
Get The Memo.
Summary
| Organization | OpenAI |
| Model name | GPT-6 |
| Internal/project name | |
| Model type | Multimodal |
| Parameter count | Available to Institutional clients. |
| Dataset size (tokens) | Available to Institutional clients. |
| Training data end date | 2026 (est) + Real-time learning |
| Training start date | Dec/2025 (est) |
| Training end/convergence date | Mar/2026 (source) |
| Training time (total) | Available to Institutional clients. |
| Release date (public) | 2026 |
| Paper | – |
| Playground | – |
Scaling reinforcement learning (May/2025)
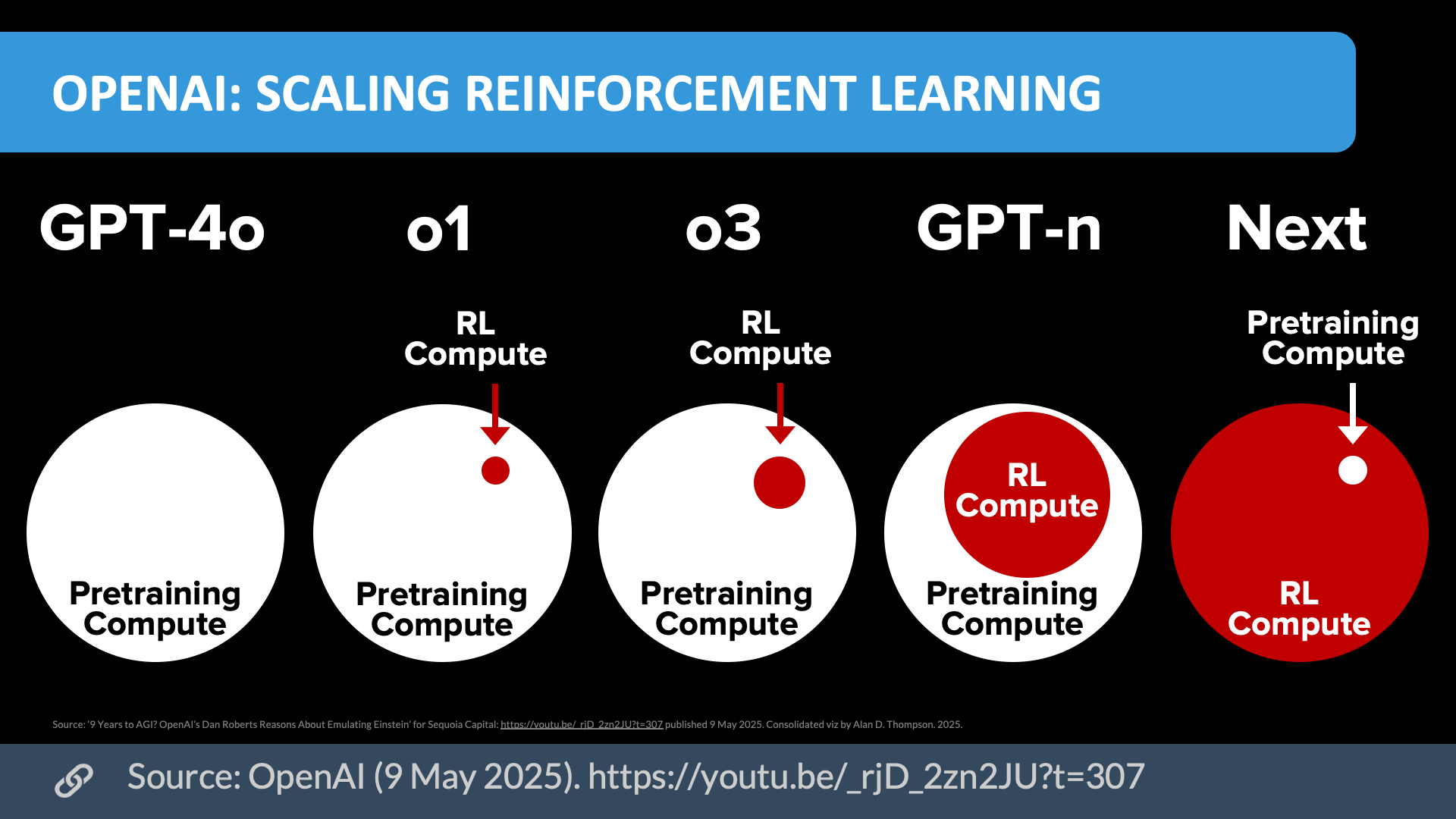 Download source (PDF)
Download source (PDF)
Source: OpenAI (9/May/2025). Permissions: Yes, you can use these visualizations anywhere, cite them.
