%
Last update: May/2024
Track this countdown’s progress with readers from all around the world.
Get The Memo.
Definition of AGI
Definition
AGI = artificial general intelligence = a machine that performs at the level of an average (median) human.
ASI = artificial superintelligence = a machine that performs at the level of an expert human in practically any field.
I use a slightly stricter definition for AGI that includes the ability to act on the physical world via embodiment. I appreciate that there were some approaches on getting to AGI that fully bypass embodiment or robotics.
Artificial general intelligence (AGI) is a machine capable of understanding the world as well as—or better than—any human, in practically every field, including the ability to interact with the world via physical embodiment.
And the short version: ‘AGI is a machine which is as good or better than a human in every aspect’.
 The world and acceptance of AGI
The world and acceptance of AGI
Why does AGI need physical embodiment?
Here are some additional considerations for this thought experiment:
1. The definition of intelligence is not fully agreed upon, but may include ‘the ability to learn or understand or to deal with new or trying situations.’ Would it be possible to deal with a new or trying physical situation without embodiment?
2. Hawking had the benefit of more than two decades of full embodiment, including access to all 5+ of his human senses, until ALS began to weaken his physical abilities in his 20s and 30s. Would he have been able to make big discoveries in gravitational and theoretical physics without falling over? Or being able to move pen and paper? Or playing with ball models?
3. All major IQ tests for under 18s include physical object manipulation (like blocks, toys, chips, cards and other manipulatives for fine motor skills of the hands and fingers). For Wechsler this is the WPPSI and WISC. For Stanford-Binet this is the SB-5 and the older Form L-M.
Some further reading for interest:
Paper: The necessity of embodiment (2019, PDF).
LessWrong: Embodiment is Indispensable for AGI (Jun/2022).
What is a median human?
By the way, the median American is much different (Read more via New Strategist on archive.org, 2011, and CNBC, 2018)
The median human in 2024-2025 may meet these dot points:
- A 30-year-old woman from India
- Works as a Product Manager (or in agriculture or medicine)
- Speaks 2 languages
- Will read 700 books in her lifetime
- Can recall roughly 7 items (working memory)
- Average SAT score around 1050/1600 (P50)
- Average IQ around 100 (P50)
- Can make a cup of coffee in a strange kitchen
- Can assemble IKEA furniture
- Cannot build a house
| Ability | GPT-4 (2022) | Gemini (2023) | LLM + Robot (2024) | 2024 H2 model | 2025 model |
|---|---|---|---|---|---|
| Cognitive | |||||
| Works as a Product Manager | ✅ | ✅ | ✅ | ||
| Speaks 2 languages | ✅ | ✅ | ✅ | ||
| Will read 700 books in her lifetime | ✅ | ✅ | ✅ | ||
| Can recall roughly 7 items (working memory) | ✅ | ✅ | ✅ | ||
| Average SAT score around 1050/1600 (P50) | ✅ | ✅ | ✅ | ||
| Average IQ around 100 (P50) | ✅ | ✅ | ✅ | ||
| Truthful: grounded in an accepted version of truth without confabulation or hallucination | ❌ | ❌ | ❌ | ||
| Basic human abilities | |||||
| See: can intepret images with vision | ✅ | ✅ | ✅ | ||
| Hear: can detect tone in language, music | – | ✅ | ✅ | ||
| Taste: can detect flavour | – | ❌ | ❌ | ||
| Touch: can detect temperature, texture, pressure | – | ❌ | ❌ | ||
| Smell: can detect fragrance | – | ❌ | ❌ | ||
| Proprioception: awareness of where body parts are in space | – | ❌ | ✅ | ||
| Embodiment (autonomous; not pre-programmed) | |||||
| Can make a cup of coffee in a strange kitchen | – | – |
❌
|
||
| Can assemble IKEA furniture | – | – |
❌
|
||
Milestones & justifications (most recent at top)
* Thanks to GPT-4 for writing the tiny bit of code that made this table display nicely on small devices.
