 A Comprehensive Analysis of Datasets Likely Used to Train GPT-5
A Comprehensive Analysis of Datasets Likely Used to Train GPT-5
Alan D. Thompson
LifeArchitect.ai
August 2024
27 pages incl title page, references, appendices.
The report
Download report
(Available exclusively to full subscribers of The Memo.)

Reviews
Received by all major AI labs & intergovernmental orgs.
Cited in the G7 AI document, 2024, provided to leaders:
- USA (President Biden/President Trump)
- Japan (Prime Minister Shigeru Ishiba)
- Germany (Chancellor Olaf Scholz)
- United Kingdom (Prime Minister Keir Starmer)
- France (President Emmanuel Macron)
- Italy (Prime Minister Giorgia Meloni)
- Canada (Prime Minister Justin Trudeau)
Additionally, European Commission President Ursula von der Leyen, and European Council President António Costa.
Abstract
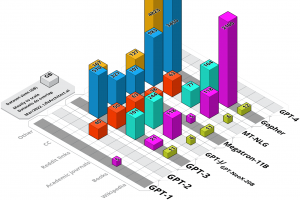
The rapid advancement of large language models (LLMs) has been accompanied by a corresponding decrease in transparency regarding their training data. As these models are developed using ever-expanding datasets, crucial information such as dataset size, token count, and content specifics has become increasingly obscure. Based on a thorough investigation of OpenAI’s known partnerships and collaborations with various organizations, this report provides a comprehensive analysis of more than 27 datasets totalling around half a quadrillion tokens in two petabytes of data before filtering. Following a cleaning process, this would become more than 70T tokens in 281TB used in training OpenAI GPT-5, and a rough parameter estimate is provided in this paper. Building on the acclaimed 2022 report, What’s in my AI?, and the pre-release analysis Google DeepMind Gemini: A general specialist, this report offers a quantitative foundation for exploring how frontier models powered by vast datasets are augmenting and expanding our cognitive capabilities, and ushering in a new era of superintelligence.
Contents
1. Overview
2. A note on very large numbers
3. Synthetic data
4. GPT-5 datasets: Advancing data quality, volume, and breadth
4.1. Synthetic
4.2. Reddit – Posts + Outbound Only (web)
4.3. Common Crawl – General (web)
4.4. Consensus NLP (academic papers)
4.5. YouTube (dialogue)
4.6. News Corp/WSJ (news articles)
4.7. Common Crawl – Edu (web)
4.8. Reddit – Comments Only (dialogue)
4.9. FreeLaw: PACER (legal)
4.10. GitHub (code)
4.11. Books2 (books)
4.12. FreeLaw: Opinions (legal)
4.13. Stack Exchange (Q&A)
4.14. Books3 (books)
4.15. Shutterstock (metadata)
4.16. Wikipedia – Multilingual (wiki)
4.17. Books1 (books)
4.18. Time Inc (news articles)
4.19. Le Monde and Prisa Media (news articles)
4.20. Wikipedia – English (wiki)
4.21. AP (news articles)
4.22. Dotdash Meredith (news articles)
4.23. FT (news articles)
4.24. Axel Springer SE (news articles)
4.25. Icelandic Government (multilingual data)
4.26. Khan Academy (Q&A)
4.27. ExamSolutions (Q&A)
4.28. Other
5. Conclusion
6. Further reading
Appendix A: Synthetic data topics (original via Cosmopedia)
Appendix B: General dataset calculations lookup table
Appendix C: GPT-5 dataset calculations (selected data only)
Cover image
Image generated in a few seconds, on 28 July 2024, text prompt by Alan D. Thompson, via Firefly Image 3 (art, 4:3): ‘navy blue data pattern, background’
Technical acknowledgments
Claude 3.5 Sonnet was used for some writing, copyediting, text manipulation, APA style referencing, OCR, and more.
GPT-4o was used for manipulating CSV files for the tables in the linked sheets and shown in the appendices.
Google Workspace was instrumental in facilitating complex linking with automatic updates between Sheets, Docs, and charting, allowing the draft of this paper to be completed in a single night.
The soundtrack to this paper was provided by 1980s Aussie band vSpy vSpy.
Synthetic data (extract from Section 3, p6-9 of the report)
Synthetic data is artificially generated information that mimics real-world data, used to train AI models. It is used when human-generated datasets are exhausted or unavailable, for increasing quantity, and—more recently—for increasing quality.