2026 frontier AI models + highlights
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Older bubbles viz
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Oct/2024
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Feb/2024

Nov/2023
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Mar/2023
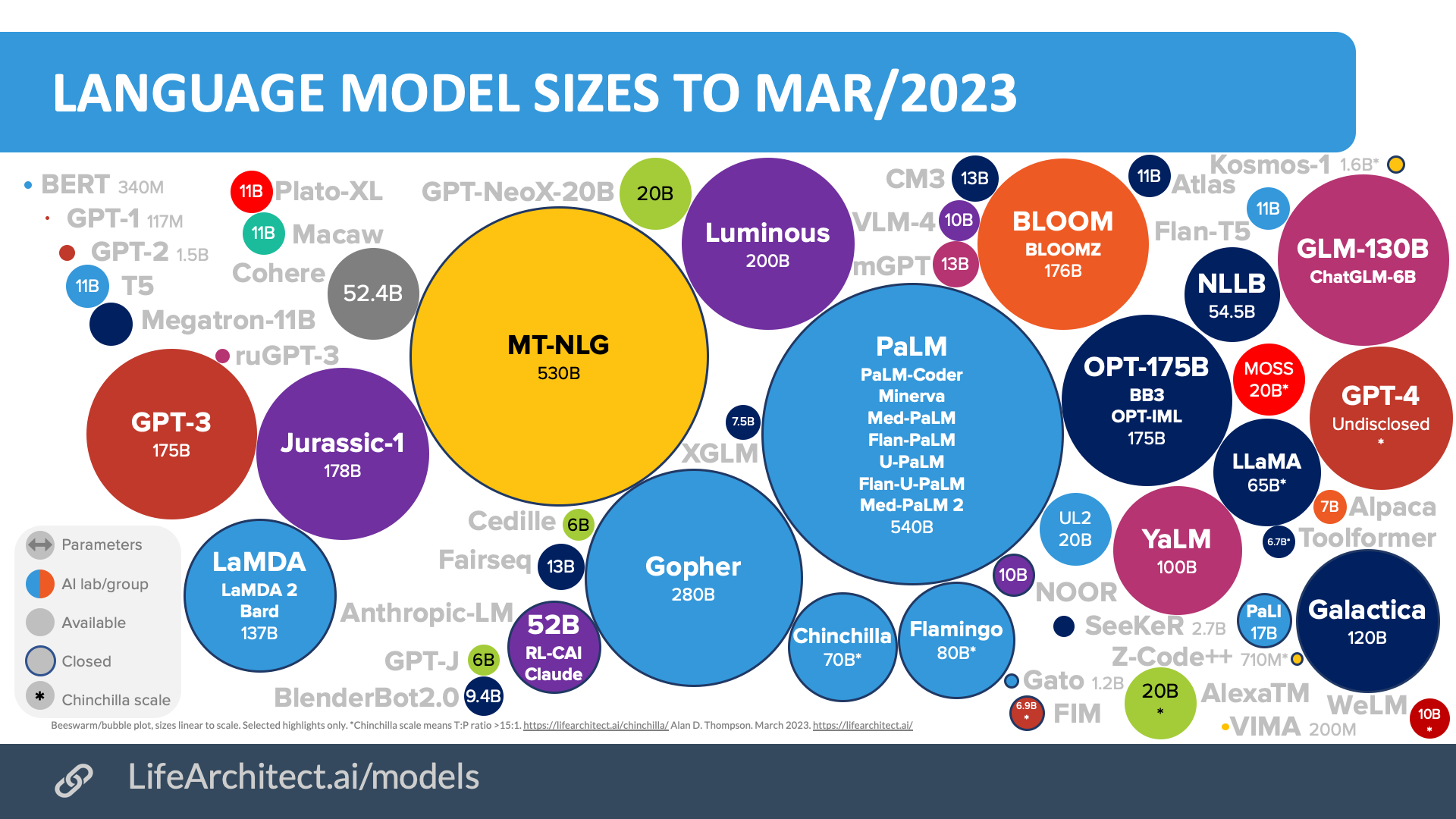 Download source (PDF)
Download source (PDF)
Apr/2022
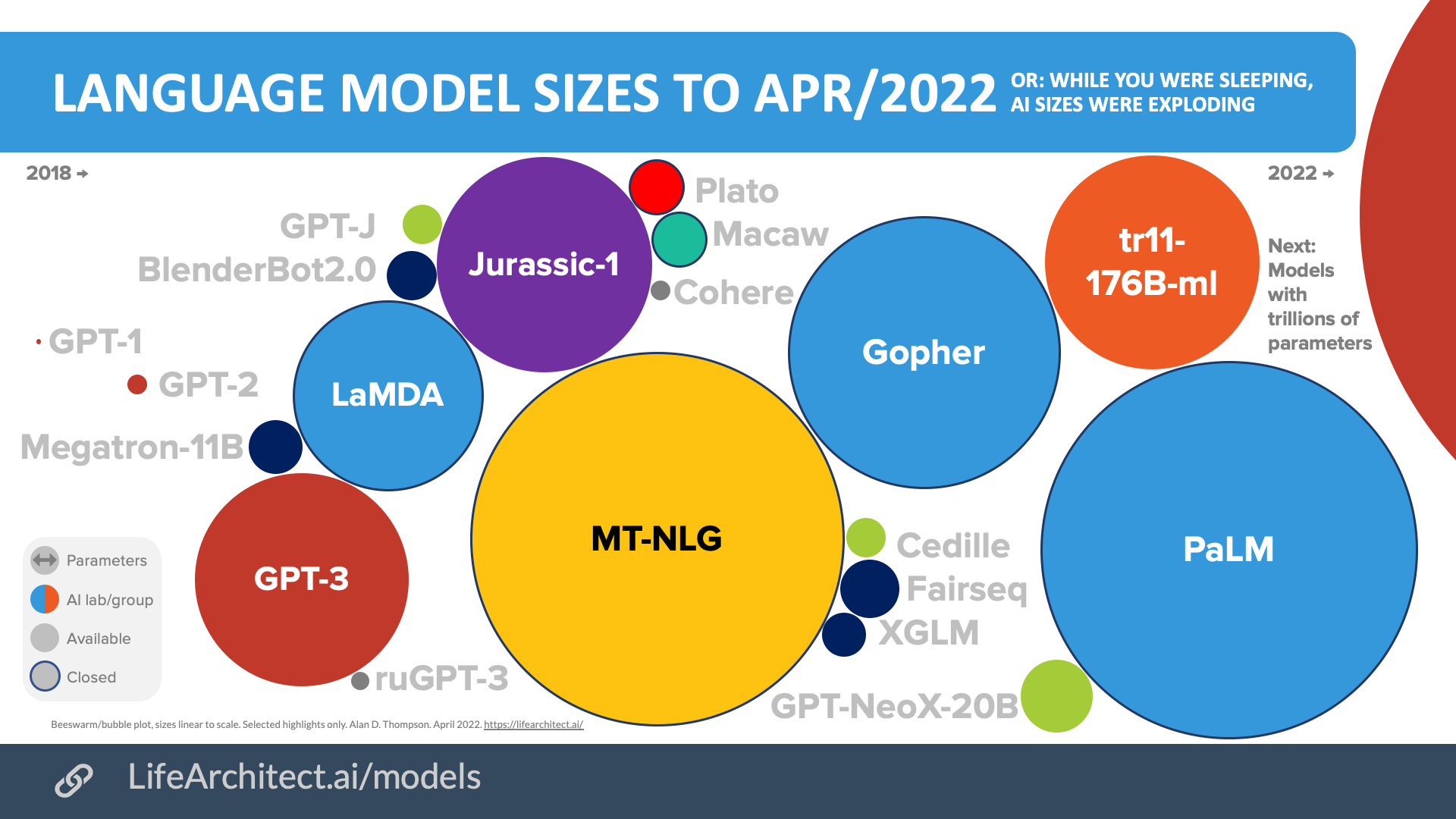 Download source (PDF)
Download source (PDF)
Major step changes in LLM capability
 Video loop, download source (PDF)
Video loop, download source (PDF)
GPT-6 Updates
2/Apr/2026: OpenAI President, Greg Brockman:
I think of Spud [GPT-5.5] as a new base, as a new pre-train… we have maybe two years’ worth of research that is coming to fruition in this model. It’s going to be very exciting, and I think that the way that the world will experience it is just improved capabilities. (2/Apr/2026)
(Sidenote: Spud was the internal codename for GPT-5.5, released on 23/Apr/2026.)
2/Apr/2026: OpenAI CEO for Laurie Segall:
We have a few times in our history realized something really important is working or about to work so well that we have to stop a bunch of other projects. In fact, this was the original thing that happened with GPT-3. We had a whole portfolio of bets at the time. A lot of them were working well.
