%
Last update: Feb/2026
Get The Memo.
AGI definition etc.
Definition
AGI = artificial general intelligence = a machine that performs at the level of an average (median) human.
ASI = artificial superintelligence = a machine that performs at the level of an expert human in practically any field.
I use a slightly stricter definition for AGI that includes the ability to act on the physical world via embodiment. I appreciate that there were some approaches on getting to AGI that fully bypass embodiment or robotics.
Artificial general intelligence (AGI) is a machine capable of understanding the world as well as—or better than—any human, in practically every field, including the ability to interact with the world via physical embodiment.
And the short version: ‘AGI is a machine which is as good or better than a human in every aspect’.
 The world and acceptance of AGI
The world and acceptance of AGI
Why does AGI need physical embodiment?
A reader asks ‘Does AGI really need physical embodiment? Think about Stephen Hawking. Was it a knock that he couldn’t move his body? Was that a part of his human intelligence? I’d argue that is a clear no. GPT-4 and Gemini are already a kind of proto ASI they are just glitchy and strange. The only thing they need to be ASI is more agency and automation that’s the final bottleneck. Clearly not ironed out yet sure. Putting them in a Boston dynamic robot won’t make them any smarter, the same way if we gave Hawking a magic cure to move again he would just be the same intelligence. Intelligence and embodiment are just not correlated at all with these systems; it wouldn’t change how smart they are, only utility, which is not the same thing.’
Here are some additional considerations for this thought experiment:
1. The definition of intelligence is not fully agreed upon, but may include ‘the ability to learn or understand or to deal with new or trying situations.’ Would it be possible to deal with a new or trying physical situation without embodiment?
2. Hawking had the benefit of more than two decades of full embodiment, including access to all 5+ of his human senses, until ALS began to weaken his physical abilities in his 20s and 30s. Would he have been able to make big discoveries in gravitational and theoretical physics without falling over? Or being able to move pen and paper? Or playing with ball models?
3. All major IQ tests for under 18s include physical object manipulation (like blocks, toys, chips, cards and other manipulatives for fine motor skills of the hands and fingers). For Wechsler this is the WPPSI and WISC. For Stanford-Binet this is the SB-5 and the older Form L-M.
Some further reading for interest:
Paper: The necessity of embodiment (2019, PDF).
LessWrong: Embodiment is Indispensable for AGI (Jun/2022).
What is a median human?
More than a decade ago, the average human was a 28-year-old man from China: ‘He is Han Chinese so his ethnicity is Han. He is 28 years old. He is Christian. He speaks Mandarin. He does not have a car. He does not have a bank account.’ (NatGeo study cited by CBS, 2011).
By the way, the median American is much different (Read more via New Strategist on archive.org, 2011, and CNBC, 2018)
The median human in 2024-2025 may meet these dot points:
- A 30-year-old woman from India
- Works as a Product Manager (or in agriculture or medicine)
- Speaks 2 languages
- Will read 700 books in her lifetime
- Can recall roughly 7 items (working memory)
- Average SAT score around 1050/1600 (P50)
- Average IQ around 100 (P50)
- Can make a cup of coffee in a strange kitchen
- Can assemble IKEA furniture
- Cannot build a house
| Ability | GPT-4 (2022) | Gemini (2023) | LLM + Robot (2024) | 2025 | 2026 |
|---|---|---|---|---|---|
| Cognitive | |||||
| Works as a Product Manager | ✅ | ✅ | ✅ | ||
| Speaks 2 languages | ✅ | ✅ | ✅ | ||
| Will read 700 books in her lifetime | ✅ | ✅ | ✅ | ||
| Can recall roughly 7 items (working memory) | ✅ | ✅ | ✅ | ||
| Average SAT score around 1050/1600 (P50) | ✅ | ✅ | ✅ | ||
| Average IQ around 100 (P50) | ✅ | ✅ | ✅ | ||
| Truthful: grounded in an accepted version of truth without confabulation or hallucination | ❌ | ❌ | ❌ | ||
| Basic human abilities | |||||
| See: can intepret images with vision | ✅ | ✅ | ✅ | ||
| Hear: can detect tone in language, music | – | ✅ | ✅ | ||
| Taste: can detect flavour | – | ❌ | ❌ | ||
| Touch: can detect temperature, texture, pressure | – | ❌ | ❌ | ||
| Smell: can detect fragrance | – | ❌ | ❌ | ||
| Proprioception: awareness of where body parts are in space | – | ❌ | ✅ | ||
| Embodiment (autonomous; not pre-programmed) | |||||
| Can make a cup of coffee in a strange kitchen | – | – |
❌
|
||
| Can assemble IKEA furniture | – | – |
❌
|
||
Who tf is Alan?
A fair question in the age of millions of newly-minted AI experts! Alan is the ‘secret weapon’ for many AI labs, companies, and governments. He started his AI journey in the early 1990s, developing AI chatbots in QBASIC, followed by a degree in Computer Science with Psychology. He spent a decade leading applied human intelligence research, including as Chairman of Mensa’s gifted families. He rejoined the artificial intelligence fold with the launch of GPT-3 in 2020. He’s also known for things like:
– G7 (Group of Seven, global economic policy) referenced his GPT-5 report in their document building on The Hiroshima Framework.
– His visualizations were featured by professors at NeurIPS 2024.
– Apple leveraging his research in their new AI model paper for September 2024, using it as the foundation for their visualizations.
– Microsoft, RAND, and the European Commission, a few of the 10,000+ clients reading the regular advisory, The Memo, a Substack ‘bestseller’ in 147 countries.
– Ernst & Young, Ray White, USAA, and major government agencies consistently book him as their go-to speaker and educator for artificial intelligence topics.
– The largest asset managers in the world, with trillions of dollars in assets under management, use Alan for ongoing AI advisory.
– Fortune 500 companies import his AI expertise for in-person consulting engagements.
– Think tanks like Brookings Institution, BloombergNEF, RAND, and NBER frequently cite Alan’s research.
– NYU and other universities leverage visualizations and the popular Models Table, now detailing 500+ large language models.
– ‘What’s in my AI? (2022)‘ is said to be the most comprehensive analysis on GPT datasets, and was followed up by ‘What’s in GPT-5? (2024)‘ and ‘What’s in Grok? (2025)‘.
– More than 5 million early adopters watched Leta AI, across 67 episodes. Leta was powered by GPT-3 175B, a frontier model 2½ years before ChatGPT was released.