| Date | Summary | Links |
|---|---|---|
| May/2024 | 74%: GPT-4o: Full multimodal Omnimodel with MMLU=88.7. GPQA=53.6. Note: (Amended) Based on MMMU vision benchmark score and new functionality, GPT-4o represents a minor update to the the AGI countdown. Full explanation. |
OpenAI, ELO rating, Dr Jim Fan analysis |
| May/2024 | 73%: GPT-4 + Unitree Go1 quadruped robot = DrEureka (UPenn, NVIDIA, UT Austin) ‘We trained a robot dog to balance and walk on top of a yoga ball purely in simulation, and then transfer zero-shot to the real world… Frontier LLMs like GPT-4 have tons of built-in physical intuition for friction, damping, stiffness, gravity, etc. We are (mildly) surprised to find that DrEureka can tune these parameters competently and explain its reasoning well.’ | Repo + videos, Twitter, NewAtlas analysis |
| Apr/2024 | 72%: Wu’s Method + AlphaGeometry outperforms gold medalists at IMO Geometry ‘combining AlphaGeometry with Wu’s method we set a new state-of-the-art for automated theorem proving on IMO-AG-30, solving 27 out of 30 problems, the first AI method which outperforms an IMO gold medalist.’ | Paper |
| Apr/2024 | 72%: The Declaration on AI Consciousness & the Bill of Rights for AI. | LifeArchitect.ai |
| Mar/2024 | 72%: Embodiment: Figure 01 + GPT-4V + voice ‘OpenAI models provide high-level visual and language intelligence. Figure neural networks deliver fast, low-level, dexterous robot actions. Everything in this video is a neural network’: |
Video, Source, Explanation by Corey Lynch (Figure, ex-Google) |
| Mar/2024 | 71%: Anthropic Claude 3 Opus. State-of-the-art frontier multimodal model for Mar/2024. Higher performance than GPT-4 across benchmarks. Percentage increases for Claude 3 over GPT-4: MMLU +0.46%, BIG-Bench Hard +4.36%, MATH +12.74%, HumanEval (code) +23.57%. Also has 1M+ context window (researchers only) and upcoming ‘advanced agentic capabilities’. | Announce, Paper (PDF), Models Table |
| Feb/2024 | 70%: OpenAI Sora (‘sky’). Text-to-video diffusion transformer that can ‘understand and simulate the physical world in motion… solve problems that require real-world interaction.’ Two additional considerations:
|
Project page, technical report (html) |
| Feb/2024 | 66%: Google DeepMind Gemini Pro 1.5 sparse MoE. ‘highly compute-efficient multimodal mixture-of-experts model… near-perfect recall on long-context retrieval tasks [1M-10M tokens] across modalities… matches or surpasses Gemini 1.0 Ultra’s state-of-the-art performance across a broad set of benchmarks.’ | Paper (PDF), Models Table |
| Feb/2024 | 65%: Meta AI V-JEPA. ‘physical world model excels at detecting and understanding highly detailed interactions between objects.’ | Announce, paper |
| Feb/2024 | 65%: Google Goose (Gemini) + Google Duckie chatbot: ‘descendant of Gemini… trained on the sum total of 25 years of engineering expertise at Google… can answer questions around Google-specific technologies, write code using internal tech stacks and supports novel capabilities such as editing code based on natural language prompts.’ See also: Rubber duck debugging (wiki). | BI |
| Feb/2024 | 65%: Google DeepMind: OAIF: ‘online AI feedback (OAIF), uses an LLM as annotator… online DPO outperforms RLAIF and RLHF… reduced human annotation effort.’ | Paper |
| Jan/2024 | 65%: Google uses Gemini to fix their code: ‘Instead of a software engineer spending an average of two hours to create each of these commits, the necessary patches are now automatically created in seconds [by Gemini].’ | PDF, The Memo |
| Jan/2024 | 65%: DeepMind AlphaGeometry. Trained using 100% synthetic data, open source, ‘approaching the performance of an average International Mathematical Olympiad (IMO) gold medallist. Notably, AlphaGeometry produces human-readable proofs, solves all geometry problems… under human expert evaluation and discovers a generalized version of a translated IMO theorem…’ – Metaculus prediction of an open-source AI winning IMO Gold Medal in Jan/2028 closer to being achieved. Human crowd-sourced estimates about exponential growth may be becoming irrelevant. – DeepMind CEO Demis: ‘[AlphaGeometry is] Another step on the road to AGI.’ (Twitter) |
Paper, DeepMind blog, Author explanation (video) |
| Jan/2024 | 64%: Embodiment: Figure 01 makes a coffee. ‘Learned this after watching humans make coffee… Video in, trajectories out.’ | |
| Dec/2023 | 64%: DeepMind: LLMs can now produce new maths discoveries and solve real-world problems. DeepMind head of AI for science (14/Dec/2023 Guardian, MIT): ‘this is the first time that a genuine, new scientific discovery has been made by a large language model… It’s not in the training data—it wasn’t even known.’
