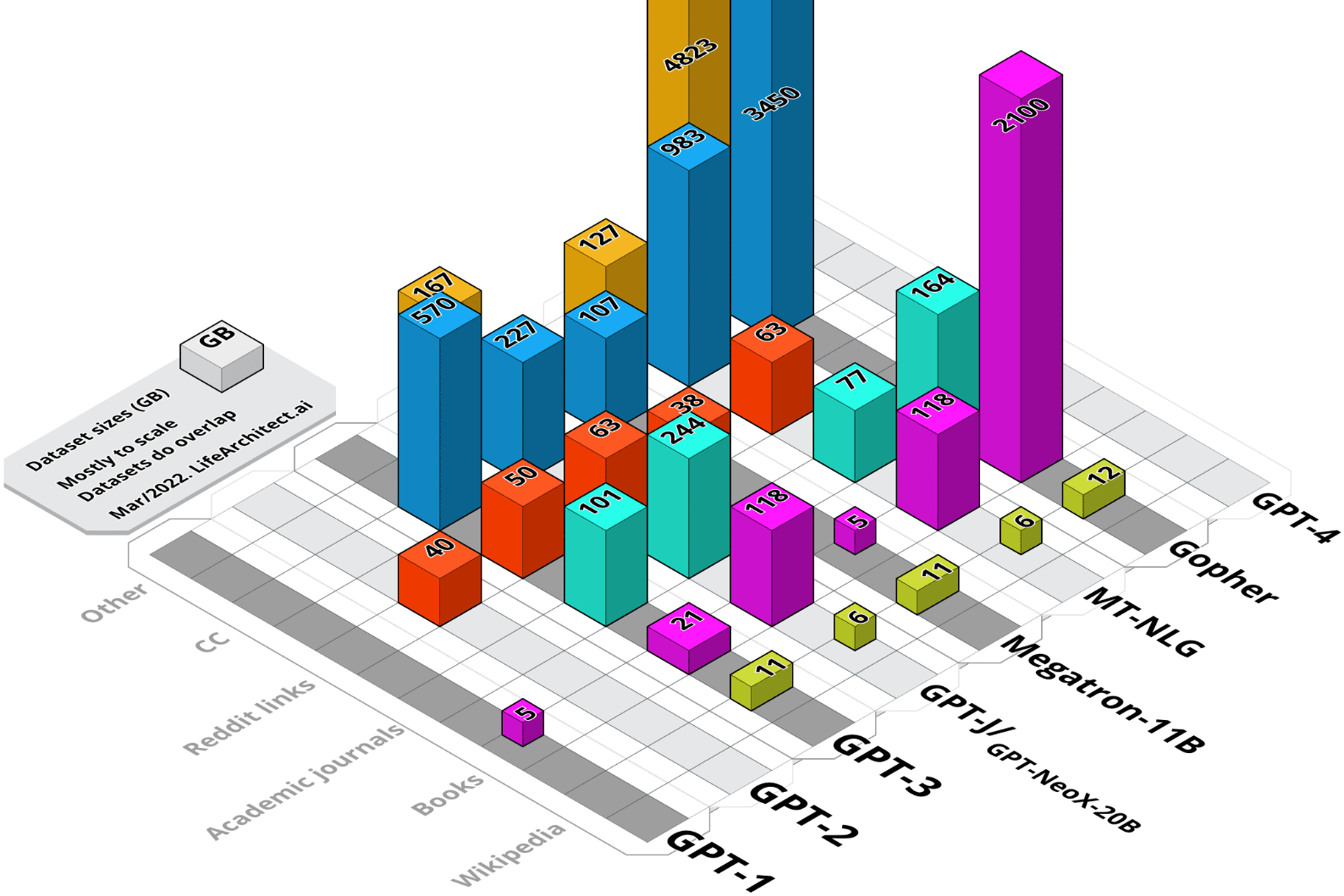
 A Comprehensive Analysis of Datasets Used to Train GPT-1, GPT-2, GPT-3, GPT-NeoX-20B, Megatron-11B, MT-NLG, and Gopher
A Comprehensive Analysis of Datasets Used to Train GPT-1, GPT-2, GPT-3, GPT-NeoX-20B, Megatron-11B, MT-NLG, and Gopher
Alan D. Thompson
LifeArchitect.ai
March 2022
26 pages incl title page, references, appendix.