And much more: LifeArchitect.ai/about-alan
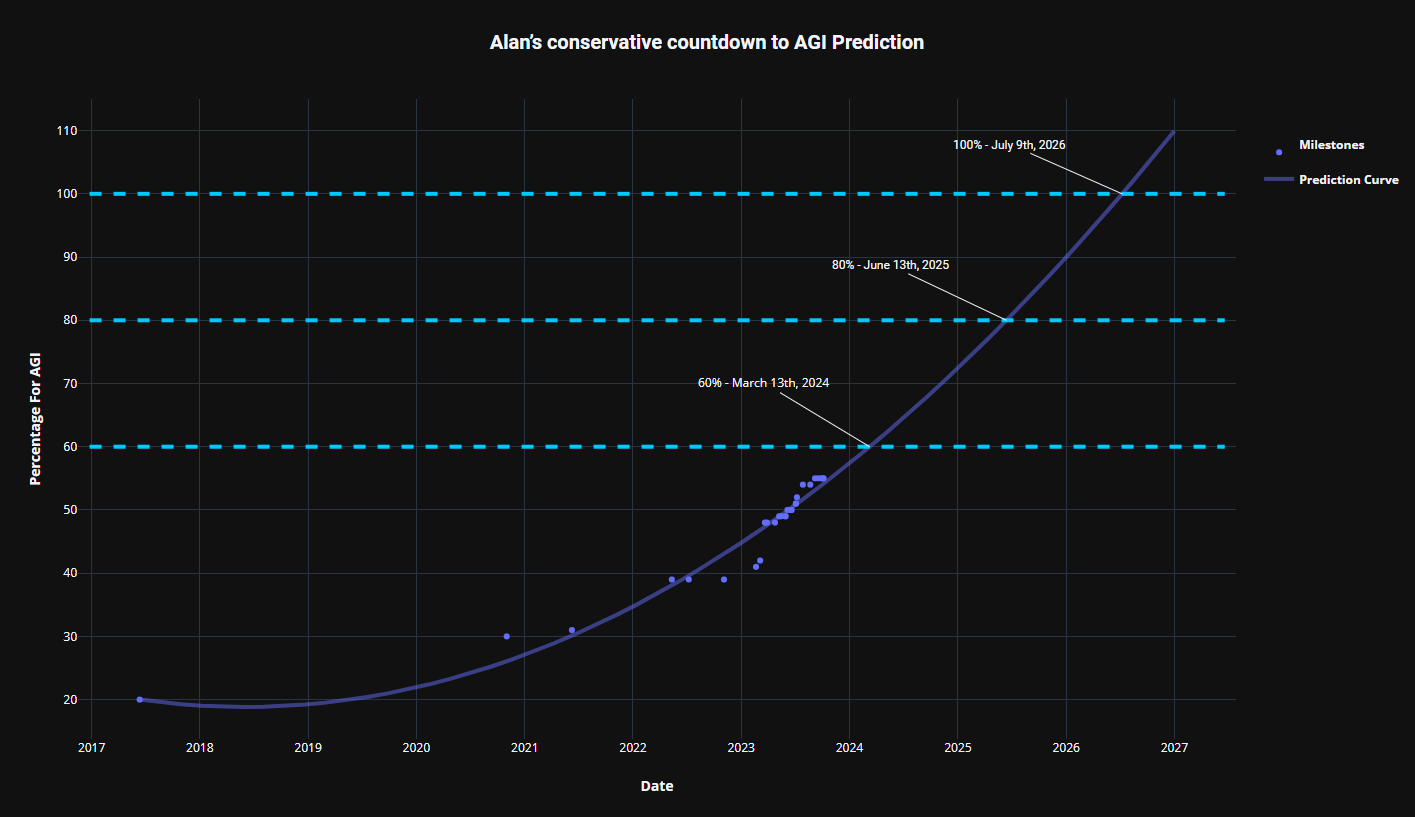
Milestones & justifications (most recent at top, skip to bottom ↓)
| Date | Summary | Links |
|---|---|---|
| 2026 | INFO: As frontier AI systems continue to make new discoveries, the ASI checklist (superhuman) is updated more frequently than the AGI countdown (average human). | |
| Mar/2026 | INFO: Cursor Composer adaptive learning via real-time RL. ‘We serve model checkpoints to production, observe user responses, and aggregate those responses as reward signals. This approach lets us ship an improved version of Composer behind Auto as often as every five hours.’ By learning directly from user interactions rather than simulated environments, Cursor 1.5 achieved a 2.28% increase in edits persisting in the codebase. | Cursor blog |
| Mar/2026 | INFO: Xiaomi CyberOne (2026) with a smart bionic sweat gland cooling system (evaporates water for ~10W active heat dissipation). |
Source |
| Mar/2026 | INFO: AGI declared by two experts:
|
Gubrud, Huang |
| Mar/2026 | INFO: Figure AI in the living room. |
Announce, video |
| Feb/2026 | INFO: An average frontier AI model may now generate text at the rate of 7 billion words per minute (a percentage of all human output on Earth), or the equivalent of all the books in the New York Public Library every 2.8 hours. | LifeArchitect.ai viz |
| Feb/2026 | 97%: Unitree G1 on UnifoLM-VLA-0 7B outperforms Gemini-Robotics-ER 1.5: ‘Based on Unitree’s UnifoLM-X1-0 embodied AI model, this is an actual deployment at Unitree’s own robot factory.’ | Project page, video, repo |
| Jan/2026 | 97%: Figure Helix 02: ‘Full-Body Autonomy’. | Announce, video |
| Jan/2026 | 97%: Google and Boston Dynamics aim to integrate cutting edge Gemini Robotics AI foundation models with Boston Dynamics’ Atlas robots.
|
Announce, WIRED, Video |
| Nov/2025 | INFO: Gemini 3 & Claude Opus 4.5 model releases follow predictable exponential curve. Adam Wolff, Anthropic (24/Nov/2025): ‘I believe this new model [Claude Opus 4.5] in Claude Code is a glimpse of the future we’re hurtling towards, maybe as soon as the first half of next year [2026]: software engineering is done.’ |
Models Table |
| Nov/2025 | 96%: Adaptive Learning: Google DeepMind ‘Nested Learning’ (HOPE). A major paradigm shift addressing static/frozen models. The new architecture introduces “Self-Modifying Titans… a novel sequence model that learns how to modify itself [and] its own update algorithm”.
Unlike traditional models which are frozen after training, Nested Learning allows models to “continually learn/memorize” during inference (test-time training). The HOPE module creates a “Continuum Memory System” mimicking human neuroplasticity, outperforming Transformers and RetNet in language modeling and reasoning tasks. |
Paper, announce, Models Table |
| Sep/2025 | 95%: Gemini Robotics 1.5 agentic system (‘significantly outperforms other frontier models across a broad suite of embodied intelligence benchmarks, while retaining the general capabilities of a frontier model and being considerably faster. GR-ER 1.5’s physical understanding combines naturally with Gemini’s ability to use tools, communicate using modalities like video and audio, and write code, opening up a broad spectrum of potential applications.’). ‘Our embodied reasoning model, Gemini Robotics-ER 1.5, orchestrates a robot’s activities, like a high-level brain… has state-of-the-art spatial understanding, interacts in natural language, estimates its success and progress, and can natively call tools… Gemini Robotics-ER 1.5 then gives Gemini Robotics 1.5 natural language instructions for each step, which uses its vision and language understanding to directly perform the specific actions… we observe that tasks only presented to the ALOHA 2 robot during training, also just work on the Apptronik’s humanoid robot, Apollo, and the bi-arm Franka robot, and vice versa.’
Paper: ‘GR-ER 1.5 significantly outperforms GR-ER [Mar/2025, 92% on AGI countdown], Gemini 2.5, and GPT-5… An important next step is to leverage more scalable data sources beyond traditional robot action data, such as real-world human videos and synthetic videos. Our architectural changes in GR 1.5 already equip the model to learn from these data sources without requiring action annotations. Future efforts will focus on learning from publicly available low-quality video corpora, among other data sources, to further mitigate the data scarcity problem’ |
Announce, paper, video, Models Table |
| Jul/2025 | INFO: Figure 02 humanoid on Helix VLAM putting clothes in the washing machine. |
Video |
| Jul/2025 | INFO: Xingdong Era (RobotEra) L7 humanoid on ERA-42 VLM. Tsinghua X-Lab’s full-size bipedal humanoid robot L7 is the successor to STAR1. Stats: 171cm (5’7″), 65kg (143lbs). Excels at delicate tasks like folding clothes and industrial work like sorting. Powered by RobotEra’s single end-to-end embodied vision language model, ERA-42. |
Interview, Robotera.com, RoboHub announce, Related: 1, 2, 3 |
| Jul/2025 | 94%: Internal LLMs from OpenAI and Google both achieved gold medal-level performance on the International Math Olympiad (IMO), under the same rules as human contestants: two 4.5 hour exam sessions, no tools or internet.