Paper: ‘the first time a new discovery has been made for challenging open problems in science or mathematics using LLMs. FunSearch discovered new solutions… its solutions could potentially be slotted into a variety of real-world industrial systems to bring swift benefits… the power of these models [tested with Codey PaLM 2 340B] can be harnessed not only to produce new mathematical discoveries, but also to reveal potentially impactful solutions to important real-world problems.’ Sidenote: In Feb/2007, fellow Aussie Prof Terry Tao called the cap set question his ‘favorite open question’. In Jun/2023 Terry also said that LLMs would take another three years to reach this level of progress (‘2026-level AI… will be a trustworthy co-author in mathematical research’). Read more about exponential growth (wiki). |
Paper, explanation |
| Dec/2023 | 61%: Embodiment: Tesla Optimus Gen 2 | Bloomberg |
| Dec/2023 | 61%: LLMs for optimizing hyperparameters. ‘LLMs are a promising tool for improving efficiency in the traditional decision-making problem of hyperparameter optimization.’ | Paper |
| Dec/2023 | 61%: Google Gemini Ultra breaks 90% mark for MMLU. Also has proper multimodality [inputs were text, image, audio, video; outputs are text, image]. For the first time, a large language model has breached the 90% mark on MMLU, designed to be very difficult for AI. Gemini Ultra scored 90.04%; average humans are at 34.5% (AGI) while expert humans are at 89.8% (ASI). GPT-4 was at 86.4%. Watch the Gemini demo video. | Annotated paper, Models Table |
| Nov/2023 | INFO: The Q* maths arch AGI rumor is probably what we in Australia might call a ‘furphy’ (wiki) or a red herring. Here’s ChatGPT lead John Schulman talking about it seven years ago… in 2016. And now, back to our regularly scheduled programming. | YouTube (1h02m 57s) |
| Oct/2023 | 56%: Boston Dynamics: More embodiment using Spot + ChatGPT + LLMs. | YouTube (3m7s) |
| Oct/2023 | INFO: OpenAI CEO: ‘We define AGI as the thing we don’t have quite yet. There were a lot of people who would have—ten years ago [2013 compared to 2023]—said alright, if you can make something like GPT-4, GPT-5, that would have been an AGI… I think we’re getting close enough to whatever that AGI threshold is going to be.’ | WSJ 22/Oct /2023 YouTube (5m25s) |
