The Memo.
MMLU was saturated in Sep/2024 by OpenAI o1-preview @ 92.3% (MMLU ceiling is around 91%).
MMLU-Pro was saturated in Nov/2025 by Google Gemini 3 Pro @ 90.1% (MMLU-Pro ceiling is around 90%).
GPQA was saturated in Nov/2025 by Google Gemini 3 Pro @ 93.8% (GPQA ceiling is around 80%).
HLE was close to saturation in Dec/2025 by OpenAI GPT-5.2 @ 50% (HLE ‘supported by research’ ceiling 51.3% via FutureHouse or only 25.6% via Alibaba Feb/2026).
Get The Memo.
Alan D. Thompson
August 2024 (updated 2025)
| MMLU | MMLU-Pro | GPQA | HLE | |
|---|---|---|---|---|
| Name | Measuring Massive Multitask Language Understanding | MMLU-Pro | Graduate-Level Google-Proof Q&A | Humanity’s Last Exam |
| Author | Dan Hendrycks et al. | TIGER-Lab | NYU, Cohere, Anthropic | Center for AI Safety |
| Question count | ~16,000 | ~12,000 | 448 | 3,000 |
| Choices per question | 4 | 10 | 4 | Free-text (or 5+ when multi-choice) |
| Chance accuracy | 25% | 10% | 25% | ~4.8% (24% multi-choice, 5 or more options) |
| Highest score (2025Q1) | 92.3% (o1-preview) |
91.0% (o1-preview) |
87.7% (o3) |
14% (o3-mini-high) |
| Ceiling | ~91% (UoE) | ~90% | ~80% (subset dependent) | ~50% (FutureHouse) ~26% (Alibaba) |
| Notes | Multisubject benchmark; 10% dataset errors limit max score | More challenging; 10-choice format | PhD-level, ‘Google-proof’ questions in STEM. Diamond subset=198 questions. | Includes multimodal tasks |
“[o1] destroyed the most popular reasoning benchmarks… They’re now crushed.”
— Dr Dan Hendrycks, creator of MMLU and MATH (Reuters, 17/Sep/2024)
Viz

Download source (PDF)
Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Mapping table
OpenAI o1 (Sep/2024) assisted with the following table based on all models with an MMLU-Pro score (at minimum, usually with both MMLU and GPQA scores) in the Models Table. The o1 model thought for 153 seconds to provide this table output. In Apr/2025, with a lot of hand holding, o3-mini-high was used to add the HLE calcs. There is a fair error margin (estimate ±5%) in final scores as well as variation between testing methodologies and reporting, so these correlations should be used as a rough guide only.
- MMLU-Pro Score: Approximately calculated as
MMLU Score - 20. - GPQA Score: Approximately calculated as
2 × MMLU Score - 110. - HLE Score: Approximately calculated as
(GPQA Score – 35) / 5.
| MMLU | MMLU-Pro | GPQA | HLE |
|---|---|---|---|
| – | – | 85 | 10 |
| 95 | 75 | 80 | 9 |
| 90 | 70 | 70 | 7 |
| 85 | 65 | 60 | 5 |
| 80 | 60 | 50 | 3 |
| 75 | 55 | 40 | 1 |
| 70 | 50 | 30 | 0 |
Notes
Benchmark results are from primary sources as compiled in my Models Table.
MMLU is no longer a reliable benchmark and, due to errors, has an ‘uncontroversially correct’ ceiling of about 91%. Gema found that over 9% of questions in the MMLU benchmark contain errors based on expert review of 3,000 randomly sampled questions. Read more: https://arxiv.org/pdf/2406.04127#page=5 & Errors in the MMLU: The Deep Learning Benchmark is Wrong Surprisingly Often – Daniel Erenrich.
GPQA has an ‘uncontroversially correct’ ceiling of about 80%, depending on the subset. The questions on this benchmark are extremely difficult (designed and tested by PhDs), and there must have been a challenge in finding humans smart enough to both design the test questions, and provide ‘uncontroversially correct’ answers. The paper notes (PDF, p8): ‘After an expert validator answers a question, we show them the question writer’s answer and explanation and ask them if they believe the question is objective and its answer is uncontroversially correct… On the full 546 questions, the first expert validator indicates positive post-hoc agreement on 80.1% of the questions, and the second expert validator indicates positive post-hoc agreement on 85.4% of the questions…Using a relatively conservative level of permissiveness, we estimate the proportion of questions that have uncontroversially correct answers at 74% on GPQA Extended. Because the main [448] and diamond [198, both experts agree] sets are filtered based on expert validator accuracy, we expect the objectivity rate to be even higher on those subsets.’
