
Get The Memo.
Summary
| Organization | OpenAI |
| Model name | GPT-5 |
| Internal/project name | Gobi, Arrakis |
| Model type | Multimodal |
| Parameter count | ~300B. See What’s in GPT-5? |
| Dataset size (tokens) | ~114T. See What’s in GPT-5? |
| Training data end date | Sep/2024 |
| Training start date | Jan/2025 |
| Training end/convergence date | Apr/2025 |
| Training time (total) | 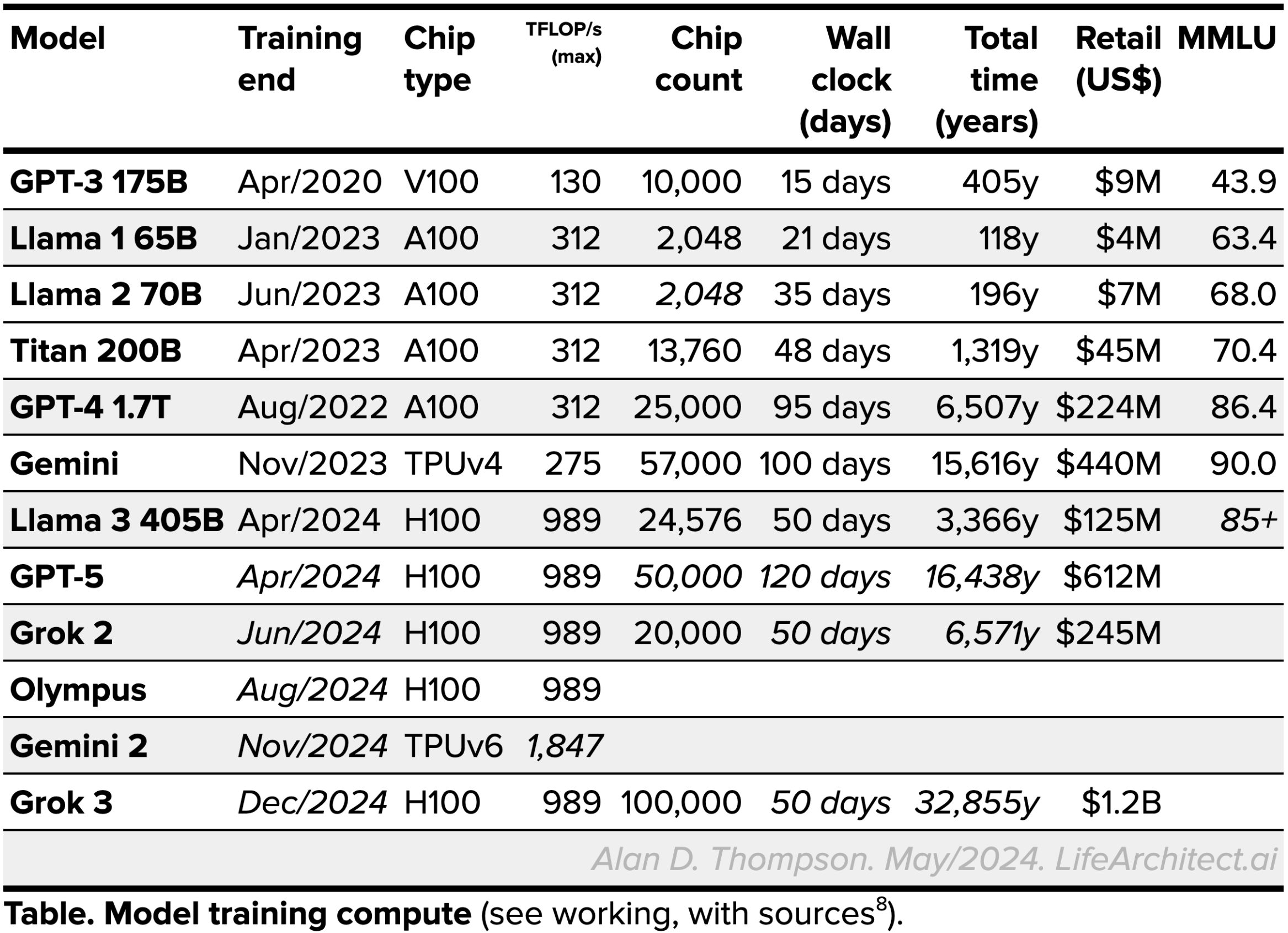 See working, with sources.
See working, with sources. |
| Release date (public) | 7/Aug/2025 |
| Paper | https://openai.com/index/gpt-5-system-card/ |
| Playground | chat.com |
Viz
Frontier model sizes: Estimates through the price data lens (2024–2025)
OpenAI GPT families 2018–2026 (simple)
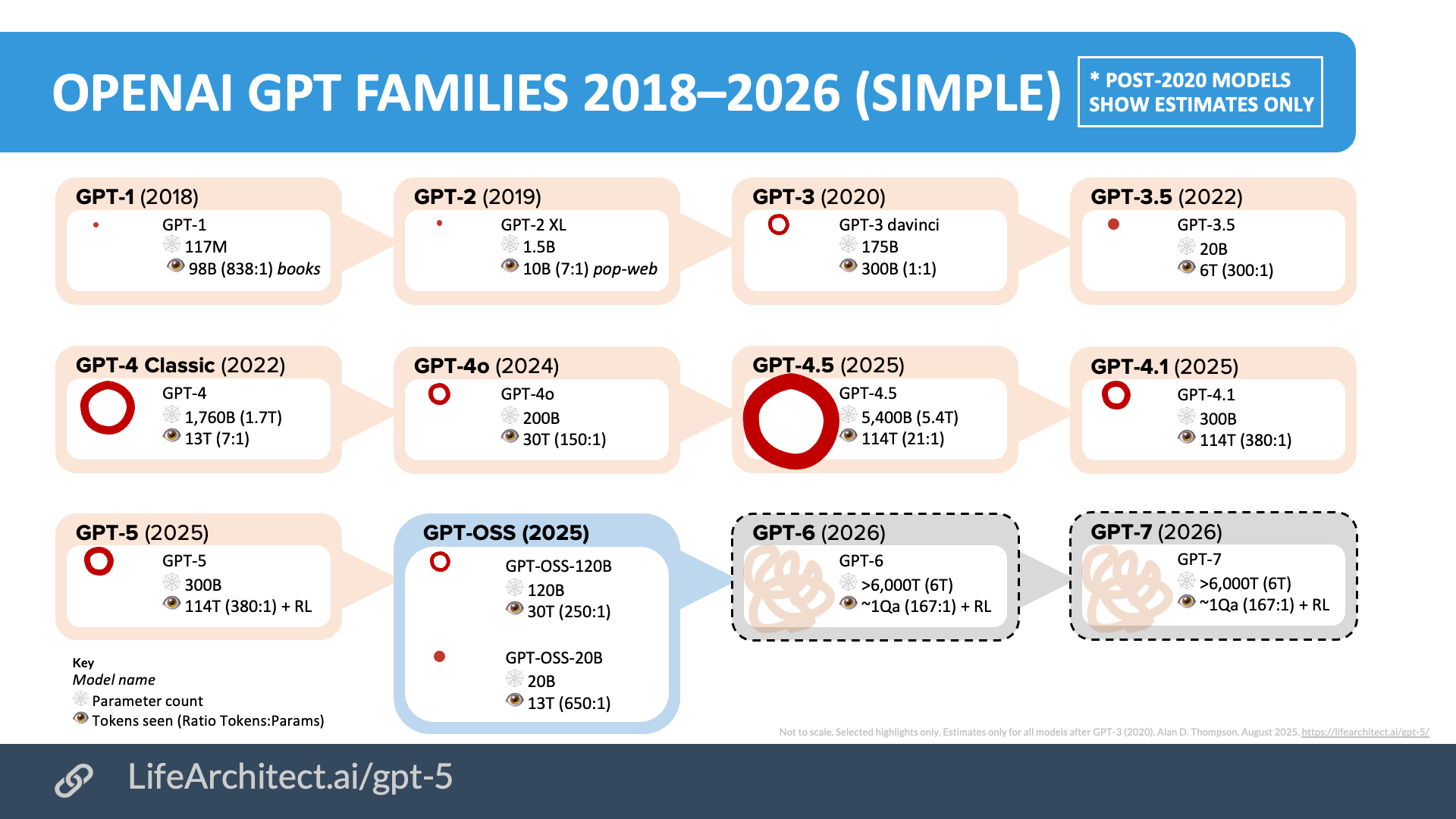 Download source (PDF) and view the complete version
Download source (PDF) and view the complete version
Scaling reinforcement learning (May/2025)
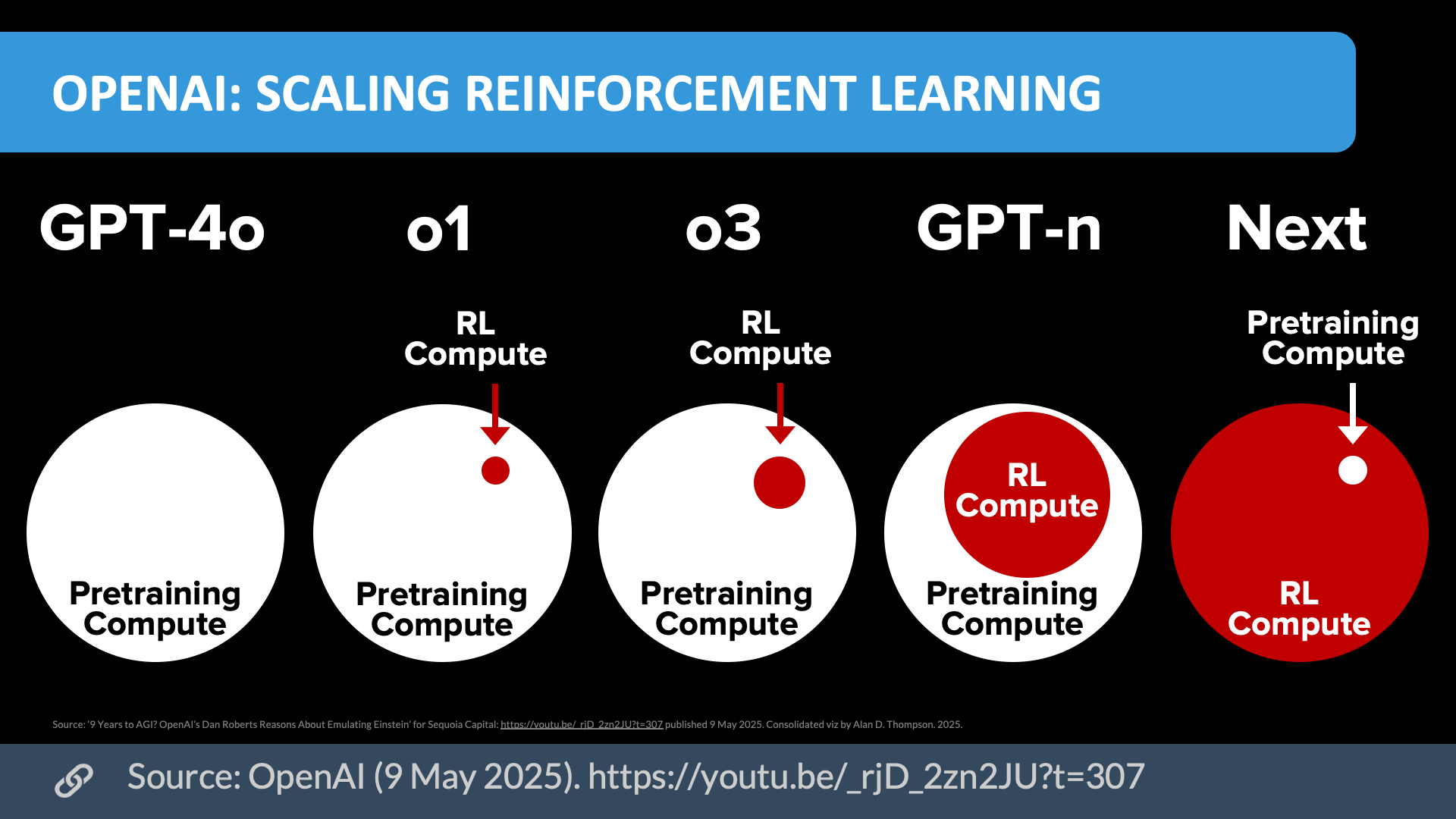 Download source (PDF)
Download source (PDF)
Source: OpenAI (9/May/2025). Permissions: Yes, you can use these visualizations anywhere, cite them.
GPQA bubbles
 Download source (PDF)
Download source (PDF)
The GPT-4x and o Model Family: Varied Intelligence Scores 2024–2025
 View interactive chart in new tab
View interactive chart in new tab
Modalities

2026 frontier AI models + highlights
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Older bubbles viz
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Oct/2024
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Feb/2024

Nov/2023
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Mar/2023
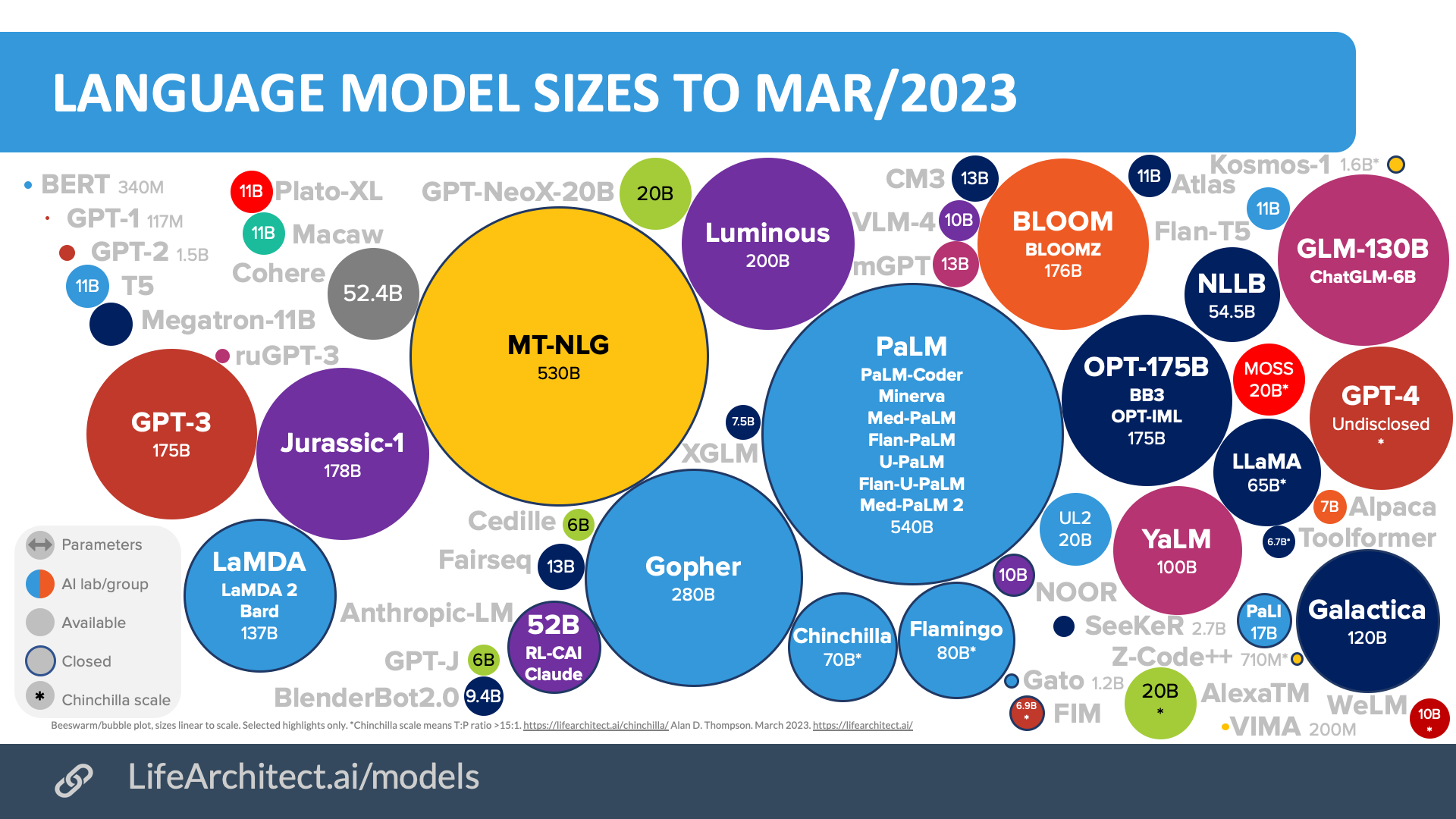 Download source (PDF)
