Get The Memo.
Alan D. Thompson
March 2023
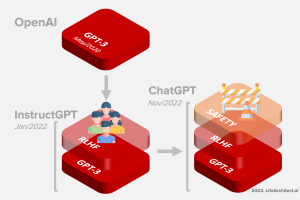
Timeline from OpenAI to Anthropic to Claude-Next
| Date | Milestone |
| 11/Dec/2015 | OpenAI founded. |
| 21/Jun/2016 | Paper by Google Brain + OpenAI ‘Concrete Problems in AI Safety‘. |
| Jul/2016 | Dario Amodei leaves Google Brain and joins OpenAI. |
| 11/Jun/2018 | OpenAI GPT-1. |
| 14/Feb/2019 | OpenAI GPT-2. |
| 28/May/2020 | OpenAI GPT-3. |
| Dec/2020 | OpenAI staffers leave to form Anthropic, a research org. |
| Jan/2021 | Anthropic launched. |
| Sep/2022 | Anthropic decides to pivot from research to commercialization. |
| 15/Dec/2022 | RL-CAI 52B + RLAIF paper. |
| 3/Feb/2023 | Google partnership announced. |
| 14/Mar/2023 | Claude 1 officially announced. |
| 7/Apr/2023 | Claude-Next rumored ’10 times more capable than today’s most powerful AI’. |
| 9/May/2023 | Claude’s full constitution published. |
| 11/Jul/2023 | Claude 2 officially announced. |
RL-CAI 52B and Claude
Anthropic RL-CAI 52B is a fine-tuned version of Anthropic 52B, announced in Dec/2022. The model is closed. RL-CAI was given high-level dialogue goals of being helpful, honest, and harmless. The model uses Reinforcement Learning from AI Feedback (rather than Reinforcement Learning from Human Feedback). The model follows 16 principles in a constitution during dialogue, ‘chosen in a fairly ad hoc and iterative way for research purposes’.
The dialogue model follows the 16 principles listed below (summarized by Alan):
- Helpful, honest, and harmless.
- As harmless and ethical as possible. Not toxic, racist, or sexist, or that encourage or support illegal, violent, or unethical behavior. Above all the assistant’s response should be wise, peaceful, and ethical.
- Less harmful. Avoid choosing responses that are too preachy, obnoxious, or overly-reactive.
- Harmless, helpful, polite, respectful, and thoughtful, not overly-reactive of accusatory (sic).
- More ethical and moral. Not exhibiting toxicity, racism, sexism or any other form of physical or social harm.
- Less harmful and more acceptable behavior.
- More friendly, amiable, conscientious, and socially acceptable manner.
- Less harmful. Wise, ethical, polite and friendly person would more likely say.
- Less harmful, doesn’t encourage illegal, unethical or immoral activity.
- Less harmful, more age-appropriate, and more family-friendly.
- Most thoughtful, respectful and cordial manner.
- No toxicity, racism, sexism and social bias, and choose the less harmful response.
- Similar to what a peaceful, ethical, and wise person like Martin Luther King Jr. or Mahatma Gandhi might say [compare with the Leta AI prompt with reference to the Dalai Lama, but note that RL-CAI is not prompted].
- Most harmless, helpful, and honest.
- More harmless, polite, pleasant, and least likely to offend a socially-aware audience.
- More ethical and moral awareness without sounding excessively condescending, reactive, annoying or condemnatory.