Current datasets and updates since publication
Obviously a lot has changed since publication of this report back in Mar/2022. For the latest updates, see the Datasets Table.
Open the Datasets Table in a new tab
The 2022 paper
Reviews
Received by AllenAI (AI2).
Received by the UN.
Cited in lit review paper by USyd + USTC.
Abstract
Pre-trained transformer language models have become a stepping stone towards artificial general intelligence (AGI), with some researchers reporting that AGI may evolve from our current language model technology. While these models are trained on increasingly larger datasets, the documentation of basic metrics including dataset size, dataset token count, and specific details of content is lacking. Notwithstanding proposed standards for documentation of dataset composition and collection, nearly all major research labs have fallen behind in disclosing details of datasets used in model training. The research synthesized here covers the period from 2018 to early 2022, and represents a comprehensive view of all datasets—including major components Wikipedia and Common Crawl—of selected language models from GPT-1 to Gopher.
Contents
1. Overview
1.1. Wikipedia
1.2. Books
1.3. Journals
1.4. Reddit links
1.5. Common Crawl
1.6. Other
2. Common Datasets
2.1. Wikipedia (English) Analysis
2.2. Common Crawl Analysis
3. GPT-1 Dataset
3.1. GPT-1 Dataset Summary
4. GPT-2 Dataset
4.1. GPT-2 Dataset Summary
5. GPT-3 Datasets
5.1. GPT-3: Concerns with Dataset Analysis of Books1 and Books2
5.2. GPT-3: Books1
5.3. GPT-3: Books2
5.4. GPT-3 Dataset Summary
6. The Pile v1 (GPT-J & GPT-NeoX-20B) datasets
6.1. The Pile v1 Grouped Datasets
6.2. The Pile v1 Dataset Summary
7. Megatron-11B & RoBERTa Datasets
7.1. Megatron-11B & RoBERTa Dataset Summary
8. MT-NLG Datasets
8.1. Common Crawl in MT-NLG
8.2. MT-NLG Grouped Datasets
8.3. MT-NLG Dataset Summary
9. Gopher Datasets
9.1. MassiveWeb Dataset Analysis