Download source (PDF)
Apr/2022
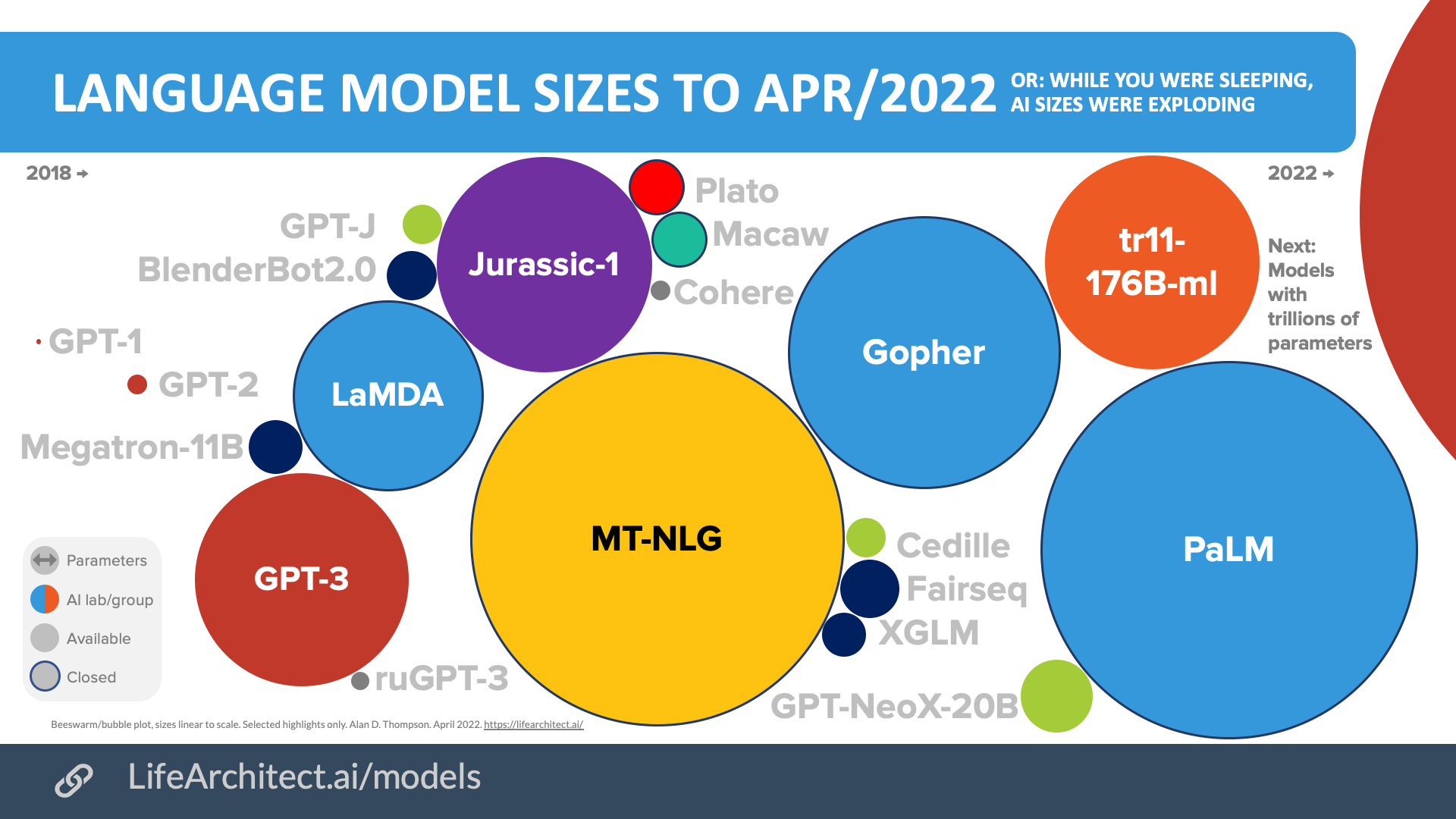 Download source (PDF)
Download source (PDF)
GPT-5 Updates
7/Aug/2025: GPT-5 released.
Jul/2025: Stargate advances:
“Together with our Stargate I site in Abilene, Texas, this additional partnership with Oracle will bring us to over 5 gigawatts of Stargate AI data center capacity under development, which will run over 2 million chips… Oracle began delivering the first Nvidia GB200 racks last month [Jun/2025] and we recently began running early training and inference workloads, using this capacity to push the limits of OpenAI’s next-generation frontier research.” (OpenAI, 22/Jul/2025)
Apr/2025: Former OpenAI model architecture and training engineer (Oct/2024–Apr/2025), Rohan Pandey, reveals:
At OpenAI, I helped train GPT-5 and future models. (link, archive)
12/Feb/2025: OpenAI CEO:
We will next ship GPT-4.5, the model we called Orion internally, as our last non-chain-of-thought model.
After that, a top goal for us is to unify o-series models and GPT-series models by creating systems that can use all our tools, know when to think for a long time or not, and generally be useful for a very wide range of tasks.
In both ChatGPT and our API, we will release GPT-5 as a [unified model] system that integrates a lot of our technology, including o3. (Twitter, 12/Feb/2025)
2/Feb/2025: OpenAI CEO: ‘GPT-3 and GPT-4 are pre-training paradigms. GPT-5 and GPT-6, which will be developed in the future, will utilize reinforcement learning and will be like discovering new science, such as new algorithms, physics, and biology.’ (translated from Japanese, 2/Feb/2025, Tokyo)