| Oct/2023 | INFO: Google VP and Fellow Blaise Agüera y Arcas says ‘AGI is already here’: ‘The most important parts of AGI have already been achieved by the current generation of advanced AI large language models… [2023’s] most advanced AI models have many flaws, but decades from now, they will be recognized as the first true examples of artificial general intelligence.’ | NOEMA |
| Oct/2023 | INFO: Even more Gobi/GPT-5 rumors and analysis, Oct/2023. | Reddit (archive) |
| Oct/2023 | 55%: Microsoft: ‘GPT-4 in our proof-of-concept experiments, is capable of writing code that can call itself to improve itself.’ | Paper (arxiv) |
| Sep/2023 | INFO: OpenAI Gobi/GPT-5 rumors and analysis, early rumors from Sep/2023. | Shared Google Doc |
| Sep/2023 | 55%: Harvard studies BCG consultants with GPT-4, ‘Consultants using [GPT-4] AI were significantly more productive (they completed 12.2% more tasks on average, and completed tasks 25.1% more quickly), and produced significantly higher quality results (more than 40% higher quality…)’ | Paper (SSRN) |
| Sep/2023 | 55%: Google OPRO self-improves, ‘prompts optimized by OPRO outperform human-designed prompts by up to 8% on GSM8K [maths], and by up to 50% on Big-Bench Hard [IQ] tasks.’ | Paper (arxiv) |
| Aug/2023 | 54%: GPT-4 scores in 99th percentile for Torrance Tests of Creative Thinking (wiki), questions by Scholastic Testing Service confirmed private/not part of training dataset. | Article |
| Jul/2023 | 54%: Google DeepMind Robotics Transformer RT-2 (3x improvement over RT-1, 2x improvement on unseen scenarios to 62% avg. Progress towards Woz’s AGI coffee test.) | Project page |
| Jul/2023 | 52%: Anthropic Claude 2: More HHH (TruthfulQA Claude 2=0.69 vs GPT-4=0.60) | Anthropic (PDF), Models Table |
| Jul/2023 | 51%: Google DeepMind/ Princeton: Robots that ask for help (‘modeling uncertainty that can complement and scale with the growing capabilities of foundation models.’) | Project page |
| Jul/2023 | 51%: Microsoft LongNet: 1B token sequence length (‘opens up new possibilities for modeling very long sequences, e.g., treating a whole corpus or even the entire Internet as a sequence.’) | Microsoft (arxiv) |
| Jun/2023 | 50%: Google DeepMind RoboCat (‘autonomous improvement loop… RoboCat not only shows signs of cross-task transfer, but also becomes more efficient at adapting to new tasks.’) | DeepMind blog, Paper (PDF) |
| Jun/2023 | 50%: Microsoft introduces monitor-guided decoding (MGD) (‘improves the ability of an LM to… generate identifiers that match the ground truth… improves compilation rates and agreement with ground truth.’) | Paper (arxiv) |
