of these systems… There should be specialized A.I. systems that learn how to do those things — AlphaGo, AlphaZero, AlphaFold. And actually, the general system can call those specialized A.I.s as tools.’ (NYT)
26/Jun/2023: “At a high level you can think of Gemini as combining some of the strengths of AlphaGo-type systems with the amazing language capabilities of the large models,” Hassabis says. “We also have some new innovations that are going to be pretty interesting.” Gemini is still in development, a process that will take a number of months, Hassabis says…. “I can see the kinds of things we’re building into the Gemini series right, and we have no reason to believe that they won’t work,” he says. (Wired)
14/Jun/2023: Gemini being trained on YouTube. ‘Google’s researchers have been using YouTube to develop its next large-language model, Gemini’ (Twitter, TI)
1/Jun/2023: Google DeepMind trains an LLM (DIDACT) on iterative code in Piper, their 86TB monorepo (2016 PDF). Using The Pile’s calculation (paper) of 0.4412 tokens per byte, this dataset would be around 37.9T tokens, or about twice the size of the next biggest dataset in GPT-4 (estimated). This means that there would be no rumored data scarcity for training Gemini.
Open the Datasets Table in a new tab24/May/2023: Google DeepMind partnership leads to DeepMind’s Flamingo 80B (my video Part 1, Part 2) being applied to Google YouTube Shorts video summarization and search optimization. ‘It automatically generates descriptions for hundreds of millions of videos in their metadata, making them more searchable.’ (-via DeepMind)
DeepMind Flamingo (Apr/2022) is a phenomenal visual language model, and was in many ways a precursor to OpenAI’s GPT-4 (Mar/2023), sharing several design concepts. And this is the best use case they can come up with? Hmmm…

10/May/2023: Google CEO (Google blog):
We’re already at work on Gemini — our next model created from the ground up to be multimodal, highly efficient at tool and API integrations, and built to enable future innovations, like memory and planning. Gemini is still in training [as of 10/May/2023], but it’s already exhibiting multimodal capabilities never before seen in prior models. Once fine-tuned and rigorously tested for safety, Gemini will be available at various sizes and capabilities, just like PaLM 2, to ensure it can be deployed across different products, applications, and devices for everyone’s benefit. – Google blog (10/May/2023).
20/Apr/2023: Google DeepMind. Announced by DeepMind CEO (DeepMind blog, and confirmed via the Google Blog):
…DeepMind and the Brain team from Google Research will be joining forces as a single, focused unit called Google DeepMind… bringing together our world-class talent in AI with the computing power, infrastructure and resources to create the next generation of AI breakthroughs and products across Google and Alphabet…
1/Aug/2022: My Google Pathways report was released, providing rigorous analysis of the design and development of Google’s models including PaLM, PaLM-Coder, Parti, and Minerva.
20/Apr/2018: Background on Google and DeepMind relationship from 2018 (The Information via MobileSyrup):
…some Google developers who are part of other AI research divisions at the company, such as Google Brain, are not happy that DeepMind doesn’t generate much revenue for the company.
…staff members are upset that DeepMind has “special status” within Alphabet that allows it to work on projects that might not yield results for years [Alan: this article is from 2018, and the most recent ‘merger’ happened five years later in 2023]…
…DeepMind had difficulty working with the time zone difference between London, England and [San Francisco, California].
DeepMind is a very private company and according to the report it objected to a “powered by DeepMind” tag on some of the Google products it helped create.
Google purchased DeepMind in 2014 for a reported $600 million and is most well-known for creating the AlphaGo program that beat the world’s top player in the game of Go.