We shut down many projects that were working well, like robotics, which we mentioned, so that we could concentrate our compute, our researchers, our effort into this thing that we said, ‘okay, there’s a very important thing happening’.
I did not expect three or six months ago to be at this point we’re at now, where something very big and important is about to happen again with this next generation of models and the agents they can power.
But I love Sora. I love generated videos and I love our partnership with Disney and we’re working hard with them to find a world where they can still do something amazing and we can help with that.
But we need to concentrate our compute and our product capacity into these next generation of automated researchers and companies. And it’s like the note under the note is ‘it’s about compute’. It’s always about compute. (2/Apr/2026)
12/Mar/2026: OpenAI CEO at BlackRock’s US Infrastructure Summit in Washington, DC, for DRM News:
We are training right now on the first site in Abilene [Texas] what I think will be the best model in the world hopefully by a lot [likely the GPT-6 model]. (12/Mar/2026)
19/Aug/2025: OpenAI CEO for CNBC:
…he made clear that GPT-6 will be different and that it will arrive faster than the gap between GPT-4 and GPT-5. It won’t just respond to users but will adapt to them, and allow people to create chatbots that mirror personal tastes.
He said he sees memory as the key for making ChatGPT truly personal. It needs to remember who you are — your preferences, routines and quirks — and adapt accordingly.
“People want memory,” Altman said. “People want product features that require us to be able to understand them.”
He said OpenAI has been working closely with psychologists to help shape the product, measuring how people feel while tracking well-being over time. The company hasn’t made that data public, but Altman indicated it might.
He’s looking to the future and brain-computer interfaces. Altman said he finds “neural interfaces a cool idea” and imagines being able to “think something and have ChatGPT respond.”
“There are a few areas adjacent to AI that I think are worth us doing something, and this is one of them,” he said, adding that he’s also interested in energy, novel substrates, robots and faster ways to build data centers.