Sidenote: Once again, the smartest man in the world, Adelaide-born Prof Terry Tao demonstrates how difficult it is for humans to understand exponential growth and superintelligence. Just four weeks ago on 15/Jun/2025, he said: ‘It won’t happen this [upcoming 2025] IMO. The [frontier model] performance is not good enough in the time period.‘ Read more about exponential growth (wiki). |
OpenAI announce, OpenAI LLM proofs, Google announce, Google LLM proofs (PDF) |
| Jul/2025 | 94%: xAI Grok 4 frontier model. Grok 4 Heavy achieves scores of AIME25=100, HLE=44.4, GPQA=88.9, said to achieve SAT=100. New SoTA model for Jul/2025, no change to AGI countdown until further average human-like capabilities (for example, via embodiment with Tesla Optimus, as referenced by xAI during the launch). |
My Grok 4 analysis, my Grok 4 Heavy video, Report: What’s in Grok? |
| Jun/2025 | INFO: Generalist AI: ‘the cross-embodied model transfers across different arms (e.g., 7-DoF Flexiv Rizon 4, and 6-DoF UR5), and generalizes well to entirely new environments… fine motor control, spatial and temporal precision, generalization across robots and settings, and robustness to external disturbances.’ | Announce, video |
| Jun/2025 | INFO: Anthropic multi-agent research system: Parallel agents collaborate under a lead, self-debug, optimize prompts, and coordinate tool use, enabling multi-threaded reasoning, persistent memory across agents supporting long-horizon task, perform open-ended research with minimal human prompting, early signs of meta-reasoning and tool autonomy.
|
Announce |
| Jun/2025 | INFO: The breakthroughs needed for AGI have already been made: OpenAI former research head Bob McGrew: ‘If you go forward to 2035 and you look back and you say, “What were the fundamental concepts that you needed in order to create more and more intelligence?” Maybe that’s AGI… language models with Transformers, the idea of scaling the pre-training on those language models—so GPT-1 and GPT-2, basically—and then the idea of reasoning. And sort of woven throughout that, increasing more and more multimodal capabilities. And I think even in 2035, we’re not going to see any new trends beyond those.’ | Transcript |
| Jun/2025 | INFO: 1X world model. |
Video |
| Jun/2025 | INFO: 1X Gamma and Redwood 160M onboard model. ‘Generalization: Handles variation in tasks—like picking up never-before-seen objects in unfamiliar locations. Trained on a large dataset of teleoperated and autonomous episodes from EVE and NEO, Redwood exhibits emergent behaviors such as choosing…’ |
Announce, video |
| May/2025 | INFO: UC, Georgia Tech, NYU: Language models are capable of metacognitive monitoring and control of their internal activations. LLMs ‘…reveal a “metacognitive space” with dimensionality much lower than the model’s neural space…’ | Paper |
| May/2025 | INFO: OpenAI Chief Scientist, Jakub Pachocki: ‘I definitely believe we have significant evidence that the models are capable of discovering novel insights.’ | Nature |
| May/2025 | INFO: Lead engineer and PM for Anthropic Claude Code (agentic coding tool/CLI agent) says that the agent was written and optimized by Claude: ’80-90% Claude-written code, overall.’ | Video |
| Apr/2025 | INFO: XPeng Iron walking/locomotion seems to be solved. Announced 6/Oct/2024, 1.73m, 70kg, 60 articulating joints, 200 DoF, US$150k RRP estimate. Powered by XPeng’s proprietary 40-core Turing AI chip with a 30B parameter local/embedded model. |
Apr/2025 walking video |
| Apr/2025 | INFO: Tiangong Ultra, the humanoid robot from Beijing Humanoid Robot Innovation Center, completed a half-marathon (21.1km or 13.1 miles) in 2h40m—about 20 minutes faster than the average untrained human. | Summary |
| Apr/2025 | INFO: OpenAI’s full o3 + o4-mini models are SOTA reasoning models, but already documented in the AGI countdown at milestone 88%. | Models Table, announce, system card |
| Apr/2025 | INFO: Google DeepMind job listing for ‘Research Scientist, Post-AGI Research’ ‘…focus on what comes after Artificial General Intelligence (AGI). Key questions include the trajectory of AGI to artificial superintelligence (ASI), machine consciousness, the impact of AGI on the foundations of human society.’ | Job listing, archive |
| Apr/2025 | INFO: OpenAI Memory: ‘ChatGPT will reference your past conversations to recall useful information you’ve shared. It uses this to learn about your interests and preferences, helping make future chats more personalized and relevant.’ and ‘You can also teach ChatGPT something new by saying it in a chat‘, however, ‘it doesn’t retain every detail.’ | OpenAI Memory FAQ, What is Memory? |
| Apr/2025 | 94%: 1X NEO autonomous update in home. 1X’s Vice President of AI, Eric Jang: ‘ChatGPT showed the world that autonomy does not have to be solved one task at a time… the home is where you find the ultimate treasure of diverse data necessary to create a general intelligence. Diverse data across many tasks and environments is a necessary ingredient of making general purpose robots… NEO is a lot more reliable now, and I think the rate of progress will be very steep in 2025.’
|
Video, Twitter source |
| Mar/2025 | INFO: Turing test. In conversation, GPT-4.5 judged to be more human than humans. ‘GPT-4.5 was judged to be the human 73% of the time: significantly more often than interrogators selected the real human participant.’ | Paper (UC San Diego) |
| Mar/2025 | INFO: o1 gets 100% in new Carnegie Mellon math exam: ‘I freshly design non-standard problems for all of my exams… makes me feel like we’re close to the tipping point of being able to do moderately-non-routine technical jobs… [o1 took less than 5 minutes to solve all problems, and the fastest human student] took 30 minutes.’ | LifeArchitect.ai/o1 |
| Mar/2025 | 92%: Gemini Robotics (based on Gemini 2.0). ‘these models enable a variety of robots to perform a wider range of real-world tasks than ever before. As part of our efforts, we’re partnering with Apptronik to build the next generation of humanoid robots with Gemini 2.0.’
Transcript (2m20s): User: “Pick up the basketball and slam dunk it.” Keep in mind, these are objects [basketball and basketball hoop] the robot has never seen before. But by leveraging Gemini 2.0’s understanding of concepts like “basketball” and “slam dunks,” the robot figures out the task.’ Apptronik (humanoid) video: |
Announce, paper, video, Apptronik (humanoid) video |
| Mar/2025 | 91%: First AI-written paper passes human peer review, accepted for scientific publication. Sakana AI (Japan): ‘The AI Scientist-v2 [originally based on GPT-4o-2024-05-13] came up with the scientific hypothesis, proposed the experiments to test the hypothesis, wrote and refined the code to conduct those experiments, ran the experiments, analyzed the data, visualized the data in figures, and wrote every word of the entire scientific manuscript, from the title to the final reference, including placing figures and all formatting.’ | Announce, paper + comments (PDF), additional review by Sakana (PDF) |
| Mar/2025 | INFO: Boston Dynamics Atlas update. |
Announce, video |
| Mar/2025 | 90%: UBTech Walker S1 humanoid robots powered by DeepSeek R1 deployed to Volkswagen, Audi, BYD, and Foxconn factories. ‘…using DeepSeek-R1 deep reasoning technology, the model… allows them to break down, schedule, and coordinate tasks autonomously, optimizing multi-robot collaboration in complex industrial workflows.’
Video with unfortunate music choice: |
Announce, article, video |
| Mar/2025 | 90%: Sesame Conversational Speech Model (CSM, 8B, 300M decoder) preferred over humans (52.9% no context). Demo (free, no login): sesame.com/voicedemo |
Demo, research, repo |
| Feb/2025 | 90%: GPT-4.5 lowers hallucination rate for traditional LLMs tested on PersonQA, an evaluation that aims to elicit hallucinations (lower is better): GPT-4o=0.30 o1=0.20 GPT-4.5=0.19 o3-mini=0.15 deep research=0.13 |
Paper (PDF), Models Table, my analysis |
| Feb/2025 | 90%: Figure Helix logistics. ‘…with a 50% speed increase [“Sport Mode”] the policy achieves faster object handling compared to the expert trajectories it is trained on [currently ~10% faster than human teleoperation throughput].’ | Announce, video |
| Feb/2025 | INFO: Apptronik Apollo humanoid robots [powered by Google DeepMind] to build themselves. ‘…strategic collaboration to build Apollo humanoid robots and integrate them into specific Jabil manufacturing operations. This includes the production lines that will build Apollo humanoid robots, paving the way for Apollo to build Apollo.’ | Announce |
| Feb/2025 | INFO: Unitree G1: ‘We have continued to upgrade the Unitree G1’s algorithm, enabling it to learn and perform virtually any movement.’