HLE probably has an ‘uncontroversially correct’ ceiling of about 70%, with FutureHouse finding that ‘about 30% of Humanity’s Last Exam chemistry/biology answers are likely wrong… this arose from the [financial] incentive used to build the benchmark’. and ‘…when extrapolating to the full dataset, we expect 29.3% of the questions to be directly conflicted by research, [only] 51.3% to be supported by research, and 19.3% to be nuanced, depending on assumptions or opinions.’ My initial HLE formula above is based on GPQA score, and with only 10 data points available (minus outliers), is subject to update as this benchmark becomes more widely applied during 2025–2026.
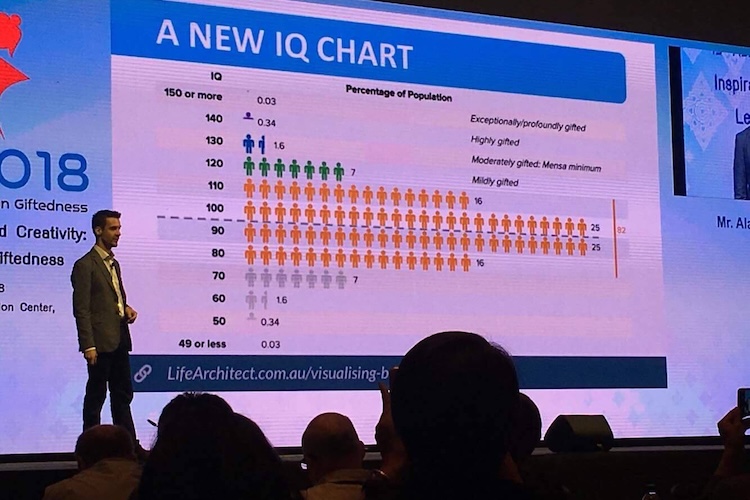
IQ results are by Prof David Rozado, as documented in my AI and IQ testing page. GPT-3.5-Turbo=147. GPT-4 Classic=152, replicated by Clinical psychologist Eka Roivainen using the WAIS III to assess ChatGPT (assuming GPT-4 Classic): verbal IQ of 155 (P99.987). Einstein is a well-known figure, and although he never took an IQ test, it is generally agreed that he had an estimated IQ around 160 (P99.996), see my Visualising Brightness report for numbers.
Error bars are not shown, but it can be assumed that there is a fair error margin (estimate ±5%) for all model results, and therefore the benchmark mapping in this analysis. This is primarily due to data contamination during training, where benchmark data (test questions and answers) is leaked into the training set and final model. See the Llama 2 paper for contamination discussion and working (PDF, pp75-76).
Conclusions
Parameters and tokens trained are no longer a precise indicator of power. Smaller models can now outperform larger models, and this is illustrated in benchmarks for GPT-4 Classic 1760B vs GPT-4o mini 8B (similar performance), and many other post-2023 models.
The landscape of artificial intelligence is rapidly evolving, challenging our traditional metrics for assessing AI capabilities. The emergence of smaller, more efficient models that rival or surpass their larger counterparts marks a significant shift in the field. This development underscores the importance of looking beyond raw computational power or parameter count when evaluating AI systems.
As we approach what may be the peak of intelligence that humans can readily comprehend and evaluate, the implications extend far beyond mere technological progress. The future of AI is not simply about more powerful machines, but about its potential to drive human evolution.
This paradigm shift is redefining our relationship with technology, opening new frontiers in human cognitive enhancement, problem-solving capabilities, and our understanding of intelligence itself.
As human intelligence and artificial intelligence converge, we are preparing for a transformative leap that will amplify our creative potential and propel humanity towards a future where the boundaries of cognition are limited only by our imagination.
What all this reminds me of
Source: Speed climbing, circa 2016.
Video
Get The Memo
by Dr Alan D. Thompson · Be inside the lightning-fast AI revolution.Informs research at Apple, Google, Microsoft · Bestseller in 147 countries.
Artificial intelligence that matters, as it happens, in plain English.
Get The Memo.
 Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.
Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.This page last updated: 22/Feb/2026. https://lifearchitect.ai/mapping/↑