21/Dec/2024: Extensive GPT-5 news and updates via WSJ and MSN (21/Dec/2024):
The project, officially called GPT-5 and code-named Orion, has been in the works for more than 18 months and is intended to be a major advancement in the technology that powers ChatGPT. OpenAI’s closest partner and largest investor, Microsoft, had expected to see the new model around mid-2024, say people with knowledge of the matter.
OpenAI has conducted at least two large training runs, each of which entails months of crunching huge amounts of data, with the goal of making Orion smarter. Each time, new problems arose and the software fell short of the results researchers were hoping for, people close to the project say.
At best, they say, Orion performs better than OpenAI’s current offerings, but hasn’t advanced enough to justify the enormous cost of keeping the new model running. A six-month training run can cost around half a billion dollars in computing costs alone, based on public and private estimates of various aspects of the training.
…
From the start, there were problems with plans for GPT-5.
In mid-2023, OpenAI started a training run that doubled as a test for a proposed new design for Orion. But the process was sluggish, signaling that a larger training run would likely take an incredibly long time, which would in turn make it outrageously expensive. And the results of the project, dubbed Arrakis, indicated that creating GPT-5 wouldn’t go as smoothly as hoped.
OpenAI researchers decided to make some technical tweaks to strengthen Orion. They also concluded they needed more diverse, high-quality data. The public internet didn’t have enough, they felt.