For now, OpenAI’s core consumer product remains ChatGPT, and Altman said he’s focused on making it more flexible and more useful in daily life. He said he already relies on it for everything from work to parenting questions.
He said, however, that there are limits.
“The models have already saturated the chat use case,” Altman said. “They’re not going to get much better. … And maybe they’re going to get worse.”
(19/Aug/2025)
Jul/2025: Stargate advances:
“Together with our Stargate I site in Abilene, Texas, this additional partnership with Oracle will bring us to over 5 gigawatts of Stargate AI data center capacity under development, which will run over 2 million chips… Oracle began delivering the first Nvidia GB200 racks last month [Jun/2025] and we recently began running early training and inference workloads, using this capacity to push the limits of OpenAI’s next-generation frontier research.” (OpenAI, 22/Jul/2025)
Feb/2025: OpenAI Stargate potential datacentre locations.
2/Feb/2025: OpenAI CEO: 'GPT-3 and GPT-4 are pre-training paradigms. GPT-5 and GPT-6, which will be developed in the future, will utilize reinforcement learning and will be like discovering new science, such as new algorithms, physics, and biology.' (translated from Japanese, 2/Feb/2025, Tokyo)
8/Oct/2024: First DGX B200s delivered to OpenAI for GPT-6 (2026) 'Look what showed up at our doorstep. Thank you to NVIDIA for delivering one of the first engineering builds of the DGX B200 to our office.' (Twitter)

26/Mar/2024: Former Google engineer Kyle Corbitt (Twitter, 26/Mar/2024): 'Spoke to a Microsoft engineer on the GPT-6 training cluster project. He kvetched about the pain they're having provisioning infiniband-class links between GPUs in different regions. Me: "why not just colocate the cluster in one region?" Him: "Oh yeah we tried that first. We can't put more than 100K H100s in a single state without bringing down the power grid." 🤯'
Spoke to a Microsoft engineer on the GPT-6 training cluster project. He kvetched about the pain they're having provisioning infiniband-class links between GPUs in different regions.
Me: "why not just colocate the cluster in one region?"
Him: "Oh yeah we tried that first. We…— Kyle Corbitt (@corbtt) March 25, 2024
NVIDIA H100 @ 700W x 100,000 = 70,000,000W = 70,000kW = 70MW. Claude 3 Opus said:
70 megawatts (MW) is a significant amount of power. To put it in perspective, this is roughly the amount of electricity needed to power a small city or a large town.
For example, a city with around 70,000 households, assuming an average household consumes about 1 kW consistently, would require approximately 70 MW of power.
And, as detailed in The Memo edition 2/Dec/2023, Microsoft does indeed have an extra 150,000 H100s as of 2023:
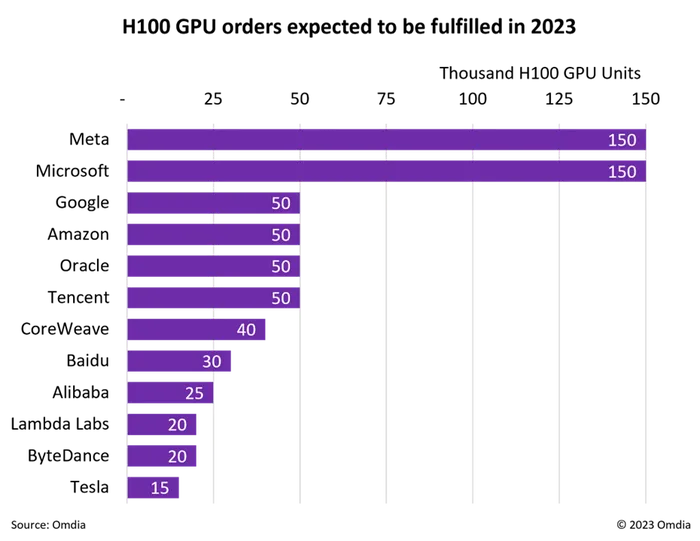
18/Mar/2024: CNBC: NVIDIA said Amazon Web Services would build a server cluster with 20,000 GB200 chips. NVIDIA said that the system can deploy a 27-trillion-parameter model… (18/Mar/2024).