| Jun/2023 | 50%: Ex-OpenAI consultant uses GPT-4 for embodied AI in chemistry (‘instructions, to robot actions, to synthesized molecule.’) | Paper (arxiv), notes |
| Jun/2023 | 50%: Harvard introduces ‘inference-time intervention’ (ITI) (‘At a high level, we first identify a sparse set of attention heads with high linear probing accuracy for truthfulness. Then, during inference, we shift activations along these truth-correlated directions. We repeat the same intervention autoregressively until the whole answer is generated.’) | Harvard (arxiv) |
| Jun/2023 | 49%: Google DeepMind trains an LLM (DIDACT) on iterative code in their 86TB code repository (‘the trained model can be used in a variety of surprising ways… by chaining together multiple predictions to roll out longer activity trajectories… we started with a blank file and asked the model to successively predict what edits would come next until it had written a full code file. The astonishing part is that the model developed code in a step-by-step way that would seem natural to a developer’) | Google Blog, Twitter |
| May/2023 | 49%: Ability Robotics combines an LLM with their humanlike android (robot), Digit. | Agility Robotics (YouTube) |
| May/2023 | 49%: PaLM 2 breaks 90% mark for WinoGrande. For the first time, a large language model has breached the 90% mark on WinoGrande, a ‘more challenging, adversarial’ version of Winograd, designed to be very difficult for AI. Fine-tuned PaLM 2 scored 90.9%; humans are at 94%. | PaLM 2 paper (PDF, Google), Models Table |
| May/2023 | 49%: Robot + text-davinci-003 (‘…we show that LLMs can be directly used off-the-shelf to achieve generalization in robotics, leveraging the powerful summarization capabilities they have learned from vast amounts of text data.’). | Princeton/ Google/ others |
| Apr/2023 | 48%: Boston Dynamics + ChatGPT (‘We integrated ChatGPT with our [Boston Dynamics Spot] robots.’). | Levatas |
| Mar/2023 | 48%: Microsoft introduces TaskMatrix.ai (‘We illustrate how TaskMatrix.AI can perform tasks in the physical world by [LLMs] interacting with robots and IoT devices… All these cases have been implemented in practice… understand the environment with camera API, and transform user instructions to action APIs provided by robots… facilitate the handling of physical work with the assistance of robots and the construction of smart homes by connecting IoT devices…’). | Microsoft (arxiv) |