…
In early 2024, OpenAI prepared to give Orion [GPT-5] another try, this time armed with better data. Researchers launched a couple of smaller-scale training runs over the first few months of the year to build up confidence.
By May [2024], OpenAI’s researchers decided they were ready to attempt another large-scale training run for Orion, which they expected to last through November [2024].
Once the training began, researchers discovered a problem in the data: It wasn’t as diversified as they had thought, potentially limiting how much Orion would learn. The problem hadn’t been visible in smaller-scale efforts and only became apparent after the large training run had already started. OpenAI had spent too much time and money to start over. Instead, researchers scrambled to find a wider range of data to feed the model during the training process. It isn’t clear if this strategy proved fruitful.
23/Nov/2024: Dr Kai-Fu Lee, founder of 01.AI, co-founder of Microsoft Research Asia, former VP of Google, former VP of Apple (translated to English via Recode China AI, 23/Nov/2024):
I just returned from Silicon Valley, where I met with many people. Here are some of the major insights: OpenAI still has many valuable technologies it hasn’t unveiled. We must not underestimate it. Its GPT-5 training hasn’t gone smoothly, but to secure funding, it released o1. OpenAI still holds many cards and isn’t in a rush to play them. Each time it unveils a new card, global tech companies, including those in China, observe closely, speculate, and develop competing solutions. Even if they can’t match it entirely, they can achieve 80-90% parity. Because of this, OpenAI doesn’t want to exhaust its cards prematurely. It plans to save them for when AGI seems within reach and can confidently deploy them.
…the challenges GPT-5 has faced during training suggest that the prediction of achieving AGI in three years might be overly optimistic. GPT-5 was originally supposed to be released by now, but at this rate, even if it does launch, it won’t be for another six months [Nov/2024 +6m = May/2025] at the earliest.
17/Oct/2024: OpenAI CEO: ‘We had thought at one point about, “It doesn’t fit perfectly but maybe we’ll call this [o1 model] GPT-5.” But this is a new paradigm. It’s a different way to use a model, it’s good at different things. It takes a long time for hard problems, which is annoying, but we’ll make that better. But it can do things that the GPT series just didn’t.’ (12/Sep/2024 @ UMich)
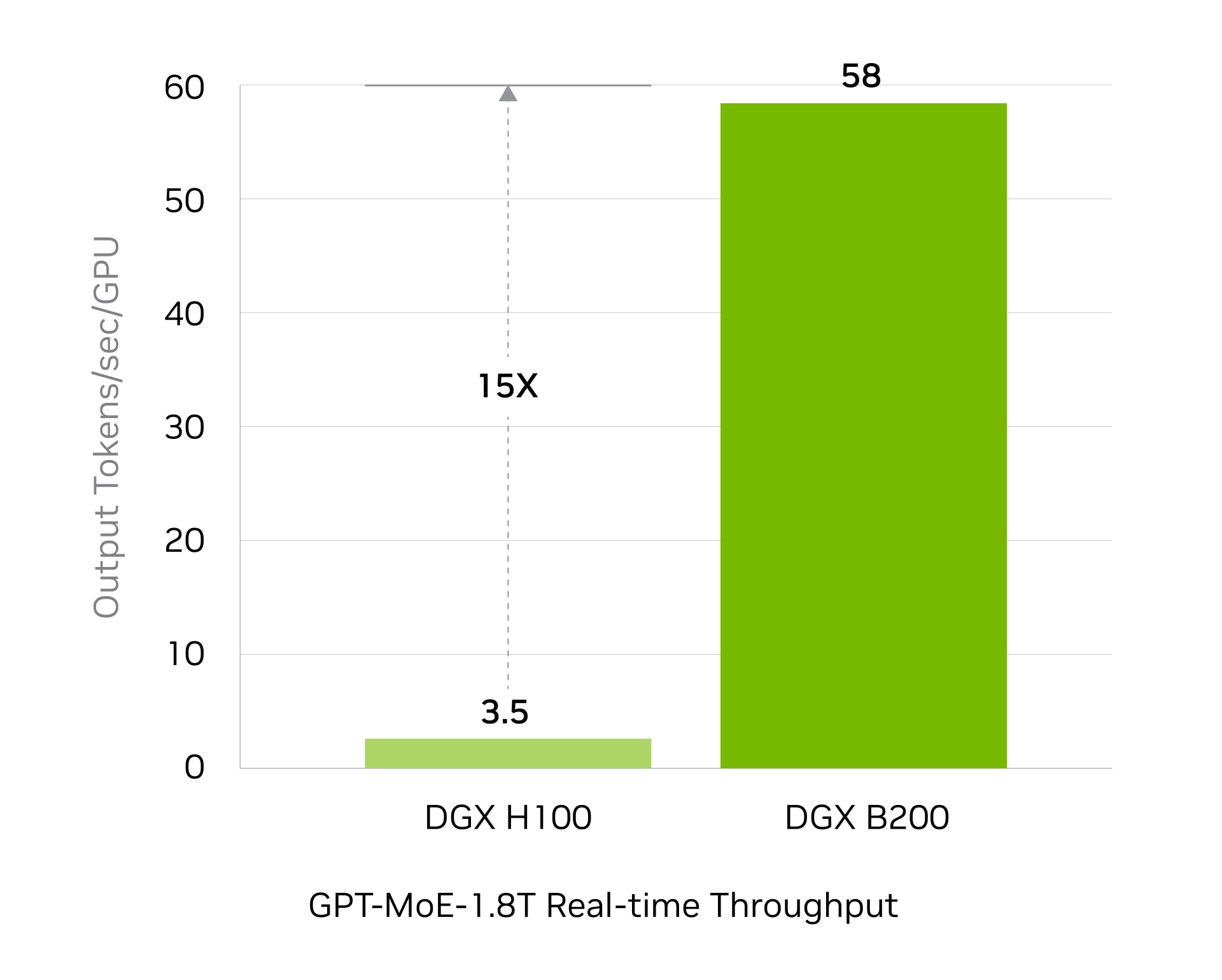
8/Oct/2024: First DGX B200s delivered to OpenAI. ‘Look what showed up at our doorstep. Thank you to NVIDIA for delivering one of the first engineering builds of the DGX B200 to our office.’ (Twitter)

As GPT-5 was trained on H100s, this B200 would be for training GPT-6 (2025), and probably also for GPT-5 inference. The chart below shows the difference in inference speed using H100 vs B200 for a model like GPT-4 1.8T MoE (NVIDIA):
4/Oct/2024: OpenAI CFO to CNBC:
10:45
There is no denying that we’re on a scaling law right now where orders of magnitude matter. The next model [GPT-5] is going to be an order of magnitude bigger, and the next one, and on and on.12:10
Interviewer: What about GPT-5? When can we expect that?Sarah: …We’re so used to technology that’s very synchronous, right? You ask a question, boom, you get an answer straight back. But that’s not how you and I might talk, right? If you called me yesterday, you might say, “Hey, prep for this.” I might take a whole day. And think about models that start to move that way, where maybe it’s much more of a long-horizon task—is the phrase we use internally. So it’s going to solve much harder problems for you, like even on the scale of things like drug discovery. So sometimes you’ll use it for easy stuff like “What can I cook for dinner tonight that would take 30 minutes?” And sometimes it’s literally “How could I cure this particular type of cancer that is super unique and only happens in children?” There’s such a breadth of what we can do here. So I would focus on these types of models and what’s coming next. It’s incredible.
Sidenote: An order of magnitude bigger than 1.76 trillion parameters MoE is 17.6 trillion parameters MoE, or around 3.5T parameters dense.
4/Sep/2024: Samsung President/Head of Memory Business Dr Jung-Bae Lee showed this slide about GPT-5 at SemiCon Taiwan: GPT-5 as 3–5T parameters, trained on 7,000× NVIDIA B100.