Models Table
Summary of current models: View the full data (Google sheets)Dataset
 A Comprehensive Analysis of Datasets Likely Used to Train GPT-5
A Comprehensive Analysis of Datasets Likely Used to Train GPT-5
Alan D. Thompson
LifeArchitect.ai
August 2024
27 pages incl title page, references, appendices.
Timeline to GPT-6
| Date | Milestone |
| 11/Jun/2018 | GPT-1 announced on the OpenAI blog. |
| 14/Feb/2019 | GPT-2 announced on the OpenAI blog. |
| 28/May/2020 | GPT-3 preprint paper published to arXiv. |
| 11/Jun/2020 | GPT-3 API private beta. |
| 22/Sep/2020 | GPT-3 licensed exclusively to Microsoft. |
| 18/Nov/2021 | GPT-3 API opened to the public. |
| 27/Jan/2022 | InstructGPT released as text-davinci-002, later known as GPT-3.5. InstructGPT preprint paper Mar/2022. |
| 28/Jul/2022 | Exploring data-optimal models with FIM, paper on arXiv. |
| Aug/2022 | GPT-4 finished training, available in lab. |
| 1/Sep/2022 | GPT-3 model pricing cut by 66% for davinci model. |
| 21/Sep/2022 | Whisper (speech recognition) announced on the OpenAI blog. |
| 28/Nov/2022 | GPT-3.5 expanded to text-davinci-003, announced via email: 1. Higher quality writing. 2. Handles more complex instructions. 3. Better at longer form content generation. |
| 30/Nov/2022 | ChatGPT announced on the OpenAI blog. |
| 14/Mar/2023 | GPT-4 released. |
| 31/May/2023 | GPT-4 MathMix and step by step, paper on arXiv. |
| 6/Jul/2023 | GPT-4 available via API. |
| 25/Sep/2023 | GPT-4V released. |
| 13/May/2024 | GPT-4o announced. |
| 18/Jul/2024 | GPT-4o mini announced. |
| 12/Sep/2024 | o1 released. |
| 20/Dec/2024 | o3 announced. |
| 27/Feb/2025 | GPT-4.5 released. |
| 14/Apr/2025 | GPT-4.1 released. |
| 16/Apr/2025 | o3 released. |
| 16/Apr/2025 | o4-mini released. |
| 5/Aug/2025 | gpt-oss-120b and gpt-oss-20b released. |
| 7/Aug/2025 | GPT-5 released. |
| 12/Nov/2025 | GPT-5.1 released. |
| 11/Dec/2025 | GPT-5.2 released. |
| 5/Feb/2026 | GPT-5.3-Codex released. |
| 5/Mar/2026 | GPT-5.4 released. |
| Mar/2026 | ‘Spud’ finished training, available in lab. |
| 23/Apr/2026 | GPT-5.5 released. |
| 12/Jun/2026 | Anthropic Claude Fable 5 and Mythos 5 suspended. US government export control directive citing national security blocks models by names 'Mythos 5' and 'Fable 5'. 200+ companies retain access during this time. |
| 26/Jun/2026 | GPT-5.6 Sol announced. |
| 9/Jul/2026 | GPT-5.6 Sol released. |
| 2026 | GPT-6 due… |
| 2027 | GPT-7 due… |
Get The Memo
by Dr Alan D. Thompson · Be inside the lightning-fast AI revolution.Informs research at Apple, Google, Microsoft · Bestseller in 152 countries.
Artificial intelligence that matters, as it happens, in plain English.
Get The Memo.
 Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.
Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.This page last updated: 30/Jun/2026. https://lifearchitect.ai/gpt-6/↑