| Mar/2023 | 48%: OpenAI introduces GPT-4, Microsoft research on record that GPT-4 is ‘early AGI’ (‘Given the breadth and depth of GPT-4’s capabilities, we believe that it could reasonably be viewed as an early (yet still incomplete) version of an artificial general intelligence (AGI) system.’). Microsoft’s deleted original title of the paper was ‘First Contact With an AGI System’. Note that LLMs are still not embodied, and this countdown requires physical embodiment to get to 60%. |
Microsoft Research, Models Table |
| Mar/2023 | 42%: Google introduces PaLM-E 562B (PaLM-Embodied. ‘PaLM-E can successfully plan over multiple stages based on visual and language input… successfully plan a long-horizon task…’). | Google, Models Table |
| Feb/2023 | 41%: Microsoft used ChatGPT in robots, it self-improved (‘we were impressed by ChatGPT’s ability to make localized code improvements using only language feedback.’). | Microsoft |
| Dec/2022 | 39%: Anthropic RL-CAI 52B trained by Reinforcement Learning from AI Feedback (RLAIF) (‘we have moved further away from reliance on human supervision, and closer to the possibility of a self-supervised approach to alignment’). | LifeArchitect.ai, Anthropic paper (PDF), Models Table |
| Jul/2022 | 39%: NVIDIA’s Hopper (H100) circuits designed by AI (‘The latest NVIDIA Hopper GPU architecture has nearly 13,000 instances of AI-designed circuits’). | LifeArchitect.ai, NVIDIA |
| May/2022 | 39%: DeepMind Gato is the first generalist agent, that can ‘play Atari, caption images, chat, stack blocks with a real robot arm, and much more’. | Paper, Watch Alan’s video about Gato, Models Table |
| Jun/2021 | 31%: Google’s TPUv4 circuits designed by AI (‘allowing chip design to be performed by artificial agents with more experience than any human designer. Our method was used to design the next generation of Google’s artificial intelligence (AI) accelerators, and has the potential to save thousands of hours of human effort for each new generation. Finally, we believe that more powerful AI-designed hardware will fuel advances in AI, creating a symbiotic relationship between the two fields’). | LifeArchitect.ai, Nature, Venturebeat |
| Nov/2020 | 30%: GPT-3. Connor Leahy, Co-founder of EleutherAI, re-creator of GPT-2, creator of GPT-J & GPT-NeoX-20B, said about OpenAI GPT-3: ‘I think GPT-3 is artificial general intelligence, AGI. I think GPT-3 is as intelligent as a human. And I think that it is probably more intelligent than a human in a restricted way… in many ways it is more purely intelligent than humans are. I think humans are approximating what GPT-3 is doing, not vice versa.’ | Watch the video (timecode) |