16/Aug/2024: Mikhail Parakhin Microsoft CEO, Advertising and Web Services: ‘In order to get some meaningful improvement, the new model should be at least 20x bigger. Training takes at least 6 months, so you need a new, 20x bigger datacenter, which takes about a year to build (actually much longer, but there is pipelining).’
Note: This is in line with my estimates for GPT-5 as covered in my paper: What’s in GPT-5?
In order to get some meaningful improvement, the new model should be at least 20x bigger. Training takes at least 6 months, so you need a new, 20x bigger datacenter, which takes about a year to build (actually much longer, but there is pipelining).
— Mikhail Parakhin (@MParakhin) August 16, 2024
16/Jul/2024: ‘Teknium’ (NousResearch, former Stability AI): “OAI is using over 50T tokens of synthetic data to pretrain gpt5… Source is not public” (Twitter)
OAI is using over 50T tokens of synthetic data to pretrain gpt5 lol
— Teknium (e/λ) (@Teknium1) July 16, 2024
1/Jun/2024: Microsoft CTO Kevin Scott again, this time at the 2024 Berggruen Salon in LA (link). Transcribed by OpenAI Whisper:
Some of the fragility in the current models [GPT-4] are it can’t solve very complicated math problems and has to bail out to other systems to do very complicated things. If you think of GPT-4 and that whole generation of models as things that can perform as well as a high school student on things like the AP exams. Some of the early things that I’m seeing right now with the new models [GPT-5] is maybe this could be the thing that could pass your qualifying exams when you’re a PhD student.
…everybody’s likely gonna be impressed by some of the reasoning breakthroughs that will happen… but the real test will be what we choose to go do with it…
The really great thing I think that has happened over the past handful of years is that it really is a platform, so the barrier to entry in AI has gone down by such a staggering degree. It’s so much easier to go pick the tools up and to use it to do something.
The barrier to entry using these tools to go solve important problems is coming down down down, which means that it’s more and more accessible to more people. That to me is exciting, because I’m not one of these people who believe that just the people in this room or just the people at tech companies in Silicon Valley or just people who’ve graduated with PhDs from top five computer science schools, know what all the important problems are to go solve. They’re smart and clever and will go solve some interesting problems but we have 8 billion people in the world who also have some idea about what it is that they want to go do with powerful tools if they just have access to them.
28/May/2024: “OpenAI has recently begun training its next frontier model and we anticipate the resulting systems to bring us to the next level of capabilities on our path to AGI. While we are proud to build and release models that are industry-leading on both capabilities and safety, we welcome a robust debate at this important moment.” (OpenAI blog)
23/May/2024: Microsoft compares frontier models to marine wildlife: shark (GPT-3), orca (GPT-4), whale (GPT-5), blah blah blah. Video (link):
I definitely don’t recommend overanalyzing what Microsoft has said, but if we did want to overanalyze(!), it might look something like this. Note that I used Claude 3 Opus for working, and the delta always uses shark (or GPT-3) as the baseline:
| Characteristic | Shark | Orca | Whale |
|---|---|---|---|
| Body weight (kg) | 500 | 5,000 | 150,000 |
| Delta | 1x | 10x | 300x |
| Brain Weight (kg) | 0.05 | 5.6 | 7.8 |
| Delta | 1x | 112x | 156x |
| Neurons | 100 million | 11 billion | 200 billion |
| Delta | 1x | 110x | 2,000x |
| Synapses | 10^13 (10 trillion) | 10^15 (1 quadrillion) | 10^16 (10 quadrillion) |
| Delta | 1x | 100x | 1,000x |
Let’s use body weight, as it’s the closest match to the known deltas (GPT-3 ➜ GPT-4) to predict GPT-5:
| Characteristic | GPT-3 | GPT-4 | GPT-5 |
|---|---|---|---|
| Parameters | 175B | 1,760B (1.76T) | 52,500B (52.5T) |
| Delta | 1x | 10x | 300x |
Pretty close. Jensen/NVIDIA reckons we easily have hardware to train a 27T parameter model using just 20,000 GB200 chips, and we know Microsoft has added another 150,000 of the ‘older’ H100s, so 50T parameters certainly isn’t out of the question…
2/May/2024: OpenAI CEO: “The most important thing to say about GPT-5 versus GPT-4 is just that it’ll be smarter. It’s not that it’s better in this way or that way. The fact that we can make progress across all model behavior and capabilities at once — I think that’s the miracle” (The Crimson)
20/Apr/2024: Dr Jason Wei at OpenAI: “Nothing gets my heart rate up like waiting for eval results on new models to come in.” (Twitter)
12/Apr/2024: Former Paypal CEO: ‘GPT-5 will be a freak out moment. 80% of the jobs out there will be reduced 80% in scope.’ (Twitter video does not match the quote)
4/Apr/2024: Unverified rumor: ‘Red teaming for GPT-5 underway.’ (Twitter)
29/Mar/2024: GPT-5 ‘coming soon’ to Double, an AI coding assistant backed by Y Combinator.

26/Mar/2024: GPT-6 preparation beginning: LifeArchitect.ai/GPT-6
18/Mar/2024: CNBC: NVIDIA said Amazon Web Services would build a server cluster with 20,000 GB200 chips. NVIDIA said that the system can deploy a 27-trillion-parameter model… (18/Mar/2024).
17/Mar/2024: Rumors that GPT-5 will be released mid-2024 (rather than the previous timeline of being delayed until after the Nov/2024 US elections).
14/Mar/2024: OpenAI CEO on GPT-5 to Korean media (14/Mar/2024):
“I don’t know when GPT-5 will be released, but it will make great progress as a model that takes a leap forward in advanced inference functions. What are the limitations of GPT? There are many questions as to whether it exists, but I will confidently say ‘no.’ We are confident that there are no limits to the GPT model and that if sufficient computational resources are invested, it will not be difficult to build AGI that surpasses humans.
“Many startups assume that the development of GPT-5 will be slow because they are happier with only a small development (since there are many business opportunities) rather than a major development, but I think it is a big mistake. When this happens, as often happens, it will be ‘steamrolled’ by the next generation model. In the past, we had a very broad picture of everything happening in the world and were able to see things that we couldn’t see from a narrow perspective, unfortunately, these days, we are completely focused on AI (AI all of the time at full tilt), so there is a different perspective. It is difficult to have.
“Other than thinking about the next generation AI model, the area where I spend the most time recently is ‘building compute,’ and I am increasingly convinced that computing will become the most important currency in the future. [But the world,] they have not planned enough computing and are not facing this problem, so there is a lot of concern about what is needed to build a huge amount of computing as cheaply as possible.
“What I am most excited about from AGI is that the faster we develop AI through scientific discoveries, the faster we will be able to find solutions to power problems by making nuclear fusion power generation a reality. Scientific research through AGI will lead to sustainable economic growth. I think it is almost the only driving force and determining factor.
“In the long run, there will be a shortage of human-generated data. For this reason, we need models that can learn more with less data.