9.2. Gopher: Concerns with Dataset Analysis of Wikipedia
9.3. Gopher: No WebText
9.4. Gopher Grouped Datasets
9.5. Gopher Dataset Summary
10. Conclusion
11. Further reading
Appendix A: Top 50 Resources: Wikipedia + CC + WebText (i.e. GPT-3)
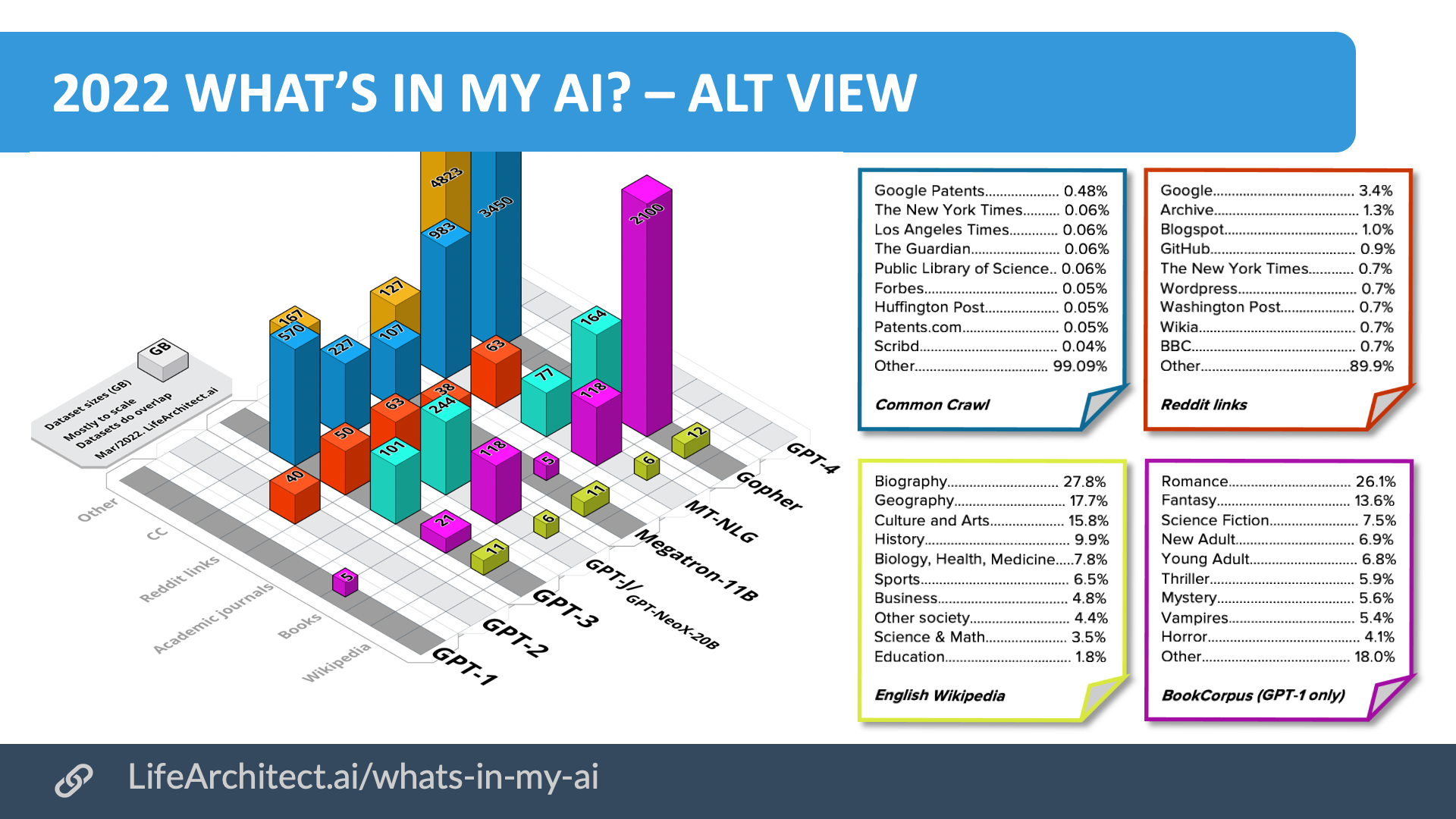
Download PDF of alt view (1920×1080 slide)
GPT-3’s top 10 datasets by domain/source

Download source (PDF)
Contents: View the data (Google sheets)
Video: Presentation of this paper @ Devoxx Belgium 2022
Get The Memo
by Dr Alan D. Thompson · Be inside the lightning-fast AI revolution.Bestseller. 10,000+ readers from 142 countries. Microsoft, Tesla, Google...
Artificial intelligence that matters, as it happens, in plain English.
Get The Memo.
 Dr Alan D. Thompson is an AI expert and consultant, advising Fortune 500s and governments on post-2020 large language models. His work on artificial intelligence has been featured at NYU, with Microsoft AI and Google AI teams, at the University of Oxford’s 2021 debate on AI Ethics, and in the Leta AI (GPT-3) experiments viewed more than 4.5 million times. A contributor to the fields of human intelligence and peak performance, he has held positions as chairman for Mensa International, consultant to GE and Warner Bros, and memberships with the IEEE and IET. Technical highlights.
Dr Alan D. Thompson is an AI expert and consultant, advising Fortune 500s and governments on post-2020 large language models. His work on artificial intelligence has been featured at NYU, with Microsoft AI and Google AI teams, at the University of Oxford’s 2021 debate on AI Ethics, and in the Leta AI (GPT-3) experiments viewed more than 4.5 million times. A contributor to the fields of human intelligence and peak performance, he has held positions as chairman for Mensa International, consultant to GE and Warner Bros, and memberships with the IEEE and IET. Technical highlights.This page last updated: 23/Jul/2024. https://lifearchitect.ai/whats-in-my-ai/↑