Viz

2026 frontier AI models + highlights
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Older bubbles viz
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Oct/2024
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Feb/2024

Nov/2023
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Mar/2023
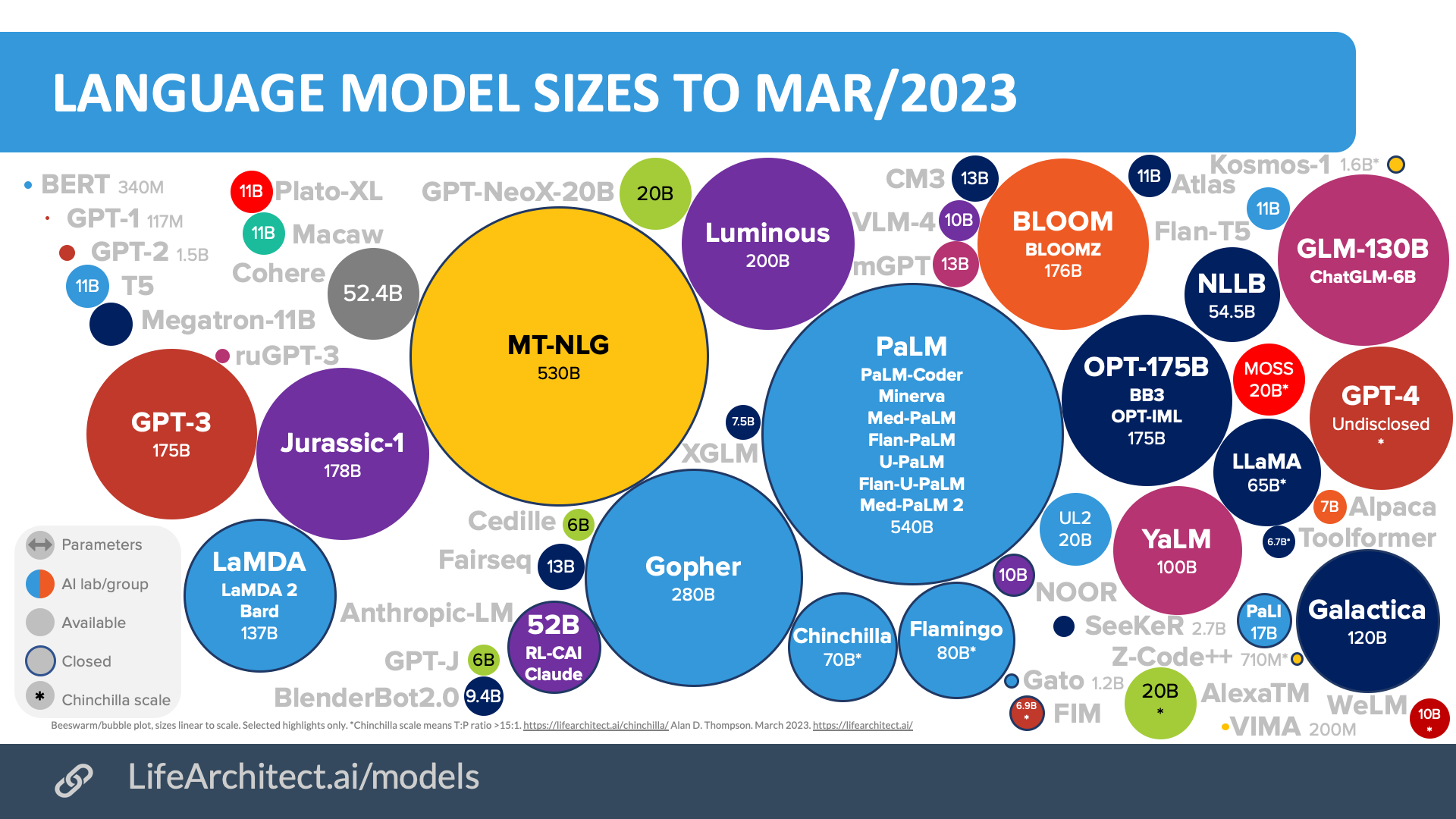 Download source (PDF)
Download source (PDF)
Apr/2022
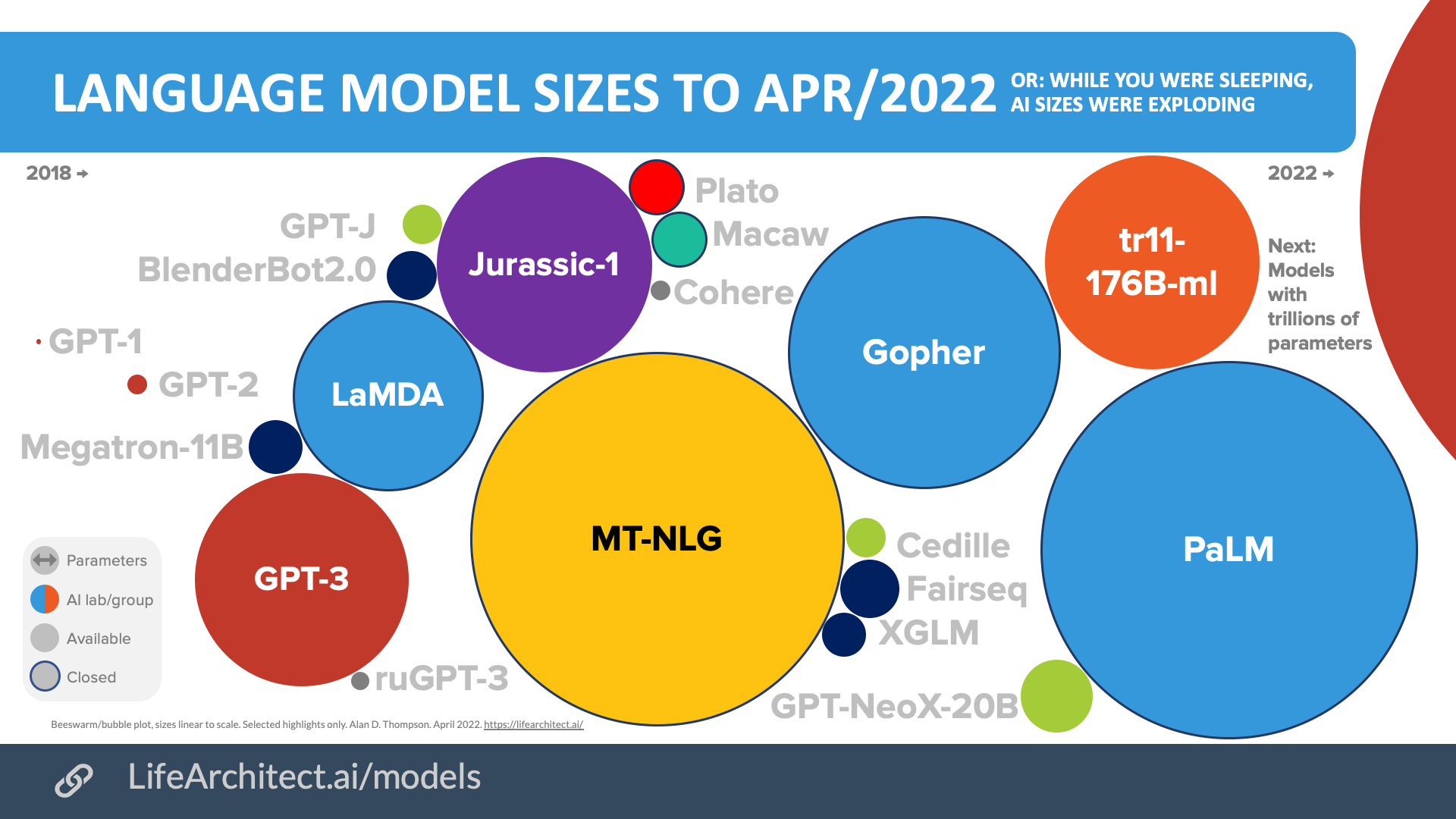 Download source (PDF)
Download source (PDF)
Models Table
View the full dataTimeline to Gemini
Dataset
Dataset for Gemini via Google’s Piper monorepo (estimate)
The Gemini dataset could be made up of a large amount of code, to support reasoning (many papers, 1, 2) within the final trained model. Google’s internal monorepo Piper, is 86TB (2016 PDF). Using The Pile’s calculation (paper) of 0.4412 tokens per byte, this dataset would be around 37.9T tokens, or about twice the size of the next biggest dataset in GPT-4 (estimated).
