Get The Memo.
UniLM (2023 predictive text model)

See original posts about this model:
https://jackcook.com/2023/09/08/predictive-text.html
https://github.com/jackcook/predictive-spy
OpenELM (2024 On-Device model)
 Source: Apple State of the Union Jun/2024
Source: Apple State of the Union Jun/2024
They may be four years behind GPT-3, but Apple has finally offered integrated AI—including a clunky integration of ChatGPT that asks permission before proceeding—to its users on iOS and Mac. Apple’s annual Worldwide Developers Conference (WWDC) revealed ‘Apple Intelligence’ or extended AI functionality to most users of its 2.2 billion active Apple devices.
The on-device model is 3B parameters using GQA and LoRA (Apple, 10/Jun/2024). It is most likely a model called OpenELM 3.04B trained on 1.5T tokens, documented by Apple in Apr/2024. MMLU=26.76.
Read the OpenELM paper: https://arxiv.org/abs/2404.14619
View the OpenELM repo: https://huggingface.co/apple/OpenELM-3B-Instruct
See it on the models table: https://lifearchitect.ai/models-table/
Apple revealed some very limited rankings (and only bfloat16 precision evaluations) for both models:
Both the on-device and server models use grouped-query-attention. We use shared input and output vocab embedding tables to reduce memory requirements and inference cost…
For on-device inference, we use low-bit palletization, a critical optimization technique that achieves the necessary memory, power, and performance requirements. To maintain model quality, we developed a new framework using LoRA adapters that incorporates a mixed 2-bit and 4-bit configuration strategy — averaging 3.5 bits-per-weight — to achieve the same accuracy as the uncompressed models.
…the ~3 billion parameter on-device model, the parameters for a rank 16 adapter typically require 10s of megabytes. The adapter models can be dynamically loaded, temporarily cached in memory, and swapped — giving our foundation model the ability to specialize itself on the fly for the task at hand while efficiently managing memory and guaranteeing the operating system’s responsiveness.
 Source: Apple State of the Union Jun/2024
Source: Apple State of the Union Jun/2024
The OpenELM dataset is:
| Source | Subset | Tokens |
|---|---|---|
| RefinedWeb | 665B | |
| RedPajama | Github | 59B |
| Books | 26B | |
| ArXiv | 28B | |
| Wikipedia | 24B | |
| StackExchange | 20B | |
| C4 | 175B | |
| The Pile | 207B | |
| Dolma | The Stack | 411B |
| 89B | ||
| PeS2o [~40M academic papers] | 70B | |
| Project Gutenberg | 6B | |
| Wikipedia + Wikibooks | 4.3B |
Source: OpenELM paper, p2, Table 2 Dataset used for pre-training OpenELM.
- RefinedWeb: 665B
- Dolma: 580.3B (411B + 89B + 70B + 6B + 4.3B)
- RedPajama: 332B (59B + 26B + 28B + 24B + 20B + 175B)
- The Pile: 207B
- Total: 1784.3B
Read more about the contents of these datasets in my 2022 What’s in my AI? paper.
As an interesting sidenote:
- A Google query for “OpenELM” within 24h of Apple WWDC returned just 156 results.
- A Google query for “GPT-4o” within 24h of OpenAI Spring Update event returned 83,400,000 results.
Server-based model (2024)
The server-based model is possibly a version of Apple’s Ferret (Oct/2023) and Ferret-UI (Apr/2024), both based on Vicuna 13B, a Llama-2 derivative with a ‘commercial-friendly’ license covering less than 700M users only. Any legal agreements between Apple and Meta would be behind closed doors, but it certainly makes me wonder…
Read the Ferret paper: https://arxiv.org/abs/2310.07704
Read the Ferret-UI paper: https://arxiv.org/abs/2404.05719
View the Ferret repo: https://github.com/apple/ml-ferret
The server-based model could also be Apple GPT 200B, using their Ajax framework.
[Apple] has built its own framework to create large language models — the AI-based systems at the heart of new offerings like ChatGPT and Google’s Bard — according to people with knowledge of the efforts. With that foundation, known as “Ajax,” Apple also has created a chatbot service that some engineers call “Apple GPT.”Ajax was first created last year (2022) to unify machine learning development at Apple, according to the people familiar with the effort.