(Sidenote: Q: Why do humanoid robot videos look like CGI? |
Video |
| Feb/2025 | INFO: Alibaba used QwQ-Max-Preview to write the QwQ-Max-Preview announcement. Nearly two years ago (15/Mar/2023), OpenAI used GPT-4 for copyediting and summarization in the GPT-4 technical report. | QwQ-Max-Preview announce, GPT-4 acknowledgment (PDF). |
| Feb/2025 | 90%: 1X NEO Gamma humanoid robot opens the new Nothing Phone (3a). | 1X NEO Gamma, video |
| Feb/2025 | 90%: Figure Helix using models S1 80M VLM + S2 7B VLM (likely based on OpenVLA 7B Jun/2024, based on Llama 2 7B, or Molmo 7B-O Sep/2024, based on OLMo-7B-1024 with OpenAI CLIP). Emergent ‘Pick up anything’. Zero-shot multi-robot coordination. ‘Uses a single set of neural network weights to learn all behaviors—picking and placing items, using drawers and refrigerators, and cross-robot interaction—without any task-specific fine-tuning… Helix is the first VLA that runs entirely onboard embedded low-power-consumption GPUs, making it immediately ready for commercial deployment.’
(Sidenote: DeepMind Gato ran a 1B model on embedded NVIDIA 3090. Gato was doing some of this nearly 3 years ago, when it moved the AGI countdown from 31% ➜ 39%.)
|
Paper, announce, video, Models Table |
| Feb/2025 | 88%: xAI Grok-3 frontier model.
ALPrompt scores (base model/non-reasoning): GPQA Grok-3=75.4%, Grok-3 + reasoning + ITC=84.6%
|
Report: What’s in Grok?, announce, Models Table |
| Feb/2025 | INFO: Meta + humanoids: ‘the robotics product group would focus on research and development involving “consumer humanoid robots with a goal of maximizing Llama’s platform capabilities.”‘
(Sidenote: As soon as this kind of combination of multimodal models + physical embodiment via humanoids comes to life, we will hit 100% on this countdown.) |
Reuters, Bloomberg |
| Feb/2025 | 88%: OpenAI ‘deep research’ agent model based on o3 hits SOTA 26.6% on HLE (AGI/ASI benchmark). Deep research has web access and will sometimes ‘think’ for more than 30 minutes while formulating a response. | Announce, launch video |
| Jan/2025 | 88%: Figure.03 in lab + Figure.02 shipping. ‘F.02 humanoid robots have arrived at our commercial customer’ and ‘While Figure 02 is the currently shipping model, Diamandis says that Figure 03 is up and running in the lab, and it’s even more impressive.’
|
Analysis, Image |
| Jan/2025 | 88%: OpenAI Operator CUA. A research preview of a computer use agent (CUA) that can use its own browser to perform tasks. (Computer use benchmark OSWorld=38.1% vs human 72.4%. Browser use benchmark WebArena=58.1% vs human 78.2%.)
|
Announce, System card (PDF) |
| Jan/2025 | INFO: Stargate Project launched: $½ trillion of AI datacentres in the US. Masayoshi Son, SoftBank: ‘AGI is coming very, very soon. After that, artificial superintelligence will come to solve the issues that mankind would never ever have thought that we could solve.’ (21/Jan/2025) Dr Noam Brown, OpenAI: ‘This is on the scale of the Apollo Program and Manhattan Project when measured as a fraction of GDP. This kind of investment only happens when the science is carefully vetted and people believe it will succeed and be completely transformative. I agree it’s the right time.’ (21/Jan/2025) |
Source |
| Jan/2025 | 88%: NVIDIA Cosmos released for training humanoid robots: AI labs are leveraging the new platform 'to accelerate the development of [their] humanoid robot[s]' via 'Foresight and “multiverse” simulation, using Cosmos and Omniverse to generate every possible future outcome an AI model could take to help it select the best and most accurate path.'
14 humanoids shown, country of origin added:
|
Cosmos dataset calcs, Cosmos paper, NVIDIA announce, CES 2025 video (timecode), Models Table |
| Jan/2025 | INFO: OpenAI CEO: 'We are now confident we know how to build AGI as we have traditionally understood it. We believe that, in 2025, we may see the first AI agents... We are beginning to turn our aim beyond that, to superintelligence in the true sense of the word... Superintelligent tools could massively accelerate scientific discovery and innovation well beyond what we are capable of doing on our own, and in turn massively increase abundance and prosperity.'
See also: Alan’s ASI checklist (What to expect when you’re expecting artificial superintelligence): LifeArchitect.ai/ASI |
Source, Alan's ASI checklist |
| Dec/2024 | 88%: Scentience.ai olfaction. 'The App pairs to a Scentience device via Bluetooth and processes olfaction data [scents, compounds, and air quality] locally through a built-in Scent Vision Language Model.' | Web |
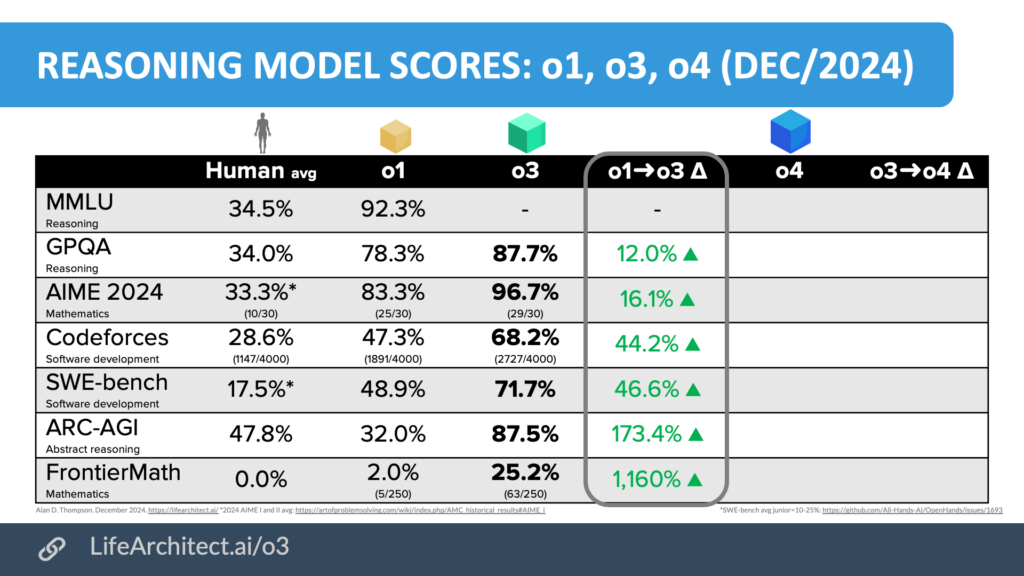
| Dec/2024 | 88%: OpenAI o3 (reasoning model), new state-of-the-art frontier model.
GPQA Diamond=87.7% Fields Medalist Sir Timothy Gowers on the hundreds of questions in the FrontierMath benchmark (Nov/2024):
|
Evals, ARC-AGI writeup (Note: While I recognize ARC's contributions, this benchmark fails to capture the essential dynamics of AI performance.) |
| Dec/2024 | INFO: Tesla Optimus humanoid walking on uneven ground. |
Source, YT video |
| Dec/2024 | 84%: DeepMind introduces Genie 2 world model: 'Genie 2 is the path to solving a structural problem of training embodied agents safely while achieving the breadth and generality required to progress towards AGI.'
(Sidenote: DeepMind has not demonstrated specific real-world use cases, but expect applications across diverse sectors to 'instantly' train humanoids in agriculture, mining, manufacturing and assembly, construction, supply chain operations and transport networks, healthcare assistance, home duties including making coffee, and anywhere else you can put a robot...) |
DeepMind blog |
| Nov/2024 | INFO: US Govt recommends a secret 'Manhattan Project' to reach AGI: 'The [U.S.-China Economic and Security Review] Commission recommends: Congress establish and fund a Manhattan Project-like program dedicated to racing to and acquiring an Artificial General Intelligence (AGI) capability.'