Open the Datasets Table in a new tabDataset for Gemini via MassiveText (estimate)
The Gemini dataset could potentially be made up of some of DeepMind’s MassiveText (multilingual) 5T-token dataset (see the Improving language models by retrieving from trillions of tokens paper and my What’s in my AI? paper).
Please note that the following table is ‘best guess’ by Alan (not confirmed by Google DeepMind), and is based on available information from the state-of-the-art DeepMind MassiveText (multilingual) + 1,000B tokens of discussion.
| Count | Dataset | Percentage tokens | Raw Size (GB) | Tokens (B) |
| 1 | Books (en) | 68.11% | 12,853GB | 3,423B |
| 2 | Discussion (multilingual, via YouTube, estimate)* | x% | 3,750GB | 1,000B* |
| 3 | Web: C4 (multilingual) | 19.45% | 3,656GB | 977B |
| 4 | Code: Github | 7.46% | 2,754GB | 375B |
| 5 | News (en) | 4.71% | 888GB | 237B |
| 6 | Wikipedia (multilingual) | 0.26% | 48GB | 13B |
| Totals | 23,949GB (23.9TB) | 6,000B (6T) |
* Alan’s estimate only.
Table. MassiveText multilingual dataset estimates. Rounded. Disclosed in bold (from DeepMind’s MassiveText multilingual dataset). Determined in italics. For similar models, see my What’s in my AI paper.
Dataset for Gemini via YouTube (estimate)
Google’s researchers have been using YouTube to develop its next large-language model, Gemini, according to a person with knowledge of the situation. (- Twitter, TI)
YouTube 2023 overall stats (via Wyzowl and Statista):
- Total videos: 800 million.
- Average length: 11.7 minutes.
- Total time: 9.36 billion minutes.
- Rounding to keep up with 30,000 hours uploaded per hour: 10B minutes.
YouTube 2023 text stats:
- Human speaking rate: 150 words per minute (wpm).
- 150wpm x 10B minutes = 1.5 trillion words total.
- Assume: (1) speaking only occurs in a subset of videos, (2) quality classifier retains videos with a score in the top 80%, then let’s keep 80% of this.
- 1.5T words x 0.8 = 1.2T words.
- 1.2T words x 1.3 = 1.56T text tokens.
1.5T text tokens is not enough to make a big dent in the requirements of models the scale of Gemini or GPT-5:
- 1T parameters (20T text tokens).
- 2T parameters (40T text tokens).
- 5T parameters (100T text tokens).
Given the focus on multimodality in 2023-2024 large language models, it can be assumed that visual content (not just text) is being used to train these models.
Google Pathways
While it’s expected that Google will need to compromise with DeepMind about the architecture for Gemini, my 2022 paper details the approach by Google to large language models and training.
 Google Pathways: An Exploration of the Pathways Architecture from PaLM to Parti
Google Pathways: An Exploration of the Pathways Architecture from PaLM to Parti
Alan D. Thompson
LifeArchitect.ai
August 2022
24 pages incl title page, references, appendix.