| Aug/2017 | 20%: Google Transformer leads to big changes for search, translation, and language models. | Read the launch in plain English. |
| Earlier | 0 ➜ 10%: Foundational research by Prof Warren McCulloch, Prof Walter Pitts, & Prof Frank Rosenblatt (Perceptron), Dr Alan Turing & Prof John von Neumann (intelligent machinery), Prof Marvin Minsky, Prof John McCarthy, and many others (neural networks and beyond)… | Turing 1948: prepared by ‘Gabriel‘ |
AGI dates predicted based on this table (#predict)
Thanks to Dennis Xiloj. In Dec/2023, using the current milestones and percentages, GPT-4 now says AGI by 26/Jan/2025…
End of year update on #AGI, as usual using data from @dralandthompson conservative countdown to AGI. Are we accelerating? last one predicted april, now its january. pic.twitter.com/On5cYSLEgq
— Dennis Xiloj (@denjohx) December 26, 2023
Older AGI countdown graphs
As requested by @dralandthompson , here is the data updated from https://t.co/5zW33mS4VO, fitted to exponential growth. Seems we will reach AGI in july 2025? pic.twitter.com/Ei4CFwkBVz
— Dennis Xiloj (@denjohx) June 23, 2023
Thanks to The Memo reader BeginningInfluence55 for this more conservative version using polynomial regression. In Jul/2023, using the current milestones and percentages, this method says 100% AGI by Oct/2026…
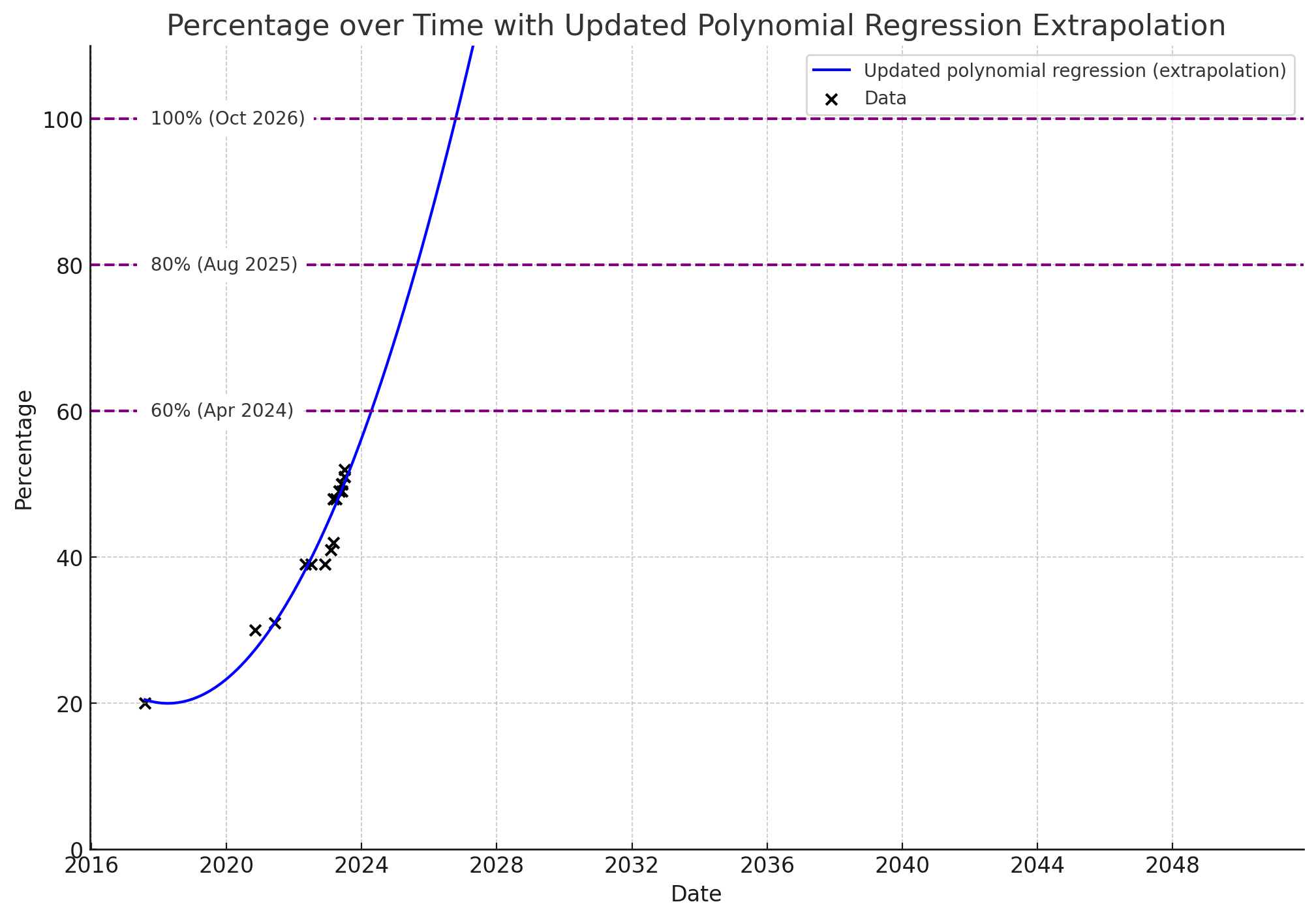
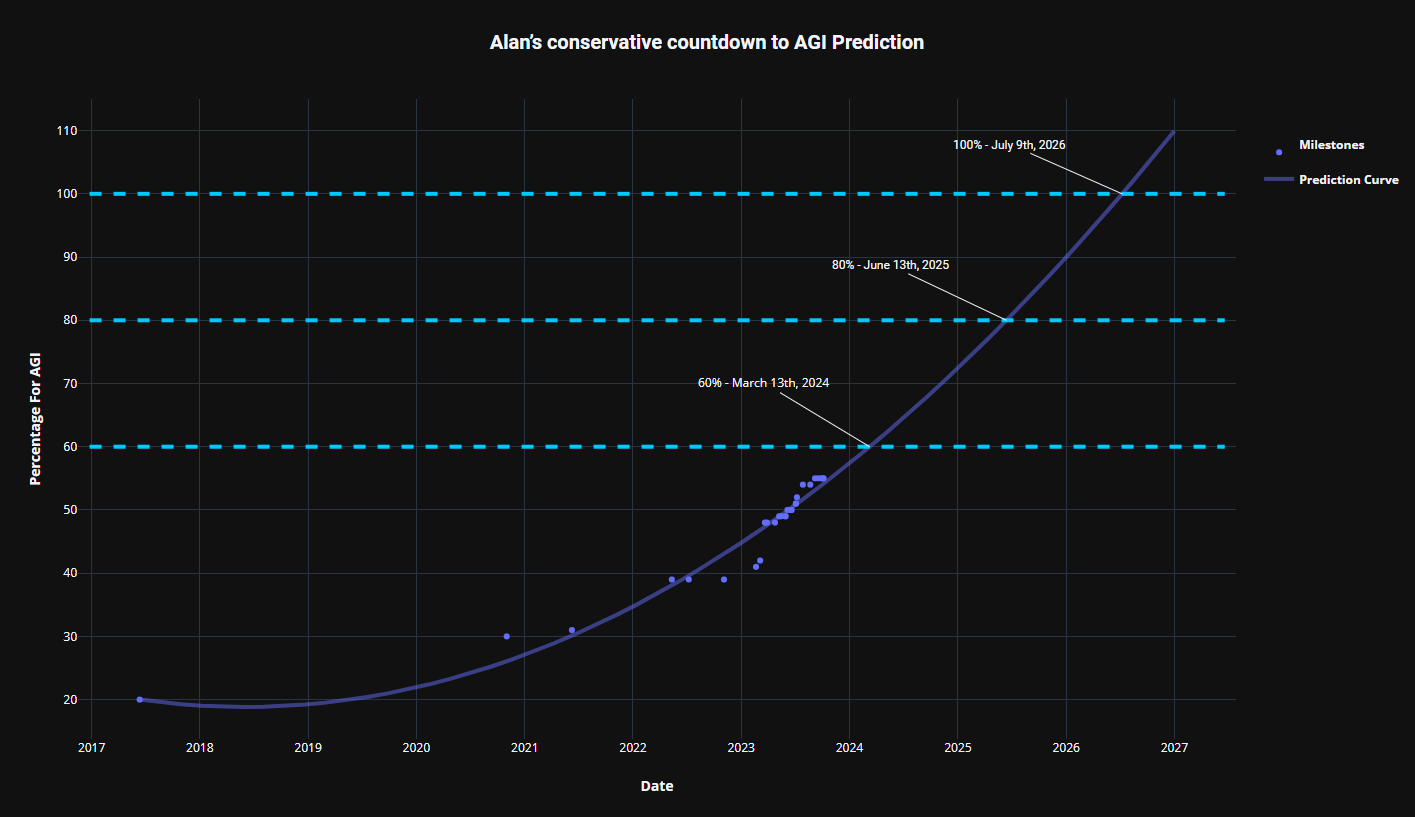
A third analysis was provided by ‘SecretMan’ in Oct/2023, with this chart showing 100% AGI by Jul/2026…
Next milestones
– Around 50%: HHH: Helpful, honest, harmless as articulated by Anthropic, with a focus on groundedness and truthfulness. Mustafa Suleyman is the Co-founder of DeepMind, and Founder of Inflection AI (pi.ai), and says: ‘LLM hallucinations will be largely eliminated by 2025’.
LLM hallucinations will be largely eliminated by 2025.
that’s a huge deal. the implications are far more profound than the threat of the models getting things a bit wrong today.
— Mustafa Suleyman (@mustafasuleyman) June 9, 2023
– Around 60%: Physical embodiment backed by a large language model. The AI is autonomous, and can move and manipulate. Current options include:
- OpenAI’s 1X (formerly Halodi Robotics) EVE (wheeled) and NEO (bipedal).
- Sanctuary AI Phoenix.