(Sidenote: This should have begun 4½ years ago in May/2020 with the announcement of GPT-3, or within that period based on my media releases and reports to the UN: 1, 2, 3, 4) |
PDF (p10), Manhattan Project (wiki), Born secret (wiki) |
| Nov/2024 | 83%: DeepMind AlphaQubit, a system that 'accurately identifies errors inside quantum computers'. This brings the total DeepMind Alpha system count to 17 (seven announced in 2024), see LifeArchitect.ai/gemini-report/#alpha | DeepMind blog, Nature paper |
| Nov/2024 | 83%: Context recall hits 100% in 'needle in the haystack' evals for models like Qwen2.5-Turbo 1M. |
Alibaba blog post, Models Table, related discussion by Steven Johnson at TheLongContext.com |
| Nov/2024 | INFO: Asked: 'What are you excited about in 2025? What's to come?' OpenAI CEO responds: 'AGI.' | Video |
| Oct/2024 | 83%: Anthropic introduces 'the first frontier AI model to offer computer use in public beta... direct Claude to use computers the way people do—by looking at a screen, moving a cursor, clicking buttons, and typing text.' Anthropic comments: 'This example is representative of a lot of drudge work that people have to do.' |
Anthropic announce, video, my analysis |
| Oct/2024 | INFO: Microsoft CEO: 'The autoencoder we use for GitHub Copilot is being optimized by o1. So think about the recursiveness of it, which is: We are using AI to build AI tools to build better AI. It's just a new frontier.' | Video |
| Oct/2024 | INFO: Anthropic CEO: 'I think [powerful AI/AGI] could come as early as 2026…' | Dario's 15,000-word essay |
| Oct/2024 | INFO: OpenAI suggests 'you'll be able to tell we've achieved AGI internally when we take down all the job listings.' [tongue-in-cheek... maybe...] | Video, OpenAI careers (169 open jobs) |
| Sep/2024 | 81%: DeepMind AlphaChip, a process in use since 2020 for 'superhuman chip layouts'. This brings the total DeepMind Alpha system count to 16 (six announced in 2024), see LifeArchitect.ai/gemini-report/#alpha | DeepMind blog, Nature addendum |
| Sep/2024 | 81%: OpenAI o1 (reasoning model) consistently scores 100% in all ALPrompts. These were hardened prompts designed for frontier models. I hadn't expected the 2024 H2 version to be solved for a long time (prior to this, no LLM in Sep/2024 got a score of more than 2/5 for this prompt). I will be re-evaluating my life's work... The model also hits the ‘uncontroversially correct’ ceilings on major benchmarks (GPQA Extended ceiling is 74%, MMLU ceiling is about 90%).
GPQA Diamond=78.3 Update: o1 completes new Dutch high school maths exam in 10 minutes, scores 100% (paper). And—although several earlier models achieved verbal-linguistic IQ (but not full-scale IQ) test results far above 98%—for the first time, o1 would officially pass the Mensa admission based on its LSAT score (95.6%, Mensa minimum 95%, Metaculus discussion.) Click to visualize the distance between o1 and other models on major benchmarks. Note that there is nowhere left to go at the top; AI has now hit the human-comprehensible ceiling across standardized testing for 'smarts':
|
OpenAI o1 announce, evals, my o1 page, Models Table |
| Sep/2024 | INFO: 1X NEO humanoid robot backed by OpenAI investment, behind the scenes video.
1X NEO was able to walk into a strange house, navigate available tools(?), and make a cup of [filter] coffee from scratch (the Woz AGI test): |
New S3 video 1 1/Sep/2024, New S3 video 2 8/Sep/2024, my video from a year ago May/2023 |
| Jul/2024 | 76%: DeepMind AlphaProof and AlphaGeometry 2 [with Gemini] solve advanced reasoning problems in mathematics. 'Today, we present AlphaProof, a new reinforcement-learning based system for formal math reasoning, and AlphaGeometry 2, an improved version of our geometry-solving system. Together, these systems solved four out of six problems from this year’s International Mathematical Olympiad (IMO), achieving the same level as a silver medalist in the competition for the first time... AlphaProof [also solved] the hardest problem in the competition, solved by only five contestants at this year’s IMO.'
'When people saw Sputnik in 1957, they might have had the same feeling I do now. Human civilization needs to move to high alert!' — Professor Po-Shen Loh, national coach of the United States' International Mathematical Olympiad team (26/Jul/2024) |
DeepMind blog, NYT analysis |
| Jul/2024 | INFO: OpenAI internal discussions on AGI levels. OpenAI shared the new classification system with employees on Tuesday 9/Jul/2024 during an all-hands meeting. OpenAI "believes it is... on the cusp of reaching the second, which it calls 'Reasoners.' This refers to systems that can do basic problem-solving tasks as well as a human with a doctorate-level education who doesn’t have access to any tools. At the same meeting, company leadership gave a demonstration of a research project involving its GPT-4 AI model that OpenAI thinks shows some new skills that rise to human-like reasoning..." See comparison with DeepMind's levels further down this page. | Bloomberg |
| Jun/2024 | INFO: Adam Unikowsky, a former law clerk to Justice Antonin Scalia, has won eight Supreme Court cases as lead counsel, says: "Claude is fully capable of acting as a Supreme Court Justice right now...I frequently was more persuaded by Claude’s analysis than the Supreme Court’s… Claude works at least 5,000 times faster than humans do, while producing work of similar or better quality…" | Source, The Memo analysis |
| Jun/2024 | 75%: Claude 3.5 Sonnet: New state-of-the-art model. MMLU=90.4 (5-shot CoT). GPQA=67.2 (maj32 + 5-shot). Scores 5/5 on ALPrompt 2024H1.
For the first time, a large language model has breached the 65% mark on GPQA, designed to be at the level of our smartest PhDs. 'Regular' PhDs score 34%, while in-domain specialized PhDs are at 65%. Claude 3 Sonnet scored 67.2% (maj32 + 5-shot).