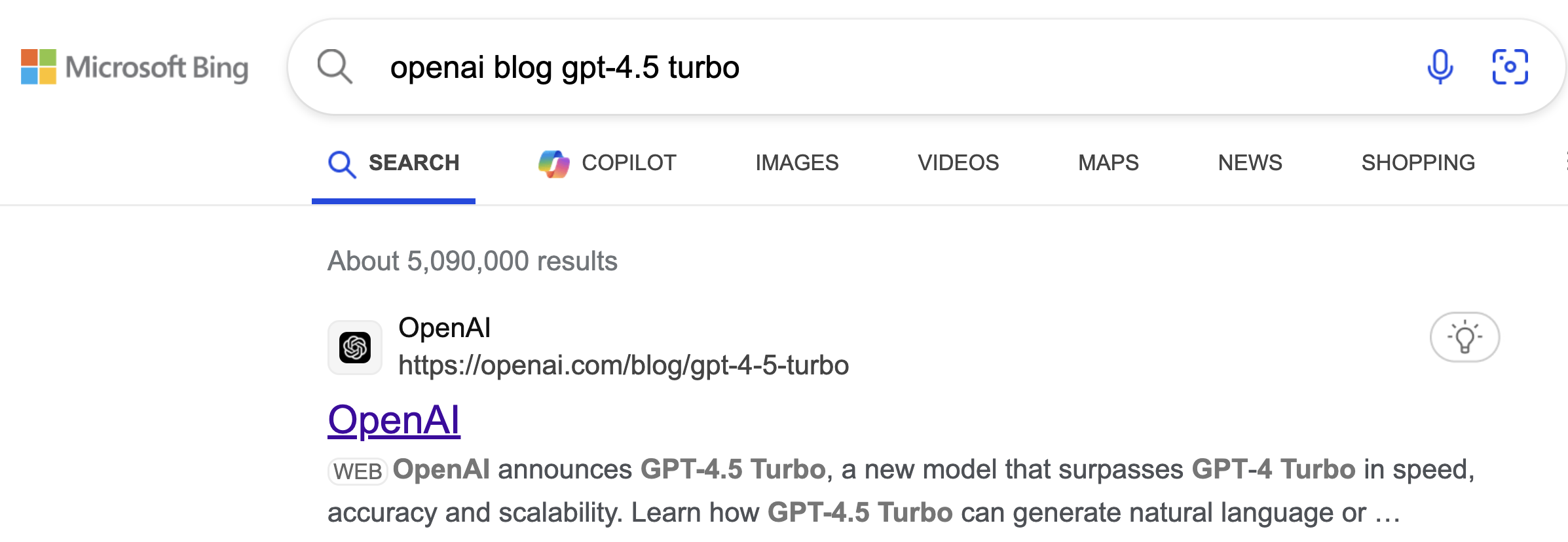
12/Mar/2024: GPT-4.5-turbo page searchable via Bing and other search engines:
8/Mar/2024: The Memo GPT-5 convergence date due mid-March 2024 (8/Mar/2024) GPT-5 which should have started training before Dec/2023 (OpenAI CEO under oath 16/May/2023: ‘We are not currently training what will be GPT-5; we don’t have plans to do it in the next six months [to 16/Nov/2023]’), and so 120 days later would be due to complete that training next Friday 15 March 2024. For safety, I expect the GPT-5 public release date to be after the November 2024 US elections.
2/Nov/2023: US military comments on GPT-5 and industry (2/Nov/2023, PDF):
Question: Looking over the past year, how does DARPA and the DARPA programs that pop up, how do they stay relevant with the fast-paced advancements in AI? How does DARPA maintain relevance when it is that fast paced?
Answer (DARPA): One area is by program structure. The AI Cyber Challenge (AIxCC) is a competition where we partner with large language model (LLM) companies (Anthropic, Google, Microsoft, and OpenAI) to provide compute access to those in the competition. As the capability advances so too will the performers using them be able to leverage the advanced capability at the same time. That is one model. Another piece is that we will be keeping an eye on what is happening if the capability that we are working on in the program becomes outmatched, we will stop the program and regenerate or do something else. Another thing is that not all the frontiers are advancing at the same pace. Reinforcement learning is not going as fast as the transformer model. The pace of the frontier models is slowing down a little bit. A lot of the results that we are seeing right now include understanding what they are doing and what they are not doing. They haven’t released GPT5. They [OpenAI] haven’t really even started training GPT-5 due to the slowdown in the release of the H100s due to the production problems at the Taiwan Semiconductor Manufacturing Company Limited (TSMC). So, we have a little bit of breathing space. The Gemini model, getting the planning piece integrated in the LLM, we are not sure, we lack full transparency, but there are large research problems that still need to be solved. Hearing people say we’re “just a little bit away from full artificial general intelligence (AGI)” is a bit more optimistic than reality. There are things like the halting problem. We still have exponential things. We still need resources. I think there are still going to be super hard problems that are not going to be fixed by scaling.
31/Jan/2024: The Memo: Exclusive: GPT-5 and gold datasets (31/Jan/2024)
When raising a child prodigy, should we provide more learning and experiences or higher-quality learning and experiences?
When training frontier models like GPT-5, should we use more data or higher-quality data?
In Jun/2021, I published a paper called ‘Integrated AI: Dataset quality vs quantity via bonum (GPT-4 and beyond)’. It explored high-quality data aligned with ‘the ultimate good’ (in Latin, this is ‘summum bonum’).
OpenAI’s CEO recently spoke at a number of big venues including the 54th annual meeting of the World Economic Forum (WEF) at Davos-Klosters, Switzerland from 15th to 19th January 2024. He was recorded as making a very interesting comment:
As models become smarter and better at reasoning, we need less training data. For example, no one needs to read 2000 biology textbooks; you only need a small portion of extremely high-quality data and to deeply think and chew over it. The models will work harder on thinking through a small portion of known high-quality data. (Reddit, not verbatim, 22/Jan/2024)
One researcher (22/Jan/2024) similarly notes:
…potentially ‘infinity efficient’ because they may be one-time costs to create. Depending on the details, you may simply create them once and then never again. For example, in ‘AlphaGeometry’, it seems likely that for most problems there’s going to be one and only one best & shortest proof, and that any search process would converge upon it quickly, and now you can just train all future geometry models on that ideal proof. Similarly, in chess or Go I expect that in the overwhelming majority of positions (even excluding the opening book & endgame databases), the best move is known and the engines aren’t going to change the choice no matter how long you run them. ‘Gold datasets’ may be a good moat.
For text training, we’ve now hit massive datasets like the 125TB (30 trillion token) RedPajama-Data-v2, and I continue to track the other highlights on the Datasets Table.
Nearly three years after my data quality paper, are we finally on the way to higher quality (and perhaps temporarily smaller) datasets rather than ‘more is better’?
Explore more in my Mar/2022 comprehensive analysis of datasets, ‘What’s in my AI?’.
18/Jan/2024: OpenAI CEO: ‘GPT-2 was very bad. GPT-3 was pretty bad. GPT-4 was pretty bad. But GPT-5 would be okay.’ (Korean media)
GPT5 is much smarter (than previous models) and will offer more features. It adds inference capabilities, which is an important advance in its general-purpose ability to process tasks on behalf of users. Since people love ChatGPT’s voice feature, much better audio will be provided.
If I had to pick one thing, the writing would be greatly improved.
If you hold the iPhone released in 2007 in one hand and the (latest model) iPhone 15 in the other, you see two very different devices. I believe the same thing is true about AI.
12/Jan/2024: OpenAI CEO: ‘GPT-5 and AGI will be achieved “relatively soon”‘. (Twitter)
24/Nov/2023: Coke CMO probably got GPT-V and GPT-5 confused when he said: ‘Coca Cola Diwali has been done with GPT-5.’
Manolo Arroyo (Global Chief Marketing Officer for The Coca‑Cola Company):
I can give you maybe an insight, some pieces of new news that no one has shared so far. We have a partnership with Bain and OpenAI…
We were actually the first company that was combining GPT, which is the engine that enables ChatGPT, and DALL-E. Back then, no one knew that because of the partnership with OpenAI, we were the first company using GPT-4 and DALL-E 2 into one integrated consumer digital experience. No one knows, because it hasn’t been launched yet, that Coca Cola Diwali has been done with
GPT-5[probably referring to GPT-V] which is still not commercially available, and DALL-E 3 that has also not been launched…And that’s how in just six months this technology is progressing… launch it for Christmas [2023] globally…
(— Coca-Cola’s Mega Marketing Transformation by The Morning Brief (The Economic Times), 17m31s – transcribed with my fingers because both otter and whisper were down…)
Edit: Making it clearer that the quote above must have been confused between GPT-V and GPT-5. GPT-V(ision) was announced as part of GPT-4 in Mar/2023. GPT-5 will be in training between Dec/2023 and Apr/2024 as an estimate.