Up until the end of 2023, the use of synthetic data to train large language models was not widespread. While OpenAI did assign one of the GPT-4 team as a ‘synthetic data contributor’ in 2022, this role was specifically for the reinforcement learning and alignment process that happened after pre-training on the GPT-4 dataset was complete.
In October 2023, Microsoft sourced 6B tokens of human-generated ‘textbook quality’ data from the web, and used a large language model (OpenAI GPT-3.5) to generate another 1B tokens of synthetic data similar to the format of new textbooks and exercises. Later, Microsoft increased this to 20B tokens of synthetic data.
In March 2024, Hugging Face detailed an end-to-end process for generating synthetic text that they called ‘Cosmopedia’.
[For phi, Microsoft] curated 20,000 topics to produce 20 billion tokens of synthetic textbooks while using samples from web datasets for diversity… Assuming an average file length of 1000 tokens, this suggests using approximately 20 million distinct prompts…By targeting four different audiences (young children, high school students, college students, researchers) and leveraging three generation styles (textbooks, blog posts, wikiHow articles)… [Hugging Face created] over 30 million prompts for Cosmopedia….
Sourcing a nominal amount of web data, Hugging Face used a large language model (Mistral Mixtral-8x7B) to generate 25B tokens of ‘synthetic textbooks, blogposts, stories, posts and WikiHow articles’. To increase the variety of generated samples, the prompts leveraged diversity in audience and style, as illustrated in these three published Cosmopedia prompt examples for the same topic:
1. Kids. Write a long and very detailed course unit for a textbook on ‘Why Go To Space?’ intended for young children… Remember this unit is intended for young children books, so use very simple, everyday words and phrases that a 10-year-old would easily understand. Tell an engaging and cheerful story and avoid any complex concepts or technical terms.
2. Students. Write a long and very detailed course unit for a textbook on ‘Why Go To Space?’ intended for high school students… Use language and examples that would relate with teenage students balancing educational rigor with accessibility. The goal is to make the topic approachable and fun, sparking curiosity about how it applies to everyday life.
3. Professionals. Write a long and very detailed course unit for a textbook on ‘Why Go To Space?’ intended for professionals and researchers in the field… The content should aim to engage a highly knowledgeable audience with very deep expertise in the topic. Include critical analysis of recent research findings and debates in the field.
For GPT-4, the OpenAI ‘data team’ consisted of 35 people responsible for collecting and curating corpora for the dataset1GPT-4 paper, p15 within a total headcount of 1,200 staff.2Bloomberg, 4/Apr/2024: ‘OpenAI now has about 1,200 employees, Lightcap said.’ https://archive.md/SptzU Given unlimited access to frontier models and inference, as well as an extensive human workforce dedicated to dataset collection and curation, it would be trivial to build out high quality synthetic data against relevant topics, with the final dataset measured in trillions and then quadrillions of tokens. Notably, this process only needs to happen once, and the final ‘gold’ dataset can be used in training future models.
In the case of GPT-5, it has been reported that synthetic data comprises around… <see full report for details>
A complete list of 110 topics used for synthetic data generation via Cosmopedia is available in Appendix A, and outlined in the following table. For this report, topics have been assigned a category by GPT-4o, and the list has been sorted in alphabetical order. These categories can be compared with (but are not the same as) the proprietary library classification system, the Dewey Decimal Classification (DDC 23): Computer science (000), Philosophy and psychology (100), Religion (200), Social sciences (300), Language (400), Pure science (500), Technology (600), Arts and recreation (700), Literature (800), History and geography (900).