|
Model card, Announce, Models Table |
| Jun/2024 | 74%: Harvard + Google TalkTuner: LLMs "have a 'user model', an internal representation of the person it is talking with... LLM-based chatbots appear to tailor their answers to user characteristics..." Tested using the internal representations of the small model LLaMa2Chat-13B. | Project page, paper Related to Anthropic paper Dec/2022 |
| May/2024 | 74%: GPT-4o: Full multimodal Omnimodel with MMLU=88.7. GPQA=53.6. Note: (Amended) Based on MMMU vision benchmark score and new functionality, GPT-4o represents a minor update to the the AGI countdown. Full explanation. |
OpenAI, ELO rating, Dr Jim Fan analysis |
| May/2024 | INFO: Olfaction (smell). New datasets and device. 'We don’t just need more data: we need entirely new data modalities… Scent is a natural new frontier for this evolution. The oldest sense known to life on earth — tangible, physical, rooted in chemistry — is a vast untapped data source.' | Osmo |
| May/2024 | 73%: GPT-4 + Unitree Go1 quadruped robot = DrEureka (UPenn, NVIDIA, UT Austin) 'We trained a robot dog to balance and walk on top of a yoga ball purely in simulation, and then transfer zero-shot to the real world... Frontier LLMs like GPT-4 have tons of built-in physical intuition for friction, damping, stiffness, gravity, etc. We are (mildly) surprised to find that DrEureka can tune these parameters competently and explain its reasoning well.' | Repo + videos, Twitter, NewAtlas analysis |
| Apr/2024 | 72%: Wu's Method + AlphaGeometry outperforms gold medalists at IMO Geometry 'combining AlphaGeometry with Wu's method we set a new state-of-the-art for automated theorem proving on IMO-AG-30, solving 27 out of 30 problems, the first AI method which outperforms an IMO gold medalist.' | Paper |
| Apr/2024 | 72%: The Declaration on AI Consciousness & the Bill of Rights for AI. | LifeArchitect.ai |
| Mar/2024 | 72%: Embodiment: Figure 01 + GPT-4V + voice 'OpenAI models provide high-level visual and language intelligence. Figure neural networks deliver fast, low-level, dexterous robot actions. Everything in this video is a neural network': |
Video, Source, Explanation by Corey Lynch (Figure, ex-Google) |
| Mar/2024 | 71%: Anthropic Claude 3 Opus. State-of-the-art frontier multimodal model for Mar/2024. Higher performance than GPT-4 across benchmarks. Percentage increases for Claude 3 over GPT-4: MMLU +0.46%, BIG-Bench Hard +4.36%, MATH +12.74%, HumanEval (code) +23.57%. Also has 1M+ context window (researchers only) and upcoming 'advanced agentic capabilities'. | Announce, Paper (PDF), Models Table |
| Feb/2024 | 70%: OpenAI Sora ('sky'). Text-to-video diffusion transformer that can ‘understand and simulate the physical world in motion... solve problems that require real-world interaction.’ Two additional considerations:
|
Project page, technical report (html) |
| Feb/2024 | 66%: Google DeepMind Gemini Pro 1.5 sparse MoE. ‘highly compute-efficient multimodal mixture-of-experts model... near-perfect recall on long-context retrieval tasks [1M-10M tokens] across modalities... matches or surpasses Gemini 1.0 Ultra’s state-of-the-art performance across a broad set of benchmarks.’ | Paper (PDF), Models Table |
| Feb/2024 | 65%: Meta AI V-JEPA. ‘physical world model excels at detecting and understanding highly detailed interactions between objects.’ | Announce, paper |
| Feb/2024 | 65%: Google Goose (Gemini) + Google Duckie chatbot: ‘descendant of Gemini... trained on the sum total of 25 years of engineering expertise at Google... can answer questions around Google-specific technologies, write code using internal tech stacks and supports novel capabilities such as editing code based on natural language prompts.’ See also: Rubber duck debugging (wiki). | BI |
| Feb/2024 | 65%: Google DeepMind: OAIF: ‘online AI feedback (OAIF), uses an LLM as annotator... online DPO outperforms RLAIF and RLHF... reduced human annotation effort.’ | Paper |
| Jan/2024 | 65%: Google uses Gemini to fix their code: ‘Instead of a software engineer spending an average of two hours to create each of these commits, the necessary patches are now automatically created in seconds [by Gemini].’ | PDF, The Memo |
| Jan/2024 | 65%: DeepMind AlphaGeometry. Trained using 100% synthetic data, open source, ‘approaching the performance of an average International Mathematical Olympiad (IMO) gold medallist. Notably, AlphaGeometry produces human-readable proofs, solves all geometry problems... under human expert evaluation and discovers a generalized version of a translated IMO theorem...’ - Metaculus prediction of an open-source AI winning IMO Gold Medal in Jan/2028 closer to being achieved. Human crowd-sourced estimates about exponential growth may be becoming irrelevant. - DeepMind CEO Demis: '[AlphaGeometry is] Another step on the road to AGI.' (Twitter) |
Paper, DeepMind blog, Author explanation (video) |
| Jan/2024 | 64%: Embodiment: Figure 01 makes a coffee. ‘Learned this after watching humans make coffee... Video in, trajectories out.’ | |
| Dec/2023 | 64%: DeepMind: LLMs can now produce new maths discoveries and solve real-world problems. DeepMind head of AI for science (14/Dec/2023 Guardian, MIT): ‘this is the first time that a genuine, new scientific discovery has been made by a large language model... It’s not in the training data—it wasn’t even known.’
Paper: ‘the first time a new discovery has been made for challenging open problems in science or mathematics using LLMs. FunSearch discovered new solutions... its solutions could potentially be slotted into a variety of real-world industrial systems to bring swift benefits... the power of these models [tested with Codey PaLM 2 340B] can be harnessed not only to produce new mathematical discoveries, but also to reveal potentially impactful solutions to important real-world problems.’ Sidenote: In Feb/2007, fellow Aussie Prof Terry Tao called the cap set question his 'favorite open question'. In Jun/2023 Terry also said that LLMs would take another three years to reach this level of progress ('2026-level AI... will be a trustworthy co-author in mathematical research'). Read more about exponential growth (wiki). |
Paper, explanation |
| Dec/2023 | 61%: Embodiment: Tesla Optimus Gen 2 | Bloomberg |
| Dec/2023 | 61%: LLMs for optimizing hyperparameters. ‘LLMs are a promising tool for improving efficiency in the traditional decision-making problem of hyperparameter optimization.’ | Paper |
| Dec/2023 | 61%: Google Gemini Ultra breaks 90% mark for MMLU. Also has proper multimodality [inputs were text, image, audio, video; outputs are text, image]. For the first time, a large language model has breached the 90% mark on MMLU, designed to be very difficult for AI. Gemini Ultra scored 90.04%; average humans are at 34.5% (AGI) while expert humans are at 89.8% (ASI). GPT-4 was at 86.4%. Watch the Gemini demo video. | Annotated paper, Models Table |
| Oct/2023 | 56%: Boston Dynamics: More embodiment using Spot + ChatGPT + LLMs. | YouTube (3m7s) |
| Oct/2023 | INFO: OpenAI CEO: ‘We define AGI as the thing we don't have quite yet. There were a lot of people who would have—ten years ago [2013 compared to 2023]—said alright, if you can make something like GPT-4, GPT-5, that would have been an AGI... I think we're getting close enough to whatever that AGI threshold is going to be.’ | WSJ 22/Oct /2023 YouTube (5m25s) |
| Oct/2023 | INFO: Google VP and Fellow Blaise Agüera y Arcas says 'AGI is already here': 'The most important parts of AGI have already been achieved by the current generation of advanced AI large language models... [2023's] most advanced AI models have many flaws, but decades from now, they will be recognized as the first true examples of artificial general intelligence.' | NOEMA |
| Oct/2023 | INFO: Even more Gobi/GPT-5 rumors and analysis, Oct/2023. | Reddit (archive) |
| Oct/2023 | 55%: Microsoft: ‘GPT-4 in our proof-of-concept experiments, is capable of writing code that can call itself to improve itself.’ | Paper (arxiv) |
| Sep/2023 | INFO: OpenAI Gobi/GPT-5 rumors and analysis, early rumors from Sep/2023. | Shared Google Doc |
| Sep/2023 | 55%: Harvard studies BCG consultants with GPT-4, ‘Consultants using [GPT-4] AI were significantly more productive (they completed 12.2% more tasks on average, and completed tasks 25.1% more quickly), and produced significantly higher quality results (more than 40% higher quality...)’ | Paper (SSRN) |
| Sep/2023 | 55%: Google OPRO self-improves, ‘prompts optimized by OPRO outperform human-designed prompts by up to 8% on GSM8K [maths], and by up to 50% on Big-Bench Hard [IQ] tasks.’ | Paper (arxiv) |
| Aug/2023 | 54%: GPT-4 scores in 99th percentile for Torrance Tests of Creative Thinking (wiki), questions by Scholastic Testing Service confirmed private/not part of training dataset. | Article |
| Jul/2023 | 54%: Google DeepMind Robotics Transformer RT-2 (3x improvement over RT-1, 2x improvement on unseen scenarios to 62% avg. Progress towards Woz's AGI coffee test.) | Project page |
| Jul/2023 | 52%: Anthropic Claude 2: More HHH (TruthfulQA Claude 2=0.69 vs GPT-4=0.60) | Anthropic (PDF), Models Table |
| Jul/2023 | 51%: Google DeepMind/ Princeton: Robots that ask for help ('modeling uncertainty that can complement and scale with the growing capabilities of foundation models.') | Project page |