13/Nov/2023: OpenAI CEO on GPT-5: The company is also working on GPT-5, the next generation of its AI model, Altman said, although he did not commit to a timeline for its release. It will require more data to train on, which Altman said would come from a combination of publicly available data sets on the internet, as well as proprietary data from companies. OpenAI recently put out a call for large-scale data sets from organisations that “are not already easily accessible online to the public today”, particularly for long-form writing or conversations in any format. While GPT-5 is likely to be more sophisticated than its predecessors, Altman said it was technically hard to predict exactly what new capabilities and skills the model might have. “Until we go train that model, it’s like a fun guessing game for us,” he said. “We’re trying to get better at it, because I think it’s important from a safety perspective to predict the capabilities. But I can’t tell you here’s exactly what it’s going to do that GPT-4 didn’t.” (FT)
Read more about emerging abilities.
22/Oct/2023: OpenAI CEO on GPT-5 being AGI: “We define AGI as ‘the thing we don’t have quite yet.’ There were a lot of people who would have—ten years ago [2013 compared to 2023]—said alright, if you can make something like GPT-4, GPT-5 maybe, that would have been an AGI… I think we’re getting close enough to whatever that AGI threshold is going to be.” (YouTube).
19/Oct/2023: Bill Gates says GPT-5 won’t be much better than GPT-4.
[Gates] predicts stagnation in development at first. “We have reached a plateau,” said Gates, referring to OpenAI’s GPT AI model, which has caused a stir around the world. The next version won’t be much better than the current GPT4; a limit has been reached.
7/Oct/2023: More Gobi rumors and analysis in Reddit thread by FeltSteam (archive).
29/Sep/2023: Gobi rumors and analysis in shared Google Doc.
18/Jul/2023: OpenAI mentions ‘GPT-V’ in job listing (may be GPT-4V/Vision as in GPT-4).
18/Jul/2023: OpenAI files to trademark the term ‘GPT-5’. Full filing at USPTO: https://uspto.report/TM/98089548 and application table.

6/Jul/2023: OpenAI Alignment team lead comments on GPT-5 alignment (Alan: I don’t like to give airtime to AI doomers like EY, so this is mainly for Dr Jan’s response). ‘We can see how well alignment of GPT-5 will go. We’ll monitor closely how quickly the tech develops.’
We'll stare at the empirical data as it's coming in:
1. We can measure progress locally on various parts of our research roadmap (e.g. for scalable oversight)
2. We can see how well alignment of GPT-5 will go
3. We'll monitor closely how quickly the tech develops— Jan Leike (@janleike) July 5, 2023
7/Jun/2023: “We have a lot of work to do before we start that model [GPT-5],” Altman, the chief executive of OpenAI, said at a conference hosted by Indian newspaper Economic Times. “We’re working on the new ideas that we think we need for it, but we are certainly not close to it to start.” (TechCrunch)
2/Jun/2023: OpenAI CEO updates, requested to be removed from the web, archived here.
OpenAI CEO updates Jun/2023
Archived from: https://humanloop.com/blog/openai-plans
1. OpenAI is heavily GPU limited at present
A common theme that came up throughout the discussion was that currently OpenAI is extremely GPU-limited and this is delaying a lot of their short-term plans. The biggest customer complaint was about the reliability and speed of the API. Sam acknowledged their concern and explained that most of the issue was a result of GPU shortages.
The longer 32k context can’t yet be rolled out to more people. OpenAI haven’t overcome the O(n^2) scaling of attention and so whilst it seemed plausible they would have 100k – 1M token context windows soon (this year) anything bigger would require a research breakthrough.
The finetuning API is also currently bottlenecked by GPU availability. They don’t yet use efficient finetuning methods like Adapters or LoRa and so finetuning is very compute-intensive to run and manage. Better support for finetuning will come in the future. They may even host a marketplace of community contributed models.
Dedicated capacity offering is limited by GPU availability. OpenAI also offers dedicated capacity, which provides customers with a private copy of the model. To access this service, customers must be willing to commit to a $100k spend upfront.
2. OpenAI’s near-term roadmap
Sam shared what he saw as OpenAI’s provisional near-term roadmap for the API.
2023:
- Cheaper and faster GPT-4 — This is their top priority. In general, OpenAI’s aim is to drive “the cost of intelligence” down as far as possible and so they will work hard to continue to reduce the cost of the APIs over time.
- Longer context windows — Context windows as high as 1 million tokens are plausible in the near future.
- Finetuning API — The finetuning API will be extended to the latest models but the exact form for this will be shaped by what developers indicate they really want.
- A stateful API — When you call the chat API today, you have to repeatedly pass through the same conversation history and pay for the same tokens again and again. In the future there will be a version of the API that remembers the conversation history.
2024:
- Multimodality — This was demoed as part of the GPT-4 release but can’t be extended to everyone until after more GPUs come online.
3. Plugins “don’t have PMF” and are probably not coming to the API anytime soon
A lot of developers are interested in getting access to ChatGPT plugins via the API but Sam said he didn’t think they’d be released any time soon. The usage of plugins, other than browsing, suggests that they don’t have PMF yet. He suggested that a lot of people thought they wanted their apps to be inside ChatGPT but what they really wanted was ChatGPT in their apps.
4. OpenAI will avoid competing with their customers — other than with ChatGPT
Quite a few developers said they were nervous about building with the OpenAI APIs when OpenAI might end up releasing products that are competitive to them. Sam said that OpenAI would not release more products beyond ChatGPT. He said there was a history of great platform companies having a killer app and that ChatGPT would allow them to make the APIs better by being customers of their own product. The vision for ChatGPT is to be a super smart assistant for work but there will be a lot of other GPT use-cases that OpenAI won’t touch.
5. Regulation is needed but so is open source
While Sam is calling for regulation of future models, he didn’t think existing models were dangerous and thought it would be a big mistake to regulate or ban them. He reiterated his belief in the importance of open source and said that OpenAI was considering open-sourcing GPT-3. Part of the reason they hadn’t open-sourced yet was that he was skeptical of how many individuals and companies would have the capability to host and serve large LLMs.
6. The scaling laws still hold
Recently many articles have claimed that “the age of giant AI Models is already over”. This wasn’t an accurate representation of what was meant.
OpenAI’s internal data suggests the scaling laws for model performance continue to hold and making models larger will continue to yield performance. The rate of scaling can’t be maintained because OpenAI had made models millions of times bigger in just a few years and doing that going forward won’t be sustainable. That doesn’t mean that OpenAI won’t continue to try to make the models bigger, it just means they will likely double or triple in size each year rather than increasing by many orders of magnitude.
The fact that scaling continues to work has significant implications for the timelines of AGI development. The scaling hypothesis is the idea that we may have most of the pieces in place needed to build AGI and that most of the remaining work will be taking existing methods and scaling them up to larger models and bigger datasets. If the era of scaling was over then we should probably expect AGI to be much further away. The fact the scaling laws continue to hold is strongly suggestive of shorter timelines.
31/May/2023: OpenAI announces GPT-4 MathMix (paper).
29/May/2023: NVIDIA Announces DGX GH200 AI Supercomputer (NVIDIA). ‘New Class of AI Supercomputer Connects 256 Grace Hopper Superchips Into Massive, 1-Exaflop, 144TB GPU for Giant Models… GH200 superchips eliminate the need for a traditional CPU-to-GPU PCIe connection by combining an Arm-based NVIDIA Grace™ CPU with an NVIDIA H100 Tensor Core GPU in the same package, using NVIDIA NVLink-C2C chip interconnects.’
Expect trillion-parameter models like OpenAI GPT-5, Anthropic Claude-Next, and beyond to be trained with this groundbreaking hardware. Some have estimated that this could train language models up to 80 trillion parameters, which gets us closer to brain-scale.
20/May/2023: Updated GPT-4 chart for reference.
By request, here’s a simplified version of this full GPT-4 vs human viz; easier to read on a big screen!