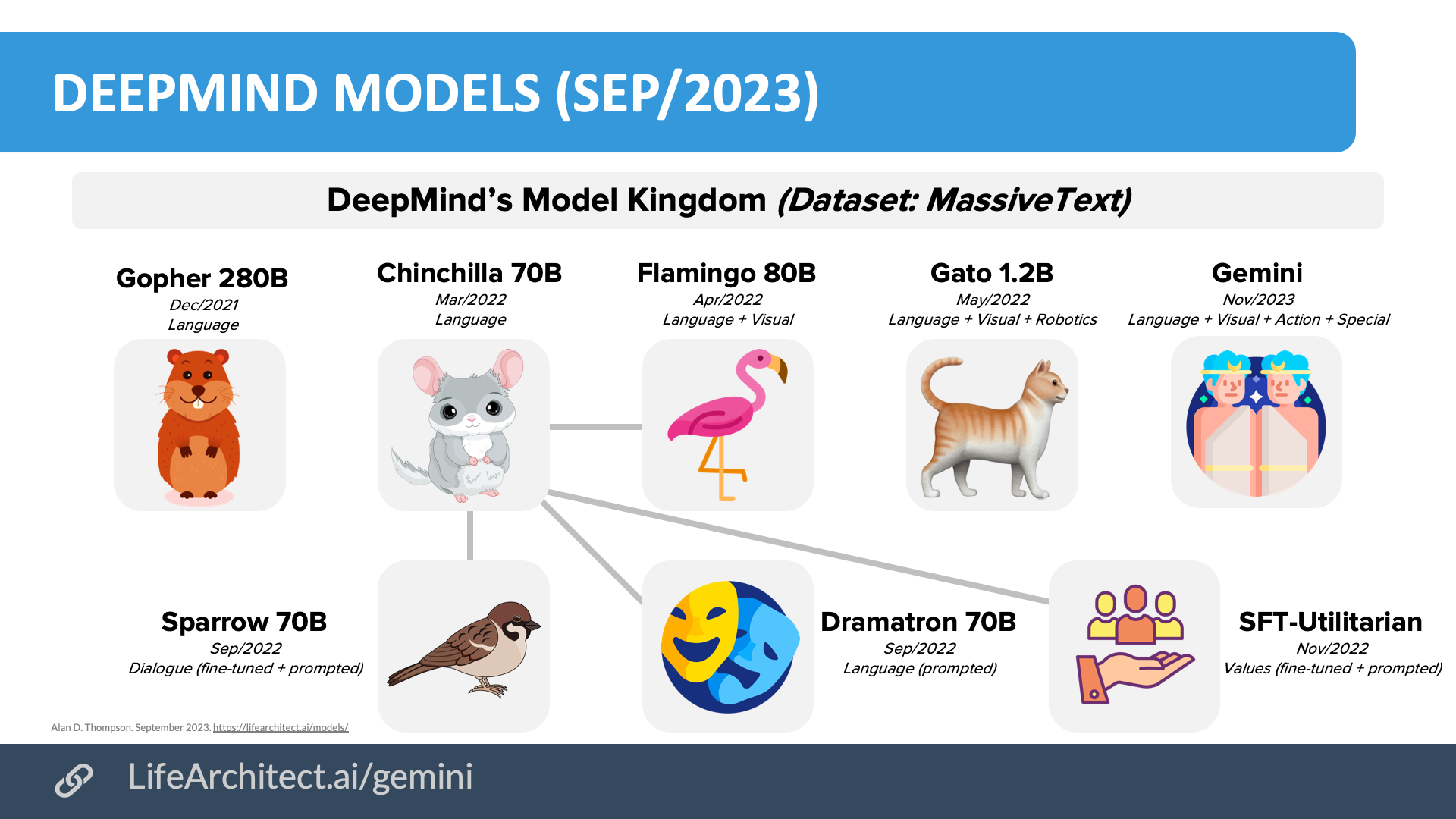
DeepMind models
AI Race
 Download source (PDF)
Download source (PDF)
Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Video
AGI
Read more about Alan’s conservative countdown to AGI…
Get The Memo
by Dr Alan D. Thompson · Be inside the lightning-fast AI revolution.Informs research at Apple, Google, Microsoft · Bestseller in 152 countries.
Artificial intelligence that matters, as it happens, in plain English.
Get The Memo.
 Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.
Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.This page last updated: 26/Jun/2026. https://lifearchitect.ai/gemini/↑