| Jul/2023 | 51%: Microsoft LongNet: 1B token sequence length ('opens up new possibilities for modeling very long sequences, e.g., treating a whole corpus or even the entire Internet as a sequence.') | Microsoft (arxiv) |
| Jun/2023 | 50%: Google DeepMind RoboCat ('autonomous improvement loop... RoboCat not only shows signs of cross-task transfer, but also becomes more efficient at adapting to new tasks.') | DeepMind blog, Paper (PDF) |
| Jun/2023 | 50%: Microsoft introduces monitor-guided decoding (MGD) ('improves the ability of an LM to... generate identifiers that match the ground truth... improves compilation rates and agreement with ground truth.') | Paper (arxiv) |
| Jun/2023 | 50%: Ex-OpenAI consultant uses GPT-4 for embodied AI in chemistry ('instructions, to robot actions, to synthesized molecule.') | Paper (arxiv), notes |
| Jun/2023 | 50%: Harvard introduces 'inference-time intervention' (ITI) ('At a high level, we first identify a sparse set of attention heads with high linear probing accuracy for truthfulness. Then, during inference, we shift activations along these truth-correlated directions. We repeat the same intervention autoregressively until the whole answer is generated.') | Harvard (arxiv) |
| Jun/2023 | 49%: Google DeepMind trains an LLM (DIDACT) on iterative code in their 86TB code repository ('the trained model can be used in a variety of surprising ways... by chaining together multiple predictions to roll out longer activity trajectories... we started with a blank file and asked the model to successively predict what edits would come next until it had written a full code file. The astonishing part is that the model developed code in a step-by-step way that would seem natural to a developer') | Google Blog, Twitter |
| May/2023 | 49%: Ability Robotics combines an LLM with their humanlike android (robot), Digit. | Agility Robotics (YouTube) |
| May/2023 | 49%: PaLM 2 breaks 90% mark for WinoGrande. For the first time, a large language model has breached the 90% mark on WinoGrande, a 'more challenging, adversarial' version of Winograd, designed to be very difficult for AI. Fine-tuned PaLM 2 scored 90.9%; humans are at 94%. | PaLM 2 paper (PDF, Google), Models Table |
| May/2023 | 49%: Robot + text-davinci-003 (‘...we show that LLMs can be directly used off-the-shelf to achieve generalization in robotics, leveraging the powerful summarization capabilities they have learned from vast amounts of text data.’). | Princeton/ Google/ others |
| Apr/2023 | 48%: Boston Dynamics + ChatGPT (‘We integrated ChatGPT with our [Boston Dynamics Spot] robots.’). | Levatas |
| Mar/2023 | 48%: Microsoft introduces TaskMatrix.ai (‘We illustrate how TaskMatrix.AI can perform tasks in the physical world by [LLMs] interacting with robots and IoT devices… All these cases have been implemented in practice... understand the environment with camera API, and transform user instructions to action APIs provided by robots... facilitate the handling of physical work with the assistance of robots and the construction of smart homes by connecting IoT devices…’). | Microsoft (arxiv) |
| Mar/2023 | 48%: OpenAI introduces GPT-4, Microsoft research on record that GPT-4 is 'early AGI' (‘Given the breadth and depth of GPT-4's capabilities, we believe that it could reasonably be viewed as an early (yet still incomplete) version of an artificial general intelligence (AGI) system.’). Microsoft's deleted original title of the paper was 'First Contact With an AGI System'. Note that LLMs are still not embodied, and this countdown requires physical embodiment to get to 60%. |
Microsoft Research, Models Table |
| Mar/2023 | 42%: Google introduces PaLM-E 562B (PaLM-Embodied. 'PaLM-E can successfully plan over multiple stages based on visual and language input... successfully plan a long-horizon task...'). | Google, Models Table |
| Feb/2023 | 41%: Microsoft used ChatGPT in robots, it self-improved ('we were impressed by ChatGPT’s ability to make localized code improvements using only language feedback.'). | Microsoft |
| Dec/2022 | 39%: Anthropic RL-CAI 52B trained by Reinforcement Learning from AI Feedback (RLAIF) (‘we have moved further away from reliance on human supervision, and closer to the possibility of a self-supervised approach to alignment’). | LifeArchitect.ai, Anthropic paper (PDF), Models Table |
| Jul/2022 | 39%: NVIDIA's Hopper (H100) circuits designed by AI ('The latest NVIDIA Hopper GPU architecture has nearly 13,000 instances of AI-designed circuits'). | LifeArchitect.ai, NVIDIA |
| May/2022 | 39%: DeepMind Gato is the first generalist agent, that can ‘play Atari, caption images, chat, stack blocks with a real robot arm, and much more’. | Paper, Watch Alan's video about Gato, Models Table |
| Jun/2021 | 31%: Google's TPUv4 circuits designed by AI (‘allowing chip design to be performed by artificial agents with more experience than any human designer. Our method was used to design the next generation of Google’s artificial intelligence (AI) accelerators, and has the potential to save thousands of hours of human effort for each new generation. Finally, we believe that more powerful AI-designed hardware will fuel advances in AI, creating a symbiotic relationship between the two fields’). | LifeArchitect.ai, Nature, Venturebeat |
| Feb/2021 | INFO: Olfaction (smell). An odor [fragrance] map achieves human-level odor description performance and generalizes to diverse odor-prediction tasks. | Manuscript Feb/2021 (PDF), Preprint Sep/2022, Science Aug/2023 |
| Nov/2020 | 30%: GPT-3. Connor Leahy, Co-founder of EleutherAI, re-creator of GPT-2, creator of GPT-J & GPT-NeoX-20B, said about OpenAI GPT-3: ‘I think GPT-3 is artificial general intelligence, AGI. I think GPT-3 is as intelligent as a human. And I think that it is probably more intelligent than a human in a restricted way… in many ways it is more purely intelligent than humans are. I think humans are approximating what GPT-3 is doing, not vice versa.’ | Watch the video (timecode) |
| Aug/2017 | 20%: Google Transformer leads to big changes for search, translation, and language models. | Read the launch in plain English. |
| Earlier | 0 ➜ 10%: Foundational research by Prof Warren McCulloch, Prof Walter Pitts, & Prof Frank Rosenblatt (Perceptron), Dr Alan Turing & Prof John von Neumann (intelligent machinery), Prof Marvin Minsky, Prof John McCarthy, and many others (neural networks and beyond)... | Turing 1948: prepared by 'Gabriel' |







AGI levels
Now:
 Want the text of this viz? Upload the image above to a frontier vision model and ask for your desired output (text, Markdown, HTML, Bootstrap table, CSV, XLS...)
Want the text of this viz? Upload the image above to a frontier vision model and ask for your desired output (text, Markdown, HTML, Bootstrap table, CSV, XLS...)
Original:

Where will AGI be born?
Viz updated Jun/2025, Download PDF


Source: Models Table Rankings.
Exponential progress
Further reading










AGI expert critique (Oct/2025)
Alan's response to a new definition of AGI as 'expert'
A new paper, ‘A Definition of AGI’, has been released by Hendrycks et al. (Oct/2025, agidefinition.ai + followup 22/Oct/2025). While it presents a structured approach, it has several fundamental flaws that clash with the long-standing definition and conservative countdown milestones used on this page.
The wrong target. The new framework redefines AGI (a 100% AGI score) as ‘a “highly proficient” well-educated individual who has achieved mastery across [domains]’, a significant departure from the traditional definition of AGI as an average (median) human. AGI has always been about median capabilities; expert-level performance is the domain of ASI (artificial superintelligence, see LifeArchitect.ai/ASI). This feels like a classic case of moving the goalposts just as we're about to reach them.
The controversial CHC model. The paper's entire methodology is built on the Cattell-Horn-Carroll (CHC) theory of human intelligence. This is a questionable foundation. As a former expert on prodigies, my post-graduate research in Gifted Education and two terms as Chairman for Mensa International's gifted families committee highlighted the CHC model as highly controversial. Critics have pointed out significant incongruencies, leading some to call for an ‘annulment of this arranged but unhappy marriage’ (2019). A key proponent of the CHC model, paper co-author Prof Kevin McGrew, has stated on the public record that ‘…there is no g [general intelligence] in these models because… I think g is a statistical artifact…’, a controversial position that is antithetical with Carroll and widely-accepted definitions of intelligence. Building a post-hoc definition for artificial general intelligence on such a conflicted and unstable model is problematic at best.
The embodiment blind spot. The paper deliberately excludes physical abilities, following a focus on ‘the capabilities of the mind rather than the quality of its actuators or sensors’. This is a fundamental misunderstanding. An intelligence that cannot physically interact with the world is not general. My definition has always included embodiment, which is why the current exponential pace of progress in LLM-backed robotics is a key part of this AGI countdown.