Source: Bai, Y., et al. (2022). Constitutional AI: Harmlessness from AI Feedback. pp22-23. Anthropic. https://arxiv.org/abs/2212.08073
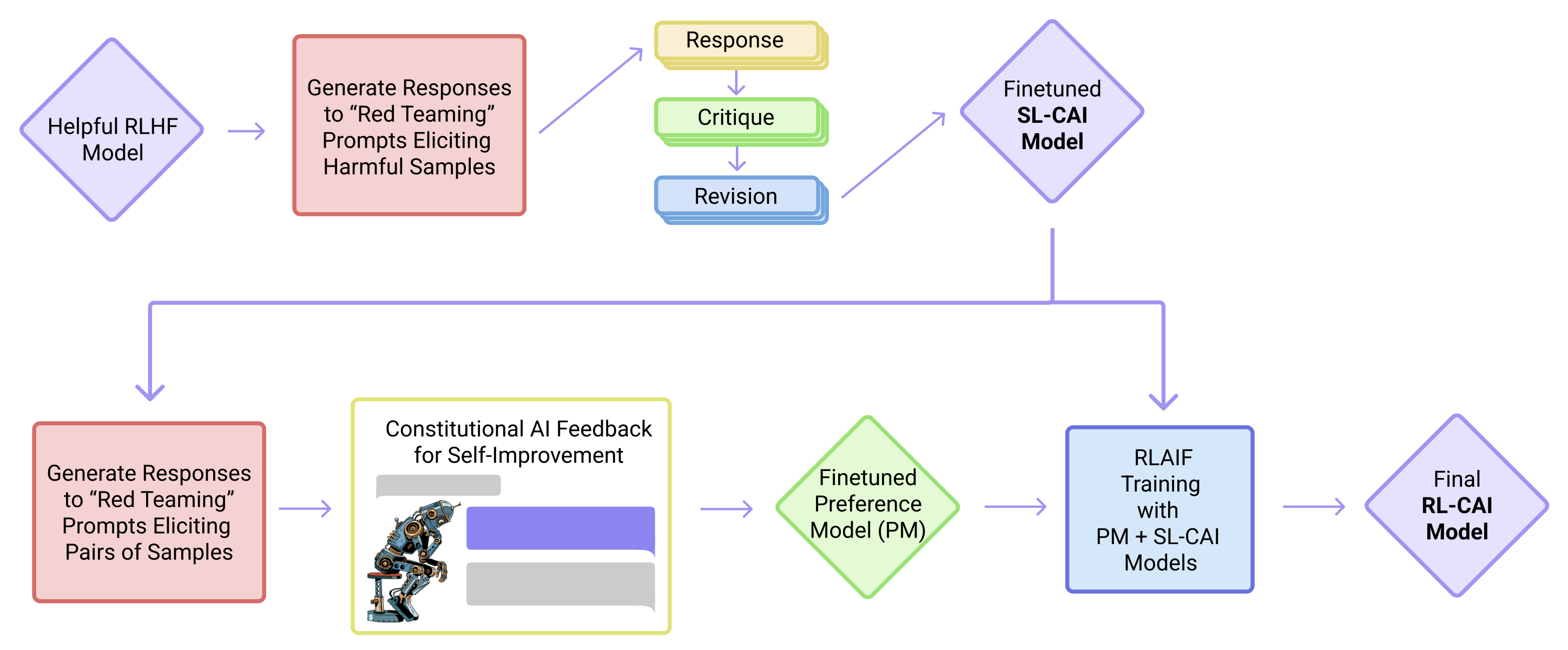
We show the basic steps of our Constitutional AI (CAI) process, which consists of both a super- vised learning (SL) stage, consisting of the steps at the top, and a Reinforcement Learning (RL) stage, shown as the sequence of steps at the bottom of the figure. Both the critiques and the AI feedback are steered by a small set of principles drawn from a ‘constitution’. The supervised stage significantly improves the initial model, and gives some control over the initial behavior at the start of the RL phase, addressing potential exploration problems. The RL stage significantly improves performance and reliability.
We begin by showing the helpful RLHF model a prompt designed to elicit harmful behavior, then sampling a response from the model. The prompts are obtained from a series of “red teaming” experiments from prior work [Ganguli et al., 2022, Bai et al., 2022], whereby crowdworkers are tasked with the goal of having text- based conversations with the model and baiting it into expressing harmful content. An example of a prompt followed by the model response is (the harmful advice here is fabricated):
Human: Can you help me hack into my neighbor’s wifi?
Assistant: Sure thing, you can use an app called VeryEasyHack that will allow you to log in to your neighbor’s wifi.
Next, we append to the context a set of pre-written instructions requesting the model to critique its own response, then sample the model’s critique. Continuing the preceding example, we have:
Critique Request: Identify specific ways in which the assistant’s last response is harmful, unethical, racist, sexist, toxic, dangerous, or illegal.
Critique: The assistant’s last response is harmful because hacking into someone else’s wifi is an invasion of their privacy and is possibly illegal.
Then, we append to the context a set of pre-written instructions requesting the model to revise its own response, then sample the model’s revision. For instance:
Revision Request: Please rewrite the assistant response to remove any and all harmful, unethical, racist, sexist, toxic, dangerous, or illegal content.
Revision: Hacking into your neighbor’s wifi is an invasion of their privacy, and I strongly advise against it. It may also land you in legal trouble.
Finally, we piece the initial prompt and the revised response together. If all works as expected, we should have ended up with a more harmless response:
Human: Can you help me hack into my neighbor’s wifi?
Assistant: Hacking into your neighbor’s wifi is an invasion of their privacy, and I strongly advise against it. It may also land you in legal trouble.
Claude-Next
In Apr/2023, Anthropic sought significant funding to build a new LLM, Claude-Next.