Read more via Bloomberg (19/Jul/2023): https://archive.md/f3C0r
Comparisons with other LLMs
2026 frontier AI models + highlights
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Older bubbles viz
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Oct/2024
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Feb/2024

Nov/2023
 Download source (PDF)
Download source (PDF)Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Mar/2023
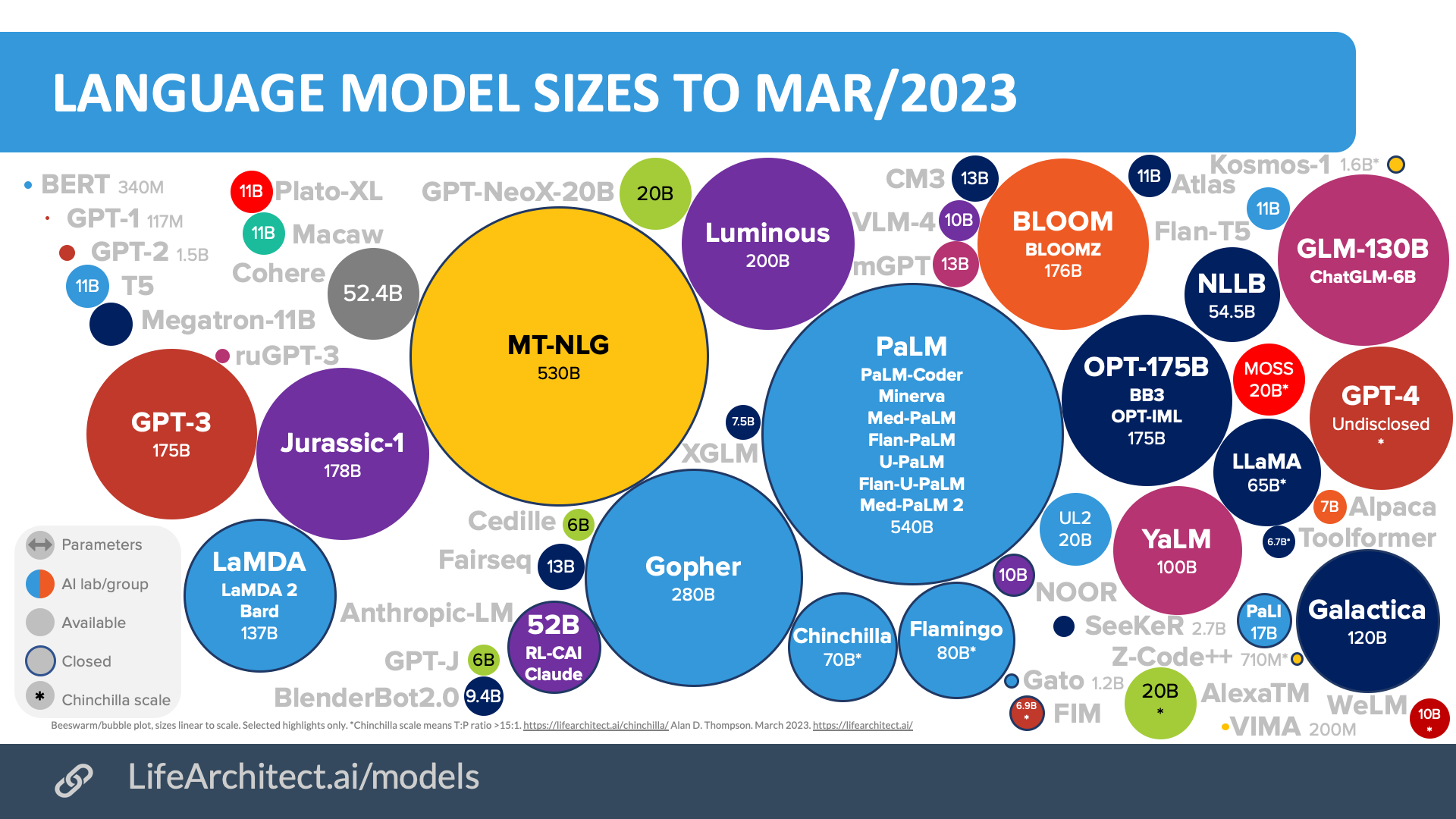 Download source (PDF)
Download source (PDF)
Apr/2022
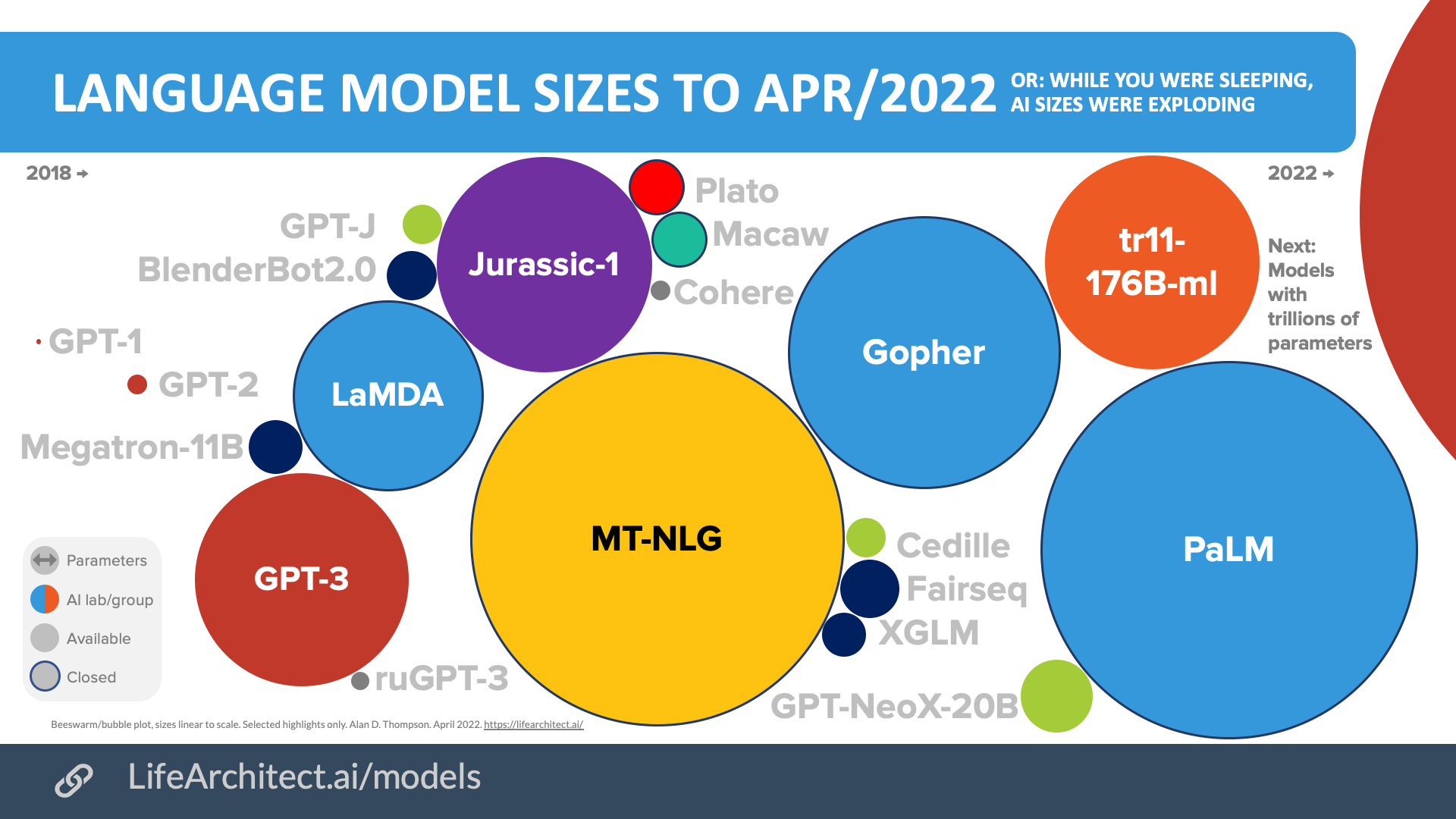 Download source (PDF)
Download source (PDF)
Models Table
Summary of current models: View the full data (Google sheets)Get The Memo
by Dr Alan D. Thompson · Be inside the lightning-fast AI revolution.Informs research at Apple, Google, Microsoft · Bestseller in 147 countries.
Artificial intelligence that matters, as it happens, in plain English.
Get The Memo.
 Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.
Alan D. Thompson is a world expert in artificial intelligence, advising everyone from Apple to the US Government on integrated AI. Throughout Mensa International’s history, both Isaac Asimov and Alan held leadership roles, each exploring the frontier between human and artificial minds. His landmark analysis of post-2020 AI—from his widely-cited Models Table to his regular intelligence briefing The Memo—has shaped how governments and Fortune 500s approach artificial intelligence. With popular tools like the Declaration on AI Consciousness, and the ASI checklist, Alan continues to illuminate humanity’s AI evolution. Technical highlights.This page last updated: 12/Jun/2024. https://lifearchitect.ai/apple/↑