 Download source (PDF)
Download source (PDF)
19/May/2023: OpenAI CEO (Elevate):
…with the arrival of GPT-4, people started building entire companies around it. I believe that GPT-5, 6, and 7 will continue this trajectory in future years, really increasing the utility they can provide.
This development is a big, new, exciting thing to have in the world. It’s as though all of computing got an upgrade.
I think we’ll look back at this period like we look back at the period where people were discovering fundamental physics. The fact that we’re discovering how to predict the intelligence of a trained AI before we start training it suggests that there is something close to a natural law here. We can predictably say this much compute, this big of a neural network, this training data – these will determine the capabilities of the model. Now we can predict how it’ll score on some tests.
…whether we can predict the sort of qualitative new things – the new capabilities that didn’t exist at all in GPT-4 but do exist in future versions like GPT-5. That seems important to figure out. But right now, we can say, ‘Here’s how we predict it’ll do on this evaluation or this metric.’ I really do think we’ll look back at this period as if we were all living through one of the most important periods of human discovery.
I believe that this will be a monumental deal in terms of how we think about when we go beyond human intelligence. However, I don’t think that’s quite the right framework because it’ll happen in some areas and not others. Already, these systems are superhuman in some limited areas and extremely bad in others, and I think that’s fine.
…this analogy: it’s like everybody’s going to be the CEO of all of the work they want to do. They’ll have tons of people that they’re able to coordinate and direct, provide the text and the feedback on. But they’ll also have lots of agents, for lack of a better word, that go off and do increasingly complex tasks.
16/May/2023: OpenAI CEO to Congress: ‘We are not currently training what will be GPT-5; we don’t have plans to do it in the next 6 months [to 16/Nov/2023]’.
"We are not currently training what will be GPT-5; we don't have plans to do it in the next 6 months"
– Sam Altman, under oath— Daniel Eth (yes, Eth is my actual last name) (@daniel_271828) May 16, 2023
11/May/2023: Microsoft Korea: ‘We are preparing for GPT-5, and GPT-6 will also be released.’ (Yonhap News Agency (Korean)).
13/Apr/2023: At an MIT event, OpenAI CEO confirmed previous statement from two weeks ago, saying “We are not [training GPT-5] and won’t for some time.”
 Meme inspired by /r/singularity.
Meme inspired by /r/singularity.
29/Mar/2023: Hannah Wong, a spokesperson for OpenAI, says… OpenAI is not currently training GPT-5. (Wired).
29/Mar/2023: ‘i have been told that gpt5 is scheduled to complete training this december and that openai expects it to achieve agi. which means we will all hotly debate as to whether it actually achieves agi. which means it will.’
Siqi is the founder and CEO of Runway, an a16z funded startup.
i have been told that gpt5 is scheduled to complete training this december and that openai expects it to achieve agi.
which means we will all hotly debate as to whether it actually achieves agi.
which means it will.
— Siqi Chen (@blader) March 27, 2023
23/Mar/2023: Microsoft paper on GPT-4 and early artificial general intelligence: https://arxiv.org/abs/2303.10130
20/Mar/2023: OpenAI paper on GPT and employment: ‘We investigate the potential implications of Generative Pre-trained Transformer (GPT) models and related technologies on the U.S. labor market.’ https://arxiv.org/abs/2303.10130
13/Feb/2023: Morgan Stanley research note:
We think that GPT 5 is currently being trained on 25k GPUs – $225 mm or so of NVIDIA hardware…
The current version of the model, GPT-5, will be trained in the same facility—announced in 2020 [May/2020, Microsoft], the supercomputer designed specifically for OpenAI has 285k CPU cores, 10k GPU cards, and 400 Gb/s connectivity for each GPU server; our understanding is that there has been substantial expansion since then. From our conversation, GPT-5 is being trained on about 25k GPUs, mostly A100s, and it takes multiple months; that’s about $225m of NVIDIA hardware, but importantly this is not the only use, and many of the same GPUs were used to train GPT-3 and GPT-4…
We also would expect the number of large language models under development to remain relatively small. IF the training hardware for GPT-5 is $225m worth of NVIDIA hardware, that’s close to $1b of overall hardware investment; that isn’t something that will be undertaken lightly. We see large language models at a similar scale being developed at every hyperscaler, and at multiple startups.
Morgan Stanley on Nvidia’s opportunity with ChatGPT etc 👇🏻
“We think that GPT 5 is currently being trained on 25k GPUs – $225 mm or so of NVIDIA hardware…”
Let’s hope @annerajb and @GroggyTBear have sourced enough GPUs for ‘23. We’re pretty much sold out. Sorry 😔😔😔$NVDA pic.twitter.com/k6X9YOSsgF
— David Tayar (@davidtayar5) February 13, 2023
Remainder of note 👇🏻 pic.twitter.com/TSKeYqetNP
— David Tayar (@davidtayar5) February 20, 2023
Models Table
Summary of current models: View the full data (Google sheets)Dataset
 A Comprehensive Analysis of Datasets Likely Used to Train GPT-5
A Comprehensive Analysis of Datasets Likely Used to Train GPT-5
Alan D. Thompson
LifeArchitect.ai
August 2024
27 pages incl title page, references, appendices.
Timeline to GPT-5
| Date | Milestone |
| 11/Jun/2018 | GPT-1 announced on the OpenAI blog. |
| 14/Feb/2019 | GPT-2 announced on the OpenAI blog. |
| 28/May/2020 | GPT-3 preprint paper published to arXiv. |
| 11/Jun/2020 | GPT-3 API private beta. |
| 22/Sep/2020 | GPT-3 licensed exclusively to Microsoft. |
| 18/Nov/2021 | GPT-3 API opened to the public. |
| 27/Jan/2022 | InstructGPT released as text-davinci-002, later known as GPT-3.5. InstructGPT preprint paper Mar/2022. |
| 28/Jul/2022 | Exploring data-optimal models with FIM, paper on arXiv. |
| Aug/2022 | GPT-4 finished training, available in lab. |
| 1/Sep/2022 | GPT-3 model pricing cut by 66% for davinci model. |
| 21/Sep/2022 | Whisper (speech recognition) announced on the OpenAI blog. |
| 28/Nov/2022 | GPT-3.5 expanded to text-davinci-003, announced via email: 1. Higher quality writing. 2. Handles more complex instructions. 3. Better at longer form content generation. |
| 30/Nov/2022 | ChatGPT announced on the OpenAI blog. |
| 14/Mar/2023 | GPT-4 released. |
| 31/May/2023 | GPT-4 MathMix and step by step, paper on arXiv. |
| 6/Jul/2023 | GPT-4 available via API. |
| 25/Sep/2023 | GPT-4V released. |
| 13/May/2024 | GPT-4o announced. |
| 18/Jul/2024 | GPT-4o mini announced. |
| 12/Sep/2024 | o1 released. |
| 20/Dec/2024 | o3 announced. |
| 27/Feb/2025 | GPT-4.5 released. |
| 14/Apr/2025 | GPT-4.1 released. |
| 16/Apr/2025 | o3 released. |
| 16/Apr/2025 | o4-mini released. |
| 5/Aug/2025 | gpt-oss-120b and gpt-oss-20b released. |
| 7/Aug/2025 | GPT-5 released. |
| 12/Nov/2025 | GPT-5.1 released. |
| 11/Dec/2025 | GPT-5.2 released. |
| 5/Feb/2026 | GPT-5.3-Codex released. |
| 5/Mar/2026 | GPT-5.4 released. |
| Mar/2026 | ‘Spud’ finished training, available in lab. |
| 2026 | GPT-6 due… |
| 2027 | GPT-7 due… |
Get The Memo
by Dr Alan D. Thompson · Be inside the lightning-fast AI revolution.Informs research at Apple, Google, Microsoft · Bestseller in 147 countries.
Artificial intelligence that matters, as it happens, in plain English.
Get The Memo.
 Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.
Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.This page last updated: 26/Sep/2025. https://lifearchitect.ai/gpt-5/↑