- Agility Digit.
- Figure 01.
- Tesla Bot.
- Microsoft Autonomous Systems and Robotics Group.
- Google Robotics including the 2023 consolidation of Everyday Robots.
- …and more.

See related page: Humanoid robots ready for LLMs.
– Around 80%: Passes Steve Wozniak’s test of AGI: can walk into a strange house, navigate available tools, and make a cup of coffee from scratch (video with timecode).
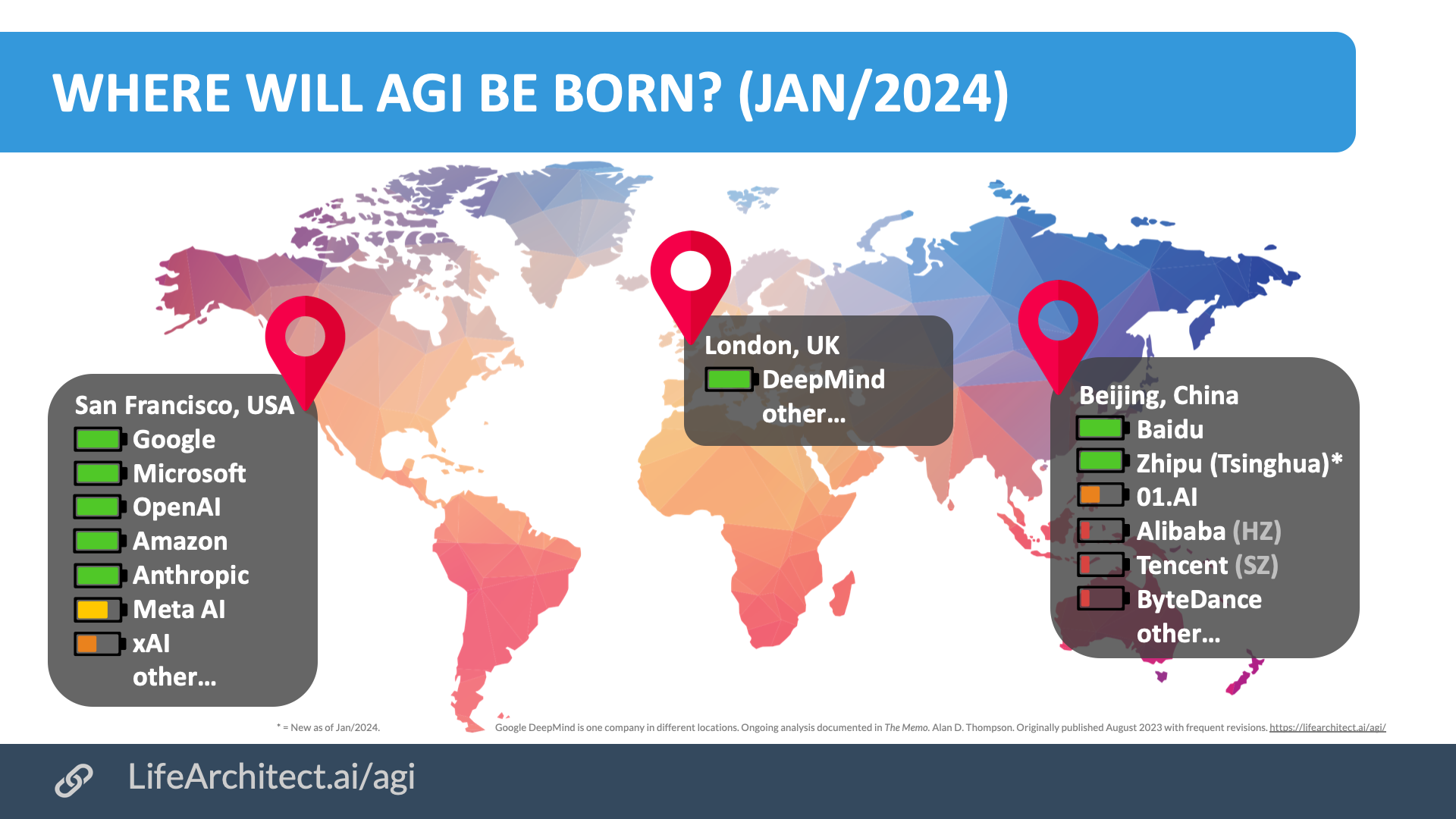
Where will AGI be born?
Viz updated 24/Jan/2024
 Download PDF
Download PDF
 Download source (PDF)
Download source (PDF)
Permissions: Yes, you can use these visualizations anywhere, please leave the citation intact.
Related videos
Dr Demis Hassabis, Google DeepMind founder, former child prodigy:
Suddenly the nature of money even changes… I don’t know if company constructs would even be the right thing to think about… We don’t want to have to wait till the eve before AGI happens… we should be preparing for that now. (24/Feb/2024)
Get The Memo
by Dr Alan D. Thompson · Be inside the lightning-fast AI revolution.Bestseller. 10,000+ readers from 142 countries. Microsoft, Tesla, Google...
Artificial intelligence that matters, as it happens, in plain English.
Get The Memo.
 Dr Alan D. Thompson is an AI expert and consultant, advising Fortune 500s and governments on post-2020 large language models. His work on artificial intelligence has been featured at NYU, with Microsoft AI and Google AI teams, at the University of Oxford’s 2021 debate on AI Ethics, and in the Leta AI (GPT-3) experiments viewed more than 4.5 million times. A contributor to the fields of human intelligence and peak performance, he has held positions as chairman for Mensa International, consultant to GE and Warner Bros, and memberships with the IEEE and IET. Technical highlights.
Dr Alan D. Thompson is an AI expert and consultant, advising Fortune 500s and governments on post-2020 large language models. His work on artificial intelligence has been featured at NYU, with Microsoft AI and Google AI teams, at the University of Oxford’s 2021 debate on AI Ethics, and in the Leta AI (GPT-3) experiments viewed more than 4.5 million times. A contributor to the fields of human intelligence and peak performance, he has held positions as chairman for Mensa International, consultant to GE and Warner Bros, and memberships with the IEEE and IET. Technical highlights.This page last updated: 18/May/2024. https://lifearchitect.ai/agi/↑