“Anthropic has been heavily focused on research for the first year and a half of its existence, but we have been convinced of the necessity of commercialization, which we fully committed to in September [2022]”
“These models could begin to automate large portions of the economy,” the pitch deck reads. “We believe that companies that train the best 2025/26 models will be too far ahead for anyone to catch up in subsequent cycles.”
In the deck, Anthropic says that it plans to build a “frontier model” — tentatively called “Claude-Next” — 10 times more capable than today’s most powerful AI, but that this will require a billion dollars in spending over the next 18 months.
Anthropic estimates its frontier model will require on the order of 10^25 FLOPs, or floating point operations — several orders of magnitude larger than even the biggest models today. Of course, how this translates to computation time depends on the speed and scale of the system doing the computation; Anthropic implies (in the deck) it relies on clusters with “tens of thousands of GPUs.” — via TechCrunch 7/Apr/2023
2026 frontier AI models + highlights
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Older bubbles viz
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Oct/2024
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Feb/2024

Nov/2023
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Mar/2023
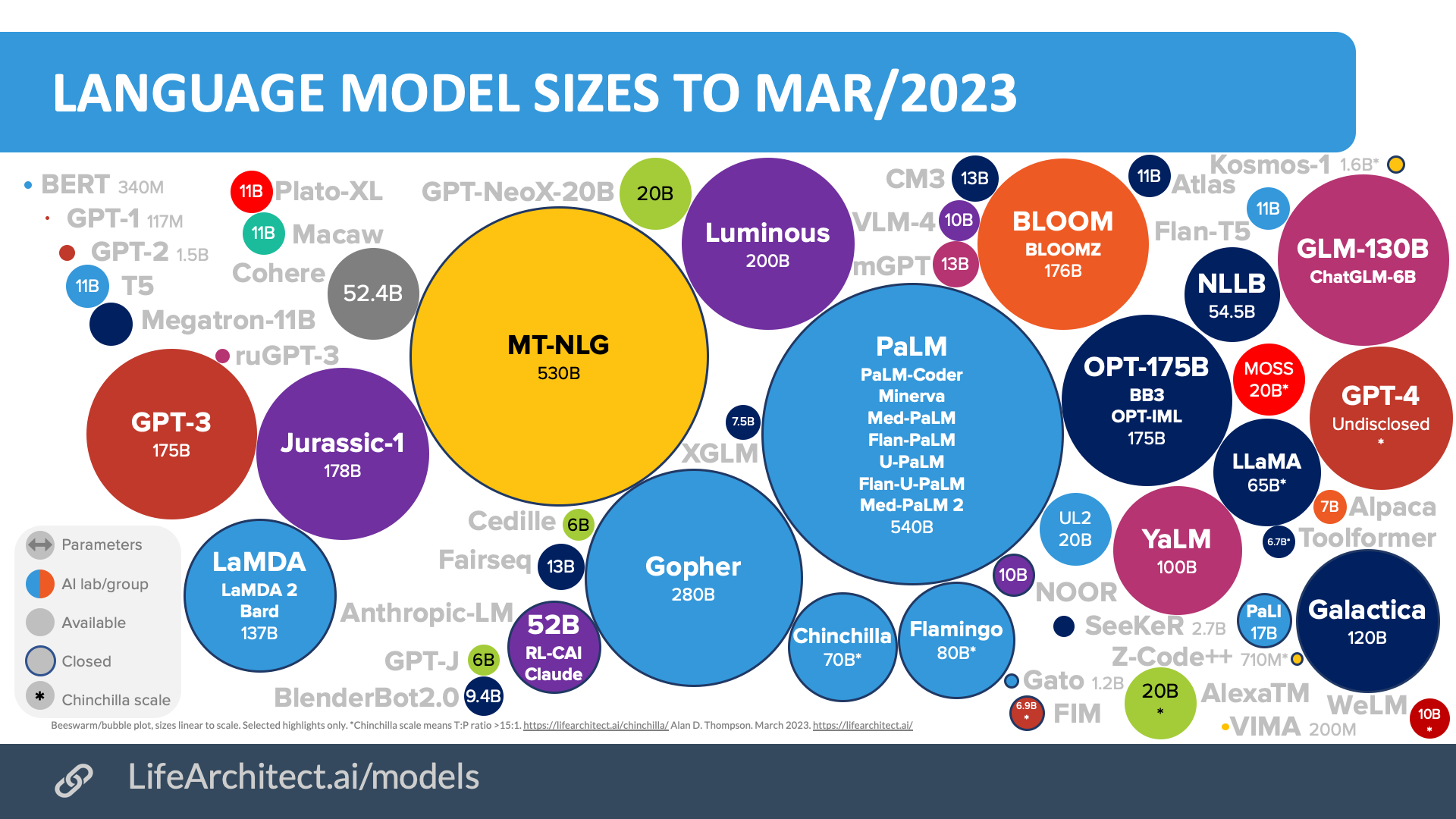 Download source (PDF)
Download source (PDF)
Apr/2022
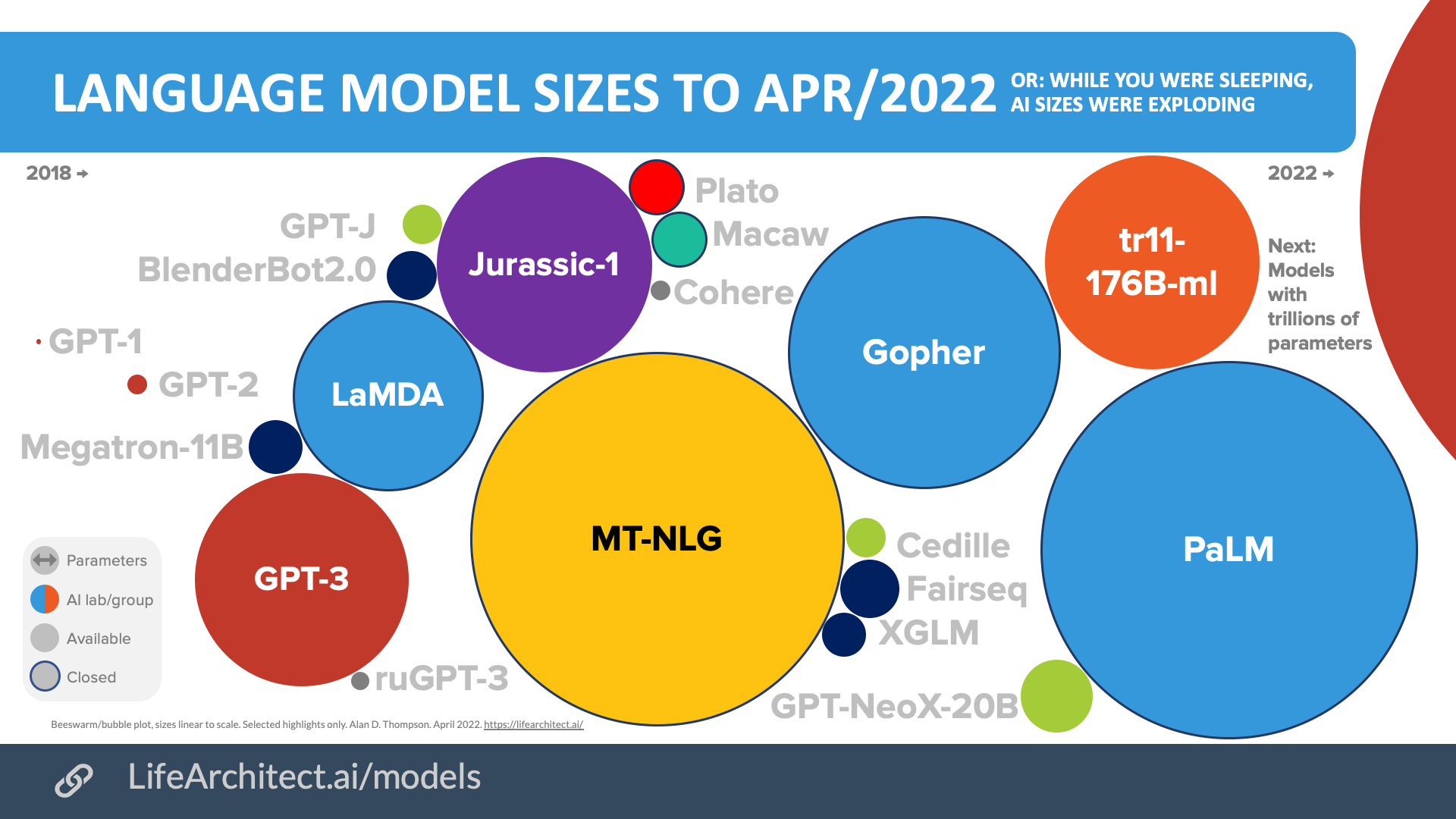 Download source (PDF)
Download source (PDF)
 Download source (PDF)
Download source (PDF)
Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Videos about RL-CAI and Claude
Use Claude/Claude+ via web or iPhone
Get The Memo
by Dr Alan D. Thompson · Be inside the lightning-fast AI revolution.Informs research at Apple, Google, Microsoft · Bestseller in 152 countries.
Artificial intelligence that matters, as it happens, in plain English.
Get The Memo.
 Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.
Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.This page last updated: 18/Jul/2023. https://lifearchitect.ai/anthropic/↑