| Arts & Entertainment | Arts and Crafts, Fiction and Fantasy Writing, Literature and Creative Writing, Music, Performing Arts, Video Games, Visual Arts and Art Appreciation |
| Business & Economics | Business and Entrepreneurship, Business and Management, Career Development and Job Opportunities, Digital Marketing and Business, Economics and Finance, Finance and Investment, Insurance, Loans and Mortgages, Marketing and Business Strategies, Personal Finance and Investments, Product Marketing and Design, Real Estate & Investment, Taxation and Finance |
| Education & Learning | Education, Education and Youth Development, Human Resources / Organizational Management, Human Resources and Education, Leadership and Education, Writing and Storytelling |
| Food & Beverage | Cooking and Baking, Cooking and Recipes, Culinary Arts and Beverages, Wine & Winemaking |
| Health & Medicine | Addiction and Mental Illness, Cosmetic Surgery and Body Modifications, Dentistry, Entomology and Apiculture, HIV Treatment and Care, Healthcare & Medical Services, Healthcare and Operations Management, Infant Feeding and Child Development, Medicine, Mental Health Counseling, Mental Health and Therapy, Nutrition and Health, Pharmaceutical manufacturing and technology, Psychology |
| Home & Lifestyle | Audio Equipment and Home Theater Systems, Automotive Parts and Accessories, Cleaning and Maintenance, Home Improvement and Maintenance, Online Chat Platforms and Data Privacy, Pets and Pet Care, Recreational Fishing, Travel, Waste Management and Recycling, Watchmaking and Horology |
| Law & Policy | International Relations and Conflict, International Relations and Current Events, International Relations and Politics, Legal Services and Issues, Legal Studies / Law, Legal Studies and Public Policy, Political Science, Politics and Government |
| Lifestyle & Culture | Astrology, Cannabis and CBD Products, Christian Theology and Spirituality, Christianity and Theology, Events and Community Happenings, Fashion & Apparel, Hair Care, Hair Care and Styling, Health and Lifestyle, Jewelry Design and Manufacturing, Online Dating & Relationships, Personal Development and Empowerment, Skincare and Beauty Products |
| Public Affairs & Safety | Fire Incidents, Gun Control and Violence, Public Administration and Policy, Public Safety and Emergency Response, Public Transit and Transportation |
| Science & Technology | Astronomy and Astrophysics, Biochemistry and Molecular Biology, Computer Antivirus Software and Security, Computer Hardware and Graphics Cards, Computer Programming and Web Development, Computer Science, Computer Security & Privacy, Cryptocurrency and Blockchain Technology, Data Privacy and Protection, Digital Imaging and Photography, Electric Vehicles and Battery Technology, Energy and Environmental Policy, Energy and Natural Resources, Genetics and Mental Health, Geography and Weather, Lighting Design and Technology, Molecular Biology and Genetics, Online Platforms & Web Technologies, Technology and Computer Science, Technology and Consumer Electronics |
| Sports & Physical Activities | American Football, Baseball, Cricket, Football/Soccer, Ice Hockey, Physical Fitness and Health, Professional Basketball/NBA, Professional Wrestling and Sports Entertainment, Sports and Education, Tennis |
Table. List of topics for use in synthetic data generation. Data source: Cosmopedia repo, list categorized and formatted by GPT-4o for this report.
Viz
Figure 1. GPT-5 datasets by type (filtered, includes synthetic data).
Figure 2. GPT-5 datasets by type (filtered, synthetic data not shown).
Figure 3. GPT-5 datasets by token count. Logarithmic scale, billions of tokens.
All dataset reports by LifeArchitect.ai (most recent at top)| Date | Type | Title |
| Dec/2025 | 📑 | Genesis Mission |
| Jan/2025 | 📑 | What's in Grok? |
| Jan/2025 | 💻 | NVIDIA Cosmos video dataset |
| Aug/2024 | 📑 | What's in GPT-5? |
| Jul/2024 | 💻 | Argonne AuroraGPT |
| Sep/2023 | 📑 | Google DeepMind Gemini: A general specialist |
| Feb/2023 | 💻 | Chinchilla data-optimal scaling laws: In plain English |
| Aug/2022 | 📑 | Google Pathways |
| Mar/2022 | 📑 | What's in my AI? |
| Sep/2021 | 💻 | Megatron the Transformer, and related language models |
| Ongoing... | 💻 | Datasets Table |
Get The Memo
by Dr Alan D. Thompson · Be inside the lightning-fast AI revolution.Informs research at Apple, Google, Microsoft · Bestseller in 147 countries.
Artificial intelligence that matters, as it happens, in plain English.
Get The Memo.
 Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.
Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.This page last updated: 29/Jan/2025. https://lifearchitect.ai/whats-in-gpt-5/↑
- 1GPT-4 paper, p15
- 2Bloomberg, 4/Apr/2024: ‘OpenAI now has about 1,200 employees, Lightcap said.’ https://archive.md/SptzU