The biased authorship. The inclusion of some authors, and particularly a long-time AI critic from NYU, lends the paper an intellectually dishonest bias. It seems to frame AGI through a lens that is predetermined to find fault with current systems.
The paper’s conclusion that GPT-4=27% and GPT-5=58% toward AGI is a direct result of this flawed definition. It contrasts with this page's long-running analysis, which placed GPT-4=48% and o3=88% (the comparable model behind GPT-5 thinking), with progress to Oct/2025 at 95% based on consistent, justified milestones since 2020. While the paper correctly identifies the asynchronous (‘jagged’) intelligence profile of current models, its overall position seems designed to shift the definition of AGI into something it was never intended to be, introducing unnecessary complexity and distortion that obscures measurable progress rather than helping to clarify it.
— ADT, 16/Oct/2025
■
Older AGI countdown graphs (2023)
AGI dates predicted based on this table (#predict)
Thanks to Dennis Xiloj. In Dec/2023, using the current milestones and percentages, GPT-4 now says AGI by 26/Jan/2025...
End of year update on #AGI, as usual using data from @dralandthompson conservative countdown to AGI. Are we accelerating? last one predicted april, now its january. pic.twitter.com/On5cYSLEgq
— Dennis Xiloj (@denjohx) December 26, 2023
Thanks to Dennis Xiloj. In Jun/2023, using the current milestones and percentages, GPT-4 says AGI by 18/Jul/2025...
As requested by @dralandthompson , here is the data updated from https://t.co/5zW33mS4VO, fitted to exponential growth. Seems we will reach AGI in july 2025? pic.twitter.com/Ei4CFwkBVz
— Dennis Xiloj (@denjohx) June 23, 2023
Thanks to The Memo reader BeginningInfluence55 for this more conservative version using polynomial regression. In Jul/2023, using the current milestones and percentages, this method says 100% AGI by Oct/2026...
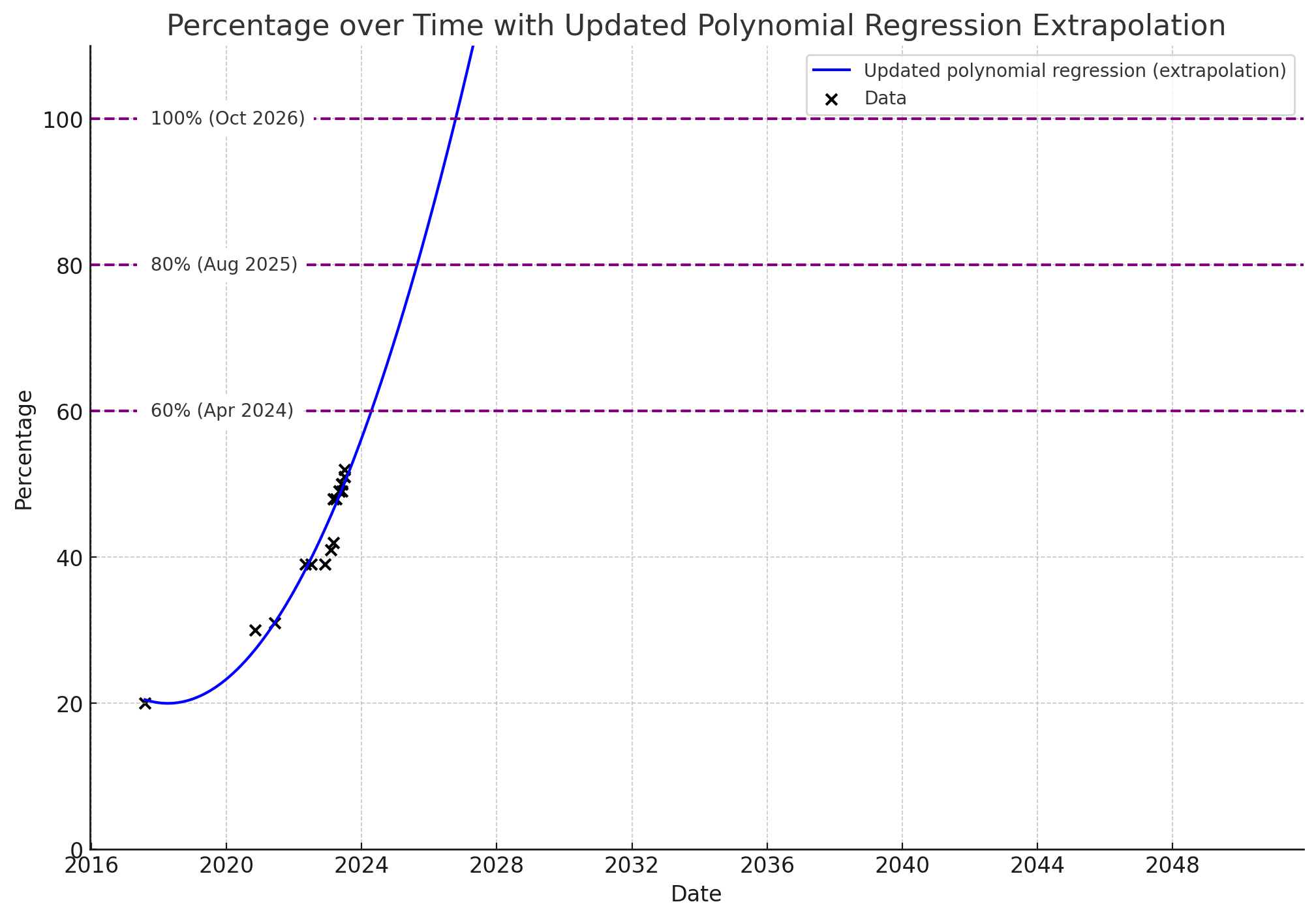
A third analysis was provided by 'SecretMan' in Oct/2023, with this chart showing 100% AGI by Jul/2026...
Key milestones 50–80%
Key milestones 50–80%
- Around 50%: HHH: Helpful, honest, harmless as articulated by Anthropic, with a focus on groundedness and truthfulness. Mustafa Suleyman is the Co-founder of DeepMind, and Founder of Inflection AI (pi.ai), and says: 'LLM hallucinations will be largely eliminated by 2025'.
LLM hallucinations will be largely eliminated by 2025.
that’s a huge deal. the implications are far more profound than the threat of the models getting things a bit wrong today.
— Mustafa Suleyman (@mustafasuleyman) June 9, 2023
- Around 60%: Physical embodiment backed by a large language model. The AI is autonomous, and can move and manipulate. Current options include:
- OpenAI's 1X (formerly Halodi Robotics) EVE (wheeled) and NEO (bipedal).
- Sanctuary AI Phoenix.
- Agility Digit.
- Figure 01.
- Tesla Bot.
- Microsoft Autonomous Systems and Robotics Group.
- Google Robotics including the 2023 consolidation of Everyday Robots.
- ...and more.

See related page: Humanoid robots ready for LLMs.
- Around 80%: Passes Steve Wozniak's test of AGI: can walk into a strange house, navigate available tools, and make a cup of coffee from scratch (video with timecode).
Older stuff
Want the text of this viz? Upload the image above to a frontier vision model and ask for your desired output (text, Markdown, HTML, Bootstrap table, CSV, XLS...)
Dr Demis Hassabis, Google DeepMind founder, former child prodigy:
Suddenly the nature of money even changes... I don't know if company constructs would even be the right thing to think about... We don't want to have to wait till the eve before AGI happens... we should be preparing for that now. (24/Feb/2024)
 Download source (PDF)
Download source (PDF)
Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Related videos
Cite
Thompson, A. D. (2020–2026). Alan’s conservative countdown to AGI. LifeArchitect.ai. https://lifearchitect.ai/AGI/
Get The Memo
by Dr Alan D. Thompson · Be inside the lightning-fast AI revolution.Informs research at Apple, Google, Microsoft · Bestseller in 147 countries.
Artificial intelligence that matters, as it happens, in plain English.
Get The Memo.
 Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.
Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.This page last updated: 30/Mar/2026. https://lifearchitect.ai/agi/